Kubernetes 架构及部署、调度、状态管理流程简介
全文首发在个人博客上:Kubernetes 架构及部署、调度、状态管理流程简介_
Kubernetes简称k8s,是用于自动部署、扩展和管理“容器化应用程序”的开源系统。该系统由Google设计并捐赠给Cloud Native Computing Foundation来使用。 它旨在提供“跨主机集群的自动部署、扩展以及运行应用程序容器的平台”。 它支持一系列容器工具,包括Docker等。它是当前绝对主流的容器管理平台。目前阿里(ACK)、字节( Gödel )、美团(LAR)内部的资源管理系统都基于k8s。
K8s 架构
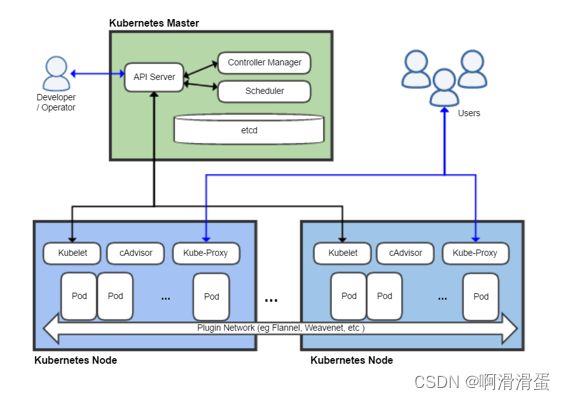
K8s中的一些重要组件的简介如下:
- Etcd:基于Raft的分布式键值存储系统,保存了整个集群的状态。
- Pod:集群中运行部署服务的最小单元,一个Pod可由多个Docker及网络、存储组件组成。
- API Server:所有资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
- Controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- Scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- Kubelet:负责维护节点内的Pods和他们上面的容器,同时也负责Volume(CVI)和网络(CNI)的管理;
- Kube-Proxy:负责为 Service 提供 cluster 内部的服务发现和负载均衡
Etcd
Etcd主要用于保存集群所有的网络配置和对象的状态信息。整个 Kubernetes 系统中一共有两个服务需要用到 etcd 用来协同和存储配置,分别是:
- 网络插件 flannel、对于其它网络插件也需要用到 etcd 存储网络的配置信息
- Kubernetes 本身,包括各种对象的状态和元信息配置
Etcd是基于Raft的分布式键值存储系统,可以查考我之前的关于Raft的文章。
我们在安装 Flannel 的时候配置了 FLANNEL_ETCD_PREFIX=“/kube-centos/network” 参数,这是 Flannel 查询 etcd 的目录地址。
查看 Etcd 中存储的 flannel 网络信息:
$ etcdctl --ca-file=/etc/kubernetes/ssl/ca.pem --cert-file=/etc/kubernetes/ssl/kubernetes.pem --key-file=/etc/kubernetes/ssl/kubernetes-key.pem ls /kube-centos/network -r
2018-01-19 18:38:22.768145 I | warning: ignoring ServerName for user-provided CA for backwards compatibility is deprecated
/kube-centos/network/config
/kube-centos/network/subnets
/kube-centos/network/subnets/172.30.31.0-24
/kube-centos/network/subnets/172.30.20.0-24
/kube-centos/network/subnets/172.30.23.0-24
```查看 flannel 的配置:```bash
$ etcdctl --ca-file=/etc/kubernetes/ssl/ca.pem --cert-file=/etc/kubernetes/ssl/kubernetes.pem --key-file=/etc/kubernetes/ssl/kubernetes-key.pem get /kube-centos/network/config
2018-01-19 18:38:22.768145 I | warning: ignoring ServerName for user-provided CA for backwards compatibility is deprecated
{"Network": "172.30.0.0/16", "SubnetLen": 24, "Backend": { "Type": "host-gw"} }
Kubernetes 使用 etcd v3 的 API 操作 etcd 中的数据。所有的资源对象都保存在 /registry 路径下,如下:
ThirdPartyResourceData
apiextensions.k8s.io
apiregistration.k8s.io
certificatesigningrequests
clusterrolebindings
clusterroles
configmaps
controllerrevisions
controllers
daemonsets
deployments
events
horizontalpodautoscalers
ingress
limitranges
minions
monitoring.coreos.com
namespaces
persistentvolumeclaims
persistentvolumes
poddisruptionbudgets
pods
ranges
replicasets
resourcequotas
rolebindings
roles
secrets
serviceaccounts
services
statefulsets
storageclasses
thirdpartyresources
如果你还创建了 CRD(自定义资源定义),则在此会出现 CRD 的 API。
API Server
API Server是K8s的核心组件之一,它类似于linux系统中的系统调用。一个核心的API设计原则是所有的API都应该是声明式的,即用户只需要告诉K8s自己想要的状态,而不需要告诉K8s如何去做。例如告诉K8s我需要3个Pod的副本,K8s会自动去创建这3个Pod的副本,而不去告诉K8s我要再新建一个副本,因为API是有可能被丢弃或者重复执行的,但是声明式的API是幂等的,即重复执行的结果是一样的。
Pod
Pod 是 Kubernetes 中最小的调度单元,它是一个或多个容器的集合(目前K8s也支持了其他类型的虚拟化产品),同时也可以在Pod中包含存储、网络配置等共享资源。Pod 是 Kubernetes 中的原子调度单位,Kubernetes 会将 Pod 中的容器一起调度到同一个节点上,确保它们能够正常运行。
目前 Kubernetes 中的业务主要可以分为长期伺服型(long-running)、批处理型(batch)、节点后台支撑型(node-daemon)和有状态应用型(stateful application);分别对应的小机器人控制器为 Deployment、Job、DaemonSet 和 StatefulSet
Controller manager
Controller Manager 就是集群内部的管理控制中心,由负责不同资源的多个 Controller 构成,共同负责集群内的 Node、Pod 等所有资源的管理,比如当通过 Deployment 创建的某个 Pod 发生异常退出时,RS Controller 便会接受并处理该退出事件,并创建新的 Pod 来维持预期副本数。
几乎每种特定资源都有特定的 Controller 维护管理以保持预期状态,而 Controller Manager 的职责便是把所有的 Controller 聚合起来:
- 提供基础设施降低 Controller 的实现复杂度
- 启动和维持 Controller 的正常运行
Kubernetes 中常见的几种类型的 Controller有如下这些:
- Replication Controller 用于确保在集群中始终运行指定数量的 Pod 实例。如果由于某种原因导致 Pod 实例数低于预期值,Replication Controller 会自动启动新的 Pod 实例,以满足配置的副本数目。
- ReplicaSet 是 Replication Controller 的升级版本,它支持更灵活的 Pod 选择方式,并提供了更强大的标签选择器功能。在新的 Kubernetes 集群中,建议使用 ReplicaSet 而不是 Replication Controller,它一般不单独使用,而是作为 Deployment 的理想状态参数使用。
- Deployment 用于管理应用程序的发布和更新。它可以创建 ReplicaSet,并在需要时启动新的 Pod 实例,以确保应用程序的副本数量符合所需的状态。Deployment 还支持滚动更新、版本回滚等功能,使得应用程序的部署和更新变得更加灵活和可控。
- StatefulSet 用于管理有状态应用程序的部署,例如数据库。与 ReplicaSet 不同,StatefulSet 会为每个 Pod 实例分配稳定的网络标识符和持久化存储,确保在 Pod 重启或迁移时能够保持状态。
- DaemonSet 用于在集群中的每个节点上运行一个副本(或者根据节点标签进行选择)。它通常用于部署一些系统级别的后台服务,如日志收集器、监控代理等。
- Job 用于一次性任务的管理,例如批处理作业。CronJob 则是定时任务的管理器,它可以周期性地执行指定的任务,类似于 Linux 系统中的 cron 任务。
Scheduler
kube-scheduler 是 Kubernetes 的调度器,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将 Pod 调度到最优的工作节点上面去,从而更加合理、更加充分的利用集群的资源。
它的调度流程可以看下面的K8s调度流程:里的内容。
值得注意的是,由于K8s原生的调度器是只支持一个一个单独调度,所以对于批处理作业调度的场景不受用,例如需要gang调度,即需要同时多个Pod一起上台才能运行,这时一个个调度就有死锁以及浪费资源的问题,所以目前K8s社区退出了Volcano调度器,值得去关注一下。
Kubelet
Kubelet 是 Kubernetes 集群中每个节点上的代理,负责维护容器的生命周期,同时与容器运行时(如 Docker)进行交互,确保容器正常运行。Kubelet 会定期从 API Server 获取 Pod 的配置信息,然后创建和管理 Pod 中的容器,同时监控容器的状态,并上报给 API Server。
Kube-Proxy
Kube-proxy 是 kubernetes 工作节点上的一个网络代理组件,运行在每个节点上。Kube-proxy维护节点上的网络规则,实现了Kubernetes Service 概念的一部分 。它的作用是使发往 Service 的流量(通过ClusterIP和端口)负载均衡到正确的后端Pod。
kube-proxy 监听 API server 中 资源对象的变化情况,包括以下三种:
- service
- endpoint/endpointslices
- node
然后根据监听资源变化操作代理后端来为服务配置负载均衡。
K8s 部署流程
在 Kubernetes 中,一个控制器至少追踪一种类型的 Kubernetes 资源。这些资源对象有一个代表期望状态的 spec 字段。 该资源的控制器负责所属对象当前状态接近期望状态,如下是一个部署nginx的例子:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3 # 副本数量
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest # Docker版本
ports:
- containerPort: 80
resources:
requests:
cpu: "100m" # 请求 100 毫核 CPU
memory: "128Mi" # 请求 128 兆字节内存
limits:
cpu: "200m" # 最大限制 200 毫核 CPU
memory: "256Mi" # 最大限制 256 兆字节内存
控制器需要保证所属对象一直处于期望状态,但是这就有一个问题,如何探测到变化。因为如何持续通过API Server去查询Etcd中资源的状态,会导致API Server的压力过大,所以K8s采用了Informer的机制。具体如下:
- 提前Cache住Etcd中的内容,减少API Server调用。使用 Informer 实例的 Lister() 方法, List/Get Kubernetes 中的 Object 时,Informer 不会去请求 Kubernetes API,而是直接查找缓存在本地内存中的数据,依赖Etcd的List&Watch机制,客户端及时获知这些对象的状态变化,然后更新本地缓存,这样就在客户端为这些API对象维护了一份和Etcd数据库中几乎一致的数据,然后控制器等客户端就可以直接访问缓存获取对象的信息,而不用去直接访问apiserver。通过这种方式,Informer 既可以更快地返回结果,又能减少对 Kubernetes API 的直接调用。
- Watch机制及时通知变化。Informer 通过 Kubernetes Watch API 监听某种 resource 下的所有事件。Watch API 本质上就是一种 APIServer 主动向控制器等客户端推送 Kubernetes 资源修改、创建的一种机制。这样我们就可以获取到资源的变更,及时更新对象状态。
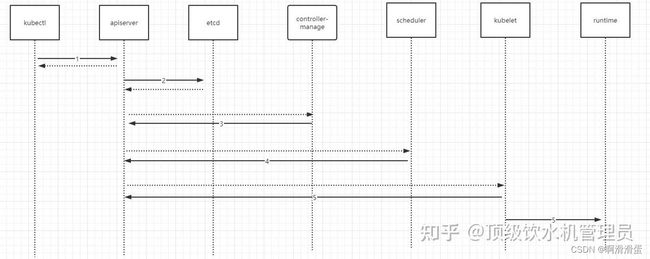
如上图所示,K8s的部署流程主要分为以下几个步骤:
- kubectl向apiserver发送部署请求(例如使用 kubectl create -f deployment.yml)
- apiserver将 Deployment 持久化到etcd;etcd与apiserver进行一次http通信。
- controller manager通过watch api监听 apiserver ,deployment controller看到了一个新创建的deplayment对象更后,将其从队列中拉出,根据deployment的描述创建一个ReplicaSet并将 ReplicaSet 对象返回apiserver并持久化回etcd。以此类推,当replicaset控制器看到新创建的replicaset对象,将其从队列中拉出,根据描述创建pod对象。
- 接着scheduler调度器看到未调度的pod对象,根据调度规则选择一个可调度的节点,加载到pod描述中nodeName字段,并将pod对象返回apiserver并写入etcd。
- kubelet在看到有pod对象中nodeName字段属于本节点,将其从队列中拉出,通过容器运行时创建pod中描述的容器。
K8s 调度流程
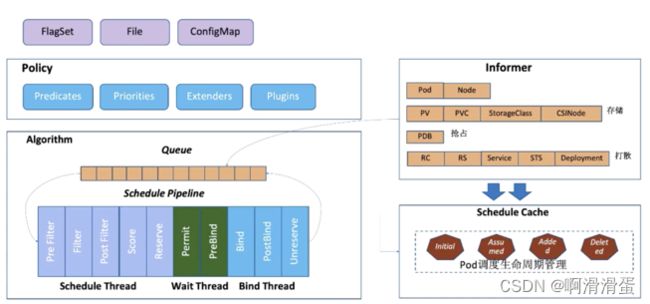
Scheduler 的调度策略启动配置目前支持三种方式,配置文件 / 命令行参数 / ConfigMap。调度策略可以配置指定调度主流程中要用哪些过滤器 (Predicates)、打分器 (Priorities) 、外部扩展的调度器 (Extenders),以及最新支持的 SchedulerFramwork 的自定义扩展点 (Plugins)。
Scheduler 在启动的时候通过 K8s 的 informer 机制以 List+Watch 从 kube-apiserver 及时感知获取调度需要的数据例如:Pods、Nodes、Persistant Volume(PV), Persistant Volume Claim(PVC) 等等,并将这些数据做一定的预处理作为调度器的的 Cache。
通过 Informer 将需要调度的 Pod 插入 Queue 中,Pipeline 会循环从 Queue Pop 等待调度的 Pod 放入 Pipeline 执行。调度流水线 (Schedule Pipeline) 主要有三个阶段。
在Scheduler Thread阶段,对Pod一个个串行调度,流程为 Filter -> Score -> Reserve:
- Filter:筛选出符合 Pod Spec 描述的 Nodes
- Score:对筛选出的 Nodes 进行打分和排序
- Reserve:将Pod调度到得分最高的Node中,并更新自己的NodeCache
在Wait Thread(异步并行)阶段:等待 Pod 关联的资源的就绪。例如等待 PVC 的 PV 创建成功,或者 Gang 调度中等待关联的 Pod 调度成功等等。
在Bind Thread(异步并行)阶段:将 Pod 和 Node 的关联持久化 Kube APIServer,如果失败则重新调度。
K8s 状态管理
K8s中对Node节点的状态管理主要有两种方式,一种是通过Lease(租约)的方式,一种是通过NodeStatus上报的方式。
节点中的kubelet通过Lease更新维持存活状态(2019年 k8s v1.17 正式加入)。具体来说,每个节点有一个lease对象,各节点的kubelet定期更新自己的lease对象(默认10s一次),每次更新的内容较少,比较轻量。如果没有及时收到更新,就可以怀疑Node损坏,开始进一步处理。
同时kubelet也会定期(默认10秒)计算一次NodeStatus(时间独立计算),只有发生有意义的变化或者不上报持续时间超过了参数node-status-update-period(默认5m)时,kubelet才上报NodeStatus。NodeStatus上报数据大,一般包含节点的资源状态、运行的Pod信息、节点Ip、节点版本等。
注意Lease机制的提出主要是为了解决大规模场景下频繁进行大型NodeStatus上报导致的性能问题,同时也可以更快的发现节点的异常。
参考资料
- Kubernetes 架构
- Kubernetes Controller Manager 工作原理
- Volcano
- 一文看懂 Kubelet
- 一文看懂 Kube-proxy
- K8s deployment部署一个pod的流程
- 从零开始入门 K8s | 调度器的调度流程和算法介绍
- kubelet上报心跳机制