19年 面试
答应别人的东西, 一定要准时反馈;
1. 自我介绍, 总共做过几年java , 公司介绍, 最近两年项目介绍,使用或接触过的技术介绍, 目前在职主要做哪些方面的工作;
2. 项目中数据库层面如何设计的?
3. 项目中涉及多线程如何处理的?
4. app做的是用html5 + 一些vue , mui, 阿拉丁的一些js 融合的框架, 做的嵌套开发,不是原生页面, 做的是插件, 是放在别人的app平台进行部署。
5. 数据锁方面有涉及么?
共享锁下其它用户可以并发读取,查询数据。但不能增删改数据和资源共享,加了共享锁可以继续加共享锁,不能加排他锁;
排他锁下不能加其他锁,排他锁内可以读写, 其他用户只能等当前用户锁释放掉后,才能读写;
共享锁只用于表级, 使用lock命令 ,排他锁用于行级 ,使用for update;
解锁需要dba的权限,找到当前锁的sid, 然后kill掉即可。
6. 后台框架用的什么?
Spring+springmvc+mybatis 框架 , Dubbo, zookeeper, maven, log4j, redis , 常用的一些设计模式思想要记, socket , rocketmq , quartz , ESB, webservice
7. springmvc这块熟悉么?
8. spring的哪些地方用到了哪些设计模式, 你能说出来一些么?
简单工厂(例如在配置文件中定义一个bean),
单例模式(可以在xml中指定使用单例还是每次new新的实例),
适配器,
观察者模式(监听器的实现),
策略模式(定义不同算法,根据不同客户需求调用不同方法),
模板方法(jdbc连接池这块,将变化的东西集中写在一个地方,然后通过传入回调给模板对象,即完成调用),
9. aop, ioc 分别代表什么意思?
AOP切面编程, 实现原理是基于动态代理实现的。动态代理相当于中转,所有客户端的请求,我可以集中到一份方法进行处理,可以根据我自己的处理逻辑控制是否进行转接, 也相当于增强,在实际调用的过程中,顺带执行点其他任务 ;使用场景:安全校验,事务,权限管理,日志等。
Ioc 控制反转,xml中bean的注入, 我们需要的对象不需要自己手动去new了,全都交给spring容器进行管理,用到什么直接从spring中取就行了。
10. aop 用到了什么设计模式呢?
动态代理模式
11. ioc用到了什么设计模式呢?
依赖注入模式
单例模式
代理模式
工厂模式
模板方法模式
12. 代理模式了解过么? aop有没有用到代理模式呢?
了解过, 为某个对象提供一个代理,来控制对这个对象的直接访问, aop使用的是jdk的动态代理, 提供前置增强,后置增强或过程中增强;
13. spring 通常有一些配置, 都有哪些?
Bean的定义, 静态文件过滤, 上传下载文件配置,数据库连接池配置,事务配置,持久层配置,外包文件引入, 常用注解, 缓存配置:@AspectJ(注解切面, @EnableAspectJAutoProxy注解开启Spring对AspectJ代理的支持), xml中可配置bean是否单例模式使用,自定义监听器, 自定义拦截器, @Import(导入配置项), @Scheduled(配置定时任务),事务注解@Transactional
14. 事务配置用的多么?
用过, xml中引入tx标签,定义事务; 项目service层使用@Transactional注解,实现事务操作,可声明只读或写; 使用拦截器配置事务;xml中定义bean, 装配spring的事务类,通过属性赋值,实现事务配置;
15. spring中有两大块, aop, ioc , 主要用到的技术层面有哪些?
单例模式,代理模式,模板方法,工厂模式等
16. 反射你是怎么理解的?
反射,jvm在类的编译加载过程中,将对应的类,属性登记在册,然后反射通过在类加载运行过程中,通过对应的类的名称或者他的一个实例对象,去找对应这个类的所有方法和属性,如果明确知道哪个方法,还可以通过传参来执行这个方法。
17. aop的应用场景有哪些?
事务,安全验证,日志, 权限管理, 拦截过滤等。
18. aop常用的注解有哪些?
@Aspect(配置切面)
@Before(前置增强,都会执行)
@After(后置增强,都会执行)
@AfterReturning(后置增强,目标方法执行成功后才会执行)
@AfterThrowing(后置增强, 抛出异常后会执行)
@Around(环绕增强, 相当于前置增强和后置目标方法执行成功后会执行)
@annotation(可以指定切面执行时,只要有请求就可以执行,不用指定具体的代码层级)
19. oracle常用的一些函数有哪些?
Concat: 字符串拼接, 或者 ||
Instr: 指定字符串位置
Length: 长度
Trim: 去空格
Lower: 小写
Upper:大写
Nvl: 判断空
Replace: 替换
Substr: 截取
Floor: 向下取整
To_number:
To_char:
To_date:
Decode: 判断函数等等
20. sql调优的话,你了解有哪些?
创建索引
避免在索引上使用计算
使用预编译查询(使用参数化sql, 因为数据库可以预编译,下次执行速度更快)
调整Where字句中的连接顺序
尽量将多条SQL语句压缩到一句SQL中
用where字句替换HAVING字句
使用表的别名(并把别名放在列名上)
用union all替换union
考虑使用“临时表”暂存中间结果(这样每次查询就避免扫描主表)
查询select语句优化(不要使用select * )
20. 索引创建原则? 哪些情况不会走索引?
对于查询频率高的字段创建索引
索引的数目不宜太多
选择唯一性索引
尽量使用列数据量少的索引
尽量使用前缀来索引
删除不再使用或者很少使用的索引
select *,可能会导致不走索引
索引列上存在null值,可能不能走索引
索引列上有函数运算,导致不走索引
隐式类型转换导致不走索引
!=或者<>(不等于),可能导致不走索引
使用like, in 等, 可能导致不走索引
21. 乐观锁和悲观锁介绍?区别主要是什么?
乐观锁适用于写比较少的情况下(多读场景);
一般多写的场景下用悲观锁就比较合适(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)
22. 常用的集合类有哪些? 如何我想插入数据块的话,用哪个list?
大类有iterator, collection , map ,array
Iterator包括: ListIterator,
Collection包括: list, set, linkedlist, arraylist,hashset, linkedhashset, treeset(使用二叉树排序), sortedset
Map包括: hashmap, ConcurrentHashMap , treemap , sortedmap
自定义集合内部排序,需要实现comparable 接口
23. hashmap的原理? 存储原理和排序原理? jdk8 和 7对于hashmap有哪些区别? 存储方式是以键值对存储的,怎么根据key找到对应的值的? map中有两个hash值是一样的, 怎么找到对应的value 或者key ?
存储的方式是键值对,底层是数组和链表的形式存在,实现类是Entry
总结:HashMap的实现原理:
利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
Jdk7,8的区别: jdk8添加了红黑树,在元素个数超过8个才会使用, jdk7中有一个内部类Entry, jdk8使用的是Node类, 使用hashmap要注意如果key存储的是对象,则一定要重新hashcode和equal方法
Map先根据key的hash值到table数组中找对应的下标,获取对应的entry, 如果一个位置存在多个entry,那么hash值肯定也是相等的,遍历所有entry, 去比较entry的key值,如果与传递过来的key值相等,则返回entry对应的value值, 最后都没有找到则返回null
24. 创建线程有几种方式? 线程启动用的哪个方法? 为什么不用run 而用start?
创建线程有4种方式:
实现runnable接口, 继承thread类, 使用线程池Executor,实现callable通过创建FutureTask类对象,这个可以自定义返回类型。
Run方法是普通的方法,有方法体,如果使用run方法,程序需要一步一步走完,才能执行下一个方法,就达不到多线程的目的,使用start方法,将线程放在等待开始调用队列中,等待cpu去调度,jvm去运行。
25. liunx常用操作命令介绍?
Less, cat, ll , la, grep , tail , curl, vi, top, telnet , rm –rf , scop , mkdir , mv , pwd ,
26. 工作这几年,有没有让你印象比较深刻的事情,或者让你比较自豪的事情?
印象深刻:有一天凌晨4点,是我做的一个年检项目关联系统上线,需要做止付和解止付接口验证操作,需要生产上通过调用我的接口验证他们的功能上线是否成功, 把我留在公司一整宿,验证完没有问题,系统验证搞得我很紧张,还担心自己的功能出问题,结果一夜很精神,就直接在公司打代码到早上上班,这是我第一次通宵在公司打代码到第二天早上上班。
比较自豪:18年初,后端架构升级到微服务开发部署,前端架构改造使用新的框架vue, 后端是我自己看着api文档一步步搭建起来的,各个组件拆分部署也是自己弄的, 另外新架构那时候刚开始引入git, vue, 10几个java开发,还都是我最先用起来,并且抽空给他们开会做过几次技术培训。而且现在我在项目中不管是开发问题查找,业务需求还是环境,部署问题,基本上每天都有2,3个人来找我咨询。
27. 有没有做过性能调优方面的东西?
Sql优化,jvm参数调优,java代码性能调优
做过:
1.不要直接将项目整体做优化,要有确切的定位哪些确实需要优化,哪些不需要优化;
2.检查需要优化的代码部分,使用分析器来定位性能瓶颈在哪些地方;
3.经常定义一些日志在关键的地方,用来定位分析性能卡顿的代码,并且分析性能瓶颈;
4.尽量使用基本类型来代替使用包装类型;
5.避免使用bigInteger, bigDecimal 因为占用内存太高;
6.使用日志前,判断当前日志级别是否能被显示;
7.尽可能使用缓存来来避免执行耗时或频繁使用的代码片段;
8.慎用线程同步的方法;
9.尽量使用局部变量,因为局部变量保存在栈中,方法结束就会被gc清理,速度也快, 而类变量保存在堆中,耗费内存,访问也慢;
10.创建集合尽量指定一个初始大小;
11.尽量在适合的场合使用单例,例如数据共享,资源并发访问等;
28. 有没有做过压测? 压测tps比较低的话,通常有哪些方法可以去调?有没有通过工具去查找分析他性能瓶颈的地方?
有做过;
tps比较低的话, 找几个地方进行分析:1. 网络带宽限制;2.连接池大小资源限制(例如tomcat与数据库连接池大小限制,超过则等待);3. 数据库sql性能影响;4.硬件资源限制(内存,cpu等);5. 业务逻辑较为复杂;6. 缓存策略或配置等;7. Java编码方式问题;
使用过jmeter开多并发来测试过;
29. 你了解架构方面么?
了解;
架构搭建部署有几个点需要注意:
整体敏捷度,组件拆分合理性;部署方面,模块之间耦合度; 单元测试是否方便;性能方面;开发便捷性和代码重用性;
30. 比如行内新出一个需求,要做设计,出方案,这块有没有做过?
做过,最近刚做了一个小鹰助手的需求设计方案;
31. 懂技术架构,懂性能调优?
32. 设计模式的思想介绍:
开闭原则:开闭原则就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码。
针对接口编程,真对接口编程,依赖于抽象而不依赖于具体。
尽量使用合成/聚合的方式,而不是使用继承。
一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立。
使用多个隔离的接口,比使用单个接口要好。
里氏代换原则:(1)子类的能力必须大于等于父类,即父类可以使用的方法,子类都可以使用。(2)返回值也是同样的道理。假设一个父类方法返回一个List,子类返回一个ArrayList,这当然可以。如果父类方法返回一个ArrayList,子类返回一个List,就说不通了。这里子类返回值的能力是比父类小的。(3)还有抛出异常的情况。任何子类方法可以声明抛出父类方法声明异常的子类。
而不能声明抛出父类没有声明的异常
33. 同步锁的几种方式?
synchronized
1.使用synchronized修饰方法实现同步机制;
2.使用volatile修饰变量实现线程同步;
3.使用阻塞队列实现线程同步;
34. es简单介绍?
35. redis简单介绍?
36. springboot 面试题相关?
37. logback相关?
38. hbase简单介绍?
39. 高并发的情况,说出你的解决方案?
40. jvm内部的一些原理? 堆和栈的区别?
41. 二分算法介绍? 红黑树? 二叉树? 冒泡排序?
42. hashcode, equal 的重写?
重写equals ,也要重写hashcode,
Equals相等,则hashcode也相等;
43.cglib 动态代理介绍?为什么比jdk动态代理高效?
jdk通过发射的方式来调用
cglib 通过继承类的方式来调用,为代理类和被代理类各生成一个class,并且分配一个index方法,通过index方法直接定位要执行的方法进行调用,不用反射调用,所以效率比较高一点。
44. 面试的时候讲的高端一些?
45. 平常开发测试人少访问量,性能看不出来,但是一到生产,就会很慢,很卡,生产上如何进行分析,性能出现在哪地方的问题? 分析工具常用 的有哪些?
1. 生产上的话, 通过观察日志,
2. 使用性能分析工具, 与eclipse集成的几款工具,profile, jConsole, 使用cat监控工具
46. sql性能如何分析?
通过任务计划观察索引执行情况
47. 高并发解决方案或者分析方案? Jmeter, loadrunner 做性能测试, 各有什么特点,如何进行分析?
使用乐观锁,队列 , 和增加版本号来控制高并发提交数据
48. 自己有没有做过压测,如何做的?
1. 使用jmeter工具,模拟高并发请求,观察tps
2. 或者自己使用多线程模拟高并发来观察接口压力情况
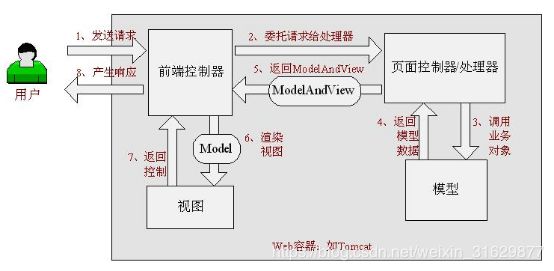
49. spring和springmvc 有什么区别?
spring提供了一整套流程处理,包括业务层,数据层,事务支持等,并且提供了两大核心功能aop(面向切面,可以用来解决一些公共问题)和ioc(bean的创建和注入简化并便于维护),
Springmvc主要作为控制层来实现,从请求到controller,业务处理完成后,返回视图和数据给客户端。
2)springmvc的流程:
1、 用户发送请求至前端控制器DispatcherServlet;
2、DispatcherServlet收到请求调用HandlerMapping处理器映射器;
3、处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet;
4、DispatcherServlet通过HandlerAdapter处理器适配器调用处理器,执行处理器(Controller,也叫后端控制器);
5、Controller执行完成返回ModelAndView,并返回给HandlerAdapter,HandlerAdapter将结果返回给DispatcherServlet;
6、DispatcherServlet将ModelAndView传给ViewReslover视图解析器,ViewReslover解析后返回具体View给DispatcherServlet;
7、DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)后返回给给客户
50. 什么是分布式架构?有没有做过分布式系统? 分布式系统中如何实现数据共享和服务器中间通信? 链表结构有没有了解过?
1. 将相同的应用组件部署多份,
2. 业务拆分多个模块,分别部署
链表结构,可比喻为火车,每个链表都是一节车厢,数据存储在车厢中, 而每个火车节都有一个指针,连接着下一个火车节。
51. 服务端,系统之间调用的话,如果访问量很大或者调用很频繁的话, 系统资源就会消耗很大?
服务端通信有几种方式:
socket方式通信,短连接(通信完立马断掉),长连接(同步和异步方式)
mq方式同步或者通信
Webervice方式
Redis发布订阅
52. rocketMq 架构介绍? 如何保证mq数据不丢失和数据重复问题?
Name Server 为 producer 和 consumer 提供路由信息;
Broker 接收来自生产者的消息,储存以及为消费者拉取消息的请求做好准备;
生产者(Producer);
消费者(Consumer);
2). 首先从生产者方面考虑,每条消息发送成功与否都会有一个状态对应,如果失败状态,则重发一遍即可。并且还可以日志来查询是否发送并成功存储进boker块当中;
3)从broker块分析,消息支持持久化到日志里面,即使宕机重启,未读消息还是可以加载出来,而且broker支持主从同步,使得消息也不会丢失;
4)从消费者角度考虑,消费者自身维护一个持久化的offset,标记已经成功消费或者消费失败时,发给broker的消息下标,如果消费失败,并且borker挂掉了,那么消费者会定时重试发送动作,如果消费者和broker一起挂了, 那么重启后,会继续从拉去offset之前的消息到本地。
a) mq有发送日志记录,每条发送消息都有对应的消息id, 他发送给消费者时会自动判断并去重, 还有就是可以自己在业务端处理重复问题。
53. redis常见面试题? Redis持久化?
持久化,就是把数据写到内存中;
Redis支持数据类型: list , hash , set , zset , String ;
Redis有一种通讯协议RESP,可以实现客户端于服务端通信, 类型websocket ;
Redis有几种架构部署模式:
单机模式: 搭建简单,内存容量有限,无法扩容
集群模式:节点之间通过数据共享,
哨兵模式:通过间隔时间监听master节点,出现master节点不可用时,会通过投票选举新的master, 节点直接数据也是通过master同步到各个节点,master写压力比较大
主从复制:有一个master主节点,多个slave从节点,数据更新的话, master都会同步到slave从节点,用来保证数据一致,无法保证高可用,master写压力比较大
54. 组合索引, 只有一列条件,会不会走索引?
如果这一列是组合索引的第一个字段的话, 会走索引,不是则不走
55.hashmap 和 concurrentmap 有什么区别?
一个是线程安全,一个不是线程安全的, 因为concurrentmap使用了分段锁,将map数据分成一段一段存储,然后给每一段数据加上一把锁,就实现了高并发。
56. map底层的链表是用来做什么的?
链表存储的是Entry泛型接口, 包含key, value 以及next(指向下一个entry对象元素)
57. 乐观锁,悲观锁有什么区别?
乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检查,(通过对比版本号,查询的时候会带一个数据库版本号,更新的时候用来做对比)
悲观锁, 每次它去拿数据的时候都会上锁,知道锁释放,别人才能操作,不适用于高并发
58. 重写equal时, 一定要重写hashcode, 因为比较相等时基于hashcode实现的,
59. final修饰对象, 修饰方法,修饰类,变量?
final修饰类是不能被继承;
final修饰对象不能在被创建;
fianl修饰方法不能在子类中被覆盖;
final修饰变量,称为常量,初始化以后不能改变值。
60.equal如何比较两个对象相等的? == 又是如何比较的?
equals 通常用来比较两个对象的内容是否相等, ‘’ 通常用来比较两个对象的地址是否相等
equals默认等同于‘’
如果判断一个类或对象是否相等, 如果没有重写equals方法,则判断方式就按照‘==’判断
61.java注入bean有哪几种方式?
Javabean注入有两种方式: 构造函数注入,set/get方式注入
Spring注入bean有如下几种方式:
Xml注入;使用注解@Autowired; 使用java方式注入;通过构建applicationContext对象方式注入
62.Bean 注入循环如何解决?
Spring的ioc容器会进行检查,如果是通过xml中通过set属性注入, 对于不是propertype属性注入的bean,spring可以提前缓存创建的bean,如果存在就直接使用。
63.Mybatis有遇到什么技术难点?
其实也没有什么技术难点,基本遇到的问题都能及时解决,例如sql中<,> 号,sql结尾加了;,没有写#号等等, 都能根据报错提示很快定位并进行修正。
64.Mybatis 都用过哪些插件? 简单介绍下如何使用的?
Mybatis-generators 自动生成dao,xml,bean的反向生成插件
Mybatis-plugins 自动关联dao,xml文件,并可以检测属性值是否错误
Mybatis-pagehelper 分页插件, 是通过spring的aop实现的,可以在执行sql的时候,把相关数据在执行一遍, 将当前表作为临时表,预编译sql之后执行
65.Aop如何实现事务的?
Aop方式可以在xml配置中体现出来,通过配置增强来实现事务的配置;
但是还有一种比较方便的配置方式,在xml中配置一行代码tx:annotation-driven , 然后在要实现事务的方法上添加@transaction注解,
事务回滚的情况,超时,抛异常都会导致事务回滚
66.如何根据key值找到map数组的下标? Map底层是数组存储,那么数组的下标和扩容是如何做的?如何判断不会超出?
首先存储的时候,根据key值通过散列算法得出对应的下标,算法会尽可能随机均匀的将数据分布在每个数组下,而扩容时根据对应的算法进行实现。
https://www.cnblogs.com/williamjie/p/9358291.html
67.线程的wait, sleep 方法是干什么用的?
sleep方法:
属于Thread类中的方法;会导致程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持着,当指定时间到了之后,又会自动恢复运行状态;在调用sleep方法的过程中,线程不会释放对象锁。(只会让出CPU,不会导致锁行为的改变)
wait方法:
属于Object类中的方法;在调用wait方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify方法后本线程才进入对象锁定池准备。获取对象锁进入运行状态。(不仅让出CPU,还释放已经占有的同步资源锁)
68.线程使用wait之前, 线程都干了什么?
添加同步锁,wait则是释放当前同步锁,并让出cpu资源
https://my.oschina.net/HerrySun/blog/714156
69.那么wait 和notify,是和什么配合使用的?
Synchronized
70.Java线程同步有哪几种方式? lock与synchronized的区别?
1.使用volitail,
2.使用wait , nofity,
3.使用synchronized,
4.使用ThreadLocal线程变量
----------------------------------------------------------------------
1.首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
2.synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
3.synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
4.用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
5.synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可)
6.Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
71.Java类加载过程?
Jvm将.java文件编译成…class文件,然后通过classloader类加载器将类信息加载到虚拟机内存中,在使用的时候在去创建这个对象。
72.多线程高并发做过么?
高并发: 高并发是一种状态,如果大量请求访问网关接口。这种情况会发生大量执行操作,如数据库操作、资源请求、硬件占用等。这就需要对接口进行优化,而多线程是处理高并发的一种手段
多线程:是一种异步处理的一种方式,在同一时刻最大限度的利用计算机资源
73.微服务了解么?
微服务架构系统是一个分布式系统,按照业务划分不同的组件或应用,可以独立部署和使用
74.多线程里面的参数都有哪些? 分别代表什么意思?
核心线程数,最大线程数,线程存活时间,线程队列
比如去火车站买票, 有10个售票窗口, 但只有5个窗口对外开放. 那么对外开放的5个窗口称为核心线程数, 而最大线程数是10个窗口.如果5个窗口都被占用, 那么后来的人就必须在后面排队, 但后来售票厅人越来越多, 已经人满为患, 就类似于线程队列已满.这时候火车站站长下令, 把剩下的5个窗口也打开, 也就是目前已经有10个窗口同时运行. 后来又来了一批人,10个窗口也处理不过来了, 而且售票厅人已经满了, 这时候站长就下令封锁入口,不允许其他人再进来, 这就是线程异常处理策略.而线程存活时间指的是, 允许售票员休息的最长时间, 以此限制售票员偷懒的行为.
75.ThreadLocal有用过么?
将私有线程和该线程存放的副本对象做一个映射,各个线程变量之间互不影响,不共享数据,线程安全,一般存储为静态类型,可以在其他地方进行调用
76.Java异常有那几大类?Java异常类一般怎么抛出的?你是如何处理OutOfMemoryError异常的?
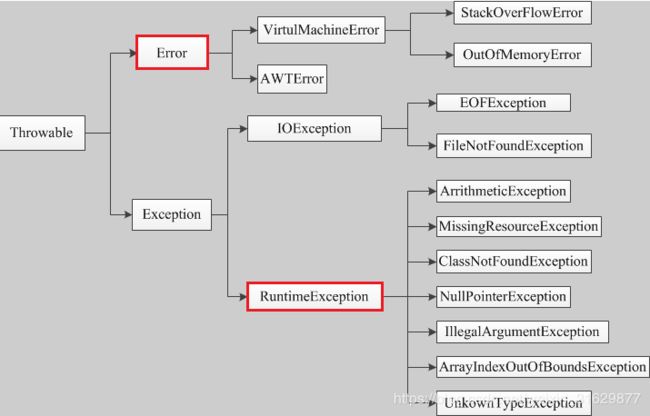
非检查异常:Error 和 RuntimeException 以及他们的子类;这样的异常多半是代码写的有问题, 数组越界,强制类型转换等。
检查异常:除了Error 和 RuntimeException 以及他们的子类之外的异常;程序本身运行环境中出现的异常,需要使用try … catch扑捉。
内存溢出博文:http://outofmemory.cn/c/java-outOfMemoryError
导致OutOfMemoryError异常的常见原因有以下几种:
内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
代码中存在死循环或循环产生过多重复的对象实体;
使用的第三方软件中的BUG;
启动参数内存值设定的过小
错误常见的错误提示:
tomcat:java.lang.OutOfMemoryError: PermGen space
tomcat:java.lang.OutOfMemoryError: Java heap space
weblogic:Root cause of ServletException java.lang.OutOfMemoryError
resin:java.lang.OutOfMemoryError
java:java.lang.OutOfMemoryError
需要重点排查以下几点:
检查代码中是否有死循环或递归调用。
检查是否有大循环重复产生新对象实体。
检查对数据库查询中,是否有一次获得全部数据的查询。一般来说,如果一次取十万条记录到内存,就可能引起内存溢出。这个问题比较隐蔽,在上线前,数据库中数据较少,不容易出问题,上线后,数据库中数据多了,一次查询就有可能引起内存溢出。因此对于数据库查询尽量采用分页的方式查询。
检查List、MAP等集合对象是否有使用完后,未清除的问题。List、MAP等集合对象会始终存有对对象的引用,使得这些对象不能被GC回收。
77.Jira插件有用过么?
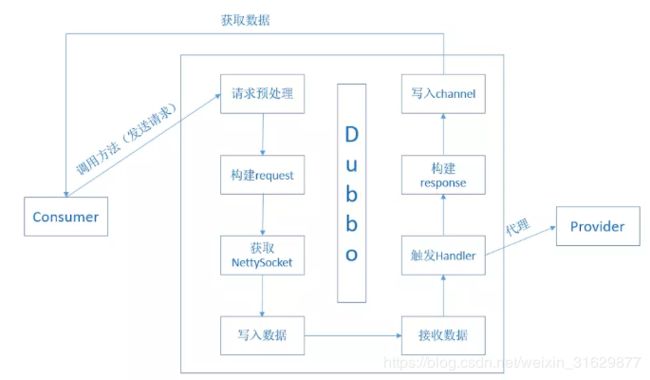
78.Dubbo简单介绍下,另外项目中有用过么? 怎么用的?
Dubbo的使用方式:
(1)导入dubbo、zookeeper依赖
(2)在服务提供者端,编写服务接口,服务接口的实现类,编写配置文件
(3)修改web.xml读取配置文件
(4)在服务消费者,即客户端,调用服务接口,调用服务实现类,编写配置文件
这样系统间就可以互相通信,从而感觉像在本地使用一样。
调用流程:
· 服务容器负责启动,加载,运行服务提供者。
· 服务提供者在启动时,向注册中心注册自己提供的服务。
· 服务消费者在启动时,向注册中心订阅自己所需的服务。
· 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
· 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
· 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
79.介绍下常用的数据结构?
枚举(Enumeration)
位集合(BitSet)
向量(Vector)
栈(Stack)
字典(Dictionary)
哈希表(Hashtable)
属性(Properties)
数组array
链表linkedList
Collection
Map
80.分布式事务介绍下?
简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。