阅读目录:
- 准备工作
- 搭建 RabbitMQ Server 单机版
- RabbitMQ Server 高可用集群相关概念
- 搭建 RabbitMQ Server 高可用集群
- 搭建 HAProxy 负载均衡
因为公司测试服务器暂不能用,只能在自己电脑上重新搭建一下 RabbitMQ Server 高可用集群,正好把这个过程记录下来,以便日后查看。
公司测试服务器上的 RabbitMQ 集群,我搭建的是三台服务器,因为自己电脑空间有限,这边只能搭建两台服务器用作高可用集群,用的是 Vagrant 虚拟机管理工具。
环境介绍:
| RabbitMQ | 节点 | IP 地址 | 工作模式 |
|---|---|---|---|
| node1 | 192.168.1.50 | DISK | CentOS 7.0 - 64位 |
| node2 | 192.168.1.51 | DISK | CentOS 7.0 - 64位 |
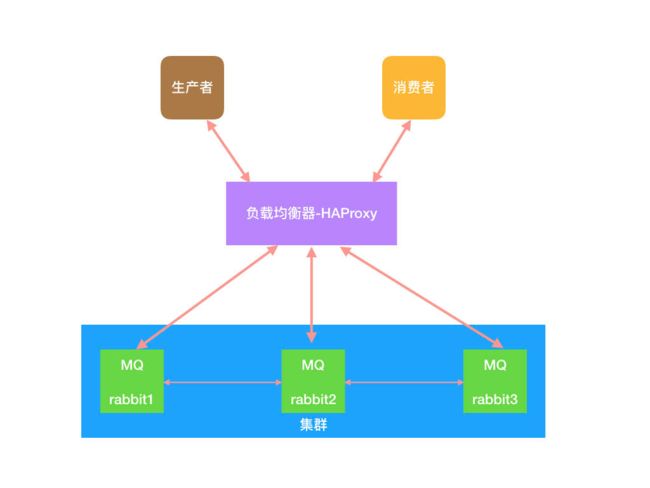
整体架构:
1. 准备工作
首先,在node1服务器上,修改vi /etc/hostname:
node1在node2服务器上,修改vi /etc/hostname:
node2然后在node1服务器上,修改vi /etc/hosts:
node1 192.168.1.50
node2 192.168.1.51
127.0.0.1 node1
::1 node1在node2服务器上,修改vi /etc/hosts:
192.168.1.50 node1
192.168.1.51 node2
127.0.0.1 node2
::1 node2然后查看下hostnamectl status,如果不正确的话,需要再进行设置下:
[root@node1 ~]# hostnamectl status
Static hostname: node1
Icon name: computer-vm
Chassis: vm
Machine ID: 241163503ce842c489360d0a48a606fc
Boot ID: cdb59c025cb447e3afed7317af78979e
Virtualization: oracle
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-229.el7.x86_64
Architecture: x86_64
[root@node1 ~]# hostnamectl --static set-hostname node1为了后面我们安装的顺利,我们最好再配置一下代理:
[root@node1 ~]# export http_proxy=http://192.168.1.44:1087;export https_proxy=http://192.168.1.44:1087;
[root@node1 ~]# curl ip.cn
当前 IP:104.245.13.31 来自:美国 Linost2. 搭建 RabbitMQ Server 单机版
下面以node1服务器做演示示例。
首先,更新软件包和存储库:
[root@node1 ~]# yum -y update然后安装 Erlang(RabbitMQ 运行需要 Erlang 环境):
[root@node1 ~]# vi /etc/yum.repos.d/rabbitmq-erlang.repo
[root@node1 ~]# [rabbitmq-erlang]
name=rabbitmq-erlang
baseurl=https://dl.bintray.com/rabbitmq/rpm/erlang/20/el/7
gpgcheck=1
gpgkey=https://dl.bintray.com/rabbitmq/Keys/rabbitmq-release-signing-key.asc
repo_gpgcheck=0
enabled=1
[root@node1 ~]# yum -y install erlang socat然后安装 RabbitMQ Server:
[root@node1 ~]# mkdir -p ~/download && cd ~/download
[root@node1 download]# wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.10/rabbitmq-server-3.6.10-1.el7.noarch.rpm
[root@node1 download]# rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
[root@node1 download]# rpm -Uvh rabbitmq-server-3.6.10-1.el7.noarch.rpm卸载 RabbitMQ 命令:
[root@node1 ~]# rpm -e rabbitmq-server-3.6.10-1.el7.noarch
[root@node1 ~]# rm -rf /var/lib/rabbitmq/ //清除rabbitmq配置文件安装好之后,就可以启动 RabbitMQ Server 了:
[root@node1 download]# systemctl start rabbitmq-server也可以添加到系统服务中启动:
[root@node1 download]# systemctl enable rabbitmq-server
Created symlink from /etc/systemd/system/multi-user.target.wants/rabbitmq-server.service to /usr/lib/systemd/system/rabbitmq-server.service.启动成功之后,我们可以查看下 RabbitMQ Server 的状态:
[root@node1 download]# systemctl status rabbitmq-server
● rabbitmq-server.service - RabbitMQ broker
Loaded: loaded (/usr/lib/systemd/system/rabbitmq-server.service; disabled)
Active: active (running) since 五 2018-04-27 04:44:31 CEST; 3min 27s ago
Process: 17216 ExecStop=/usr/sbin/rabbitmqctl stop (code=exited, status=0/SUCCESS)
Main PID: 17368 (beam.smp)
Status: "Initialized"
CGroup: /system.slice/rabbitmq-server.service
├─17368 /usr/lib64/erlang/erts-9.3/bin/beam.smp -W w -A 64 -P 1048576 -t 5000000 -stbt db -zdbbl 32000 -K true -- -root /usr/lib64/erlang -progname erl -- -home /var/lib/rabbitmq -- -pa /usr...
├─17521 /usr/lib64/erlang/erts-9.3/bin/epmd -daemon
├─17655 erl_child_setup 1024
├─17675 inet_gethost 4
└─17676 inet_gethost 4
4月 27 04:44:30 node1 rabbitmq-server[17368]: RabbitMQ 3.6.10. Copyright (C) 2007-2017 Pivotal Software, Inc.
4月 27 04:44:30 node1 rabbitmq-server[17368]: ## ## Licensed under the MPL. See http://www.rabbitmq.com/
4月 27 04:44:30 node1 rabbitmq-server[17368]: ## ##
4月 27 04:44:30 node1 rabbitmq-server[17368]: ########## Logs: /var/log/rabbitmq/[email protected]
4月 27 04:44:30 node1 rabbitmq-server[17368]: ###### ## /var/log/rabbitmq/[email protected]
4月 27 04:44:30 node1 rabbitmq-server[17368]: ##########
4月 27 04:44:30 node1 rabbitmq-server[17368]: Starting broker...
4月 27 04:44:31 node1 rabbitmq-server[17368]: systemd unit for activation check: "rabbitmq-server.service"
4月 27 04:44:31 node1 systemd[1]: Started RabbitMQ broker.
4月 27 04:44:31 node1 rabbitmq-server[17368]: completed with 0 plugins.
[root@node1 download]# systemctl enable rabbitmq-server
ln -s '/usr/lib/systemd/system/rabbitmq-server.service' '/etc/systemd/system/multi-user.target.wants/rabbitmq-server.service'然后启动 RabbitMQ Web 管理控制台:
[root@node1 download]# rabbitmq-plugins enable rabbitmq_management
The following plugins have been enabled:
amqp_client
cowlib
cowboy
rabbitmq_web_dispatch
rabbitmq_management_agent
rabbitmq_management
Applying plugin configuration to rabbit@node1... started 6 plugins.RabbitMQ Server 默认guest用户,只能localhost地址访问,我们还需要创建管理用户:
[root@node1 download]# rabbitmqctl add_user admin admin123 &&
rabbitmqctl set_user_tags admin administrator &&
rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"然后添加防火墙运行访问的端口:
[root@node1 download]# firewall-cmd --zone=public --permanent --add-port=4369/tcp &&
firewall-cmd --zone=public --permanent --add-port=25672/tcp &&
firewall-cmd --zone=public --permanent --add-port=5671-5672/tcp &&
firewall-cmd --zone=public --permanent --add-port=15672/tcp &&
firewall-cmd --zone=public --permanent --add-port=61613-61614/tcp &&
firewall-cmd --zone=public --permanent --add-port=1883/tcp &&
firewall-cmd --zone=public --permanent --add-port=8883/tcp
success重新启动防火墙:
[root@node1 download]# firewall-cmd --reload
success上面这些做完了,RabbitMQ 单机版的部署也完成了,我们可以浏览器访问``:
将上面的搭建过程,在node2服务器上,再做重复一边。
3. RabbitMQ Server 高可用集群相关概念
设计集群的目的
- 允许消费者和生产者在 RabbitMQ 节点崩溃的情况下继续运行。
- 通过增加更多的节点来扩展消息通信的吞吐量。
集群配置方式
- cluster:不支持跨网段,用于同一个网段内的局域网;可以随意的动态增加或者减少;节点之间需要运行相同版本的 RabbitMQ 和 Erlang。
- federation:应用于广域网,允许单台服务器上的交换机或队列接收发布到另一台服务器上交换机或队列的消息,可以是单独机器或集群。federation 队列类似于单向点对点连接,消息会在联盟队列之间转发任意次,直到被消费者接受。通常使用 federation 来连接 internet 上的中间服务器,用作订阅分发消息或工作队列。
- shovel:连接方式与 federation 的连接方式类似,但它工作在更低层次。可以应用于广域网。
节点类型
- RAM node:内存节点将所有的队列、交换机、绑定、用户、权限和 vhost 的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
- Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启 RabbitMQ 的时候,丢失系统的配置信息。
问题说明:RabbitMQ 要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。
解决方案:设置两个磁盘节点,至少有一个是可用的,可以保存元数据的更改。
Erlang Cookie
Erlang Cookie 是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的 Erlang Cookie。具体的目录存放在/var/lib/rabbitmq/.erlang.cookie。
说明:这就要从 rabbitmqctl 命令的工作原理说起,RabbitMQ 底层是通过 Erlang 架构来实现的,所以 rabbitmqctl 会启动 Erlang 节点,并基于 Erlang 节点来使用 Erlang 系统连接 RabbitMQ 节点,在连接过程中需要正确的 Erlang Cookie 和节点名称,Erlang 节点通过交换 Erlang Cookie 以获得认证。
镜像队列
RabbitMQ 的 Cluster 集群模式一般分为两种,普通模式和镜像模式。
- 普通模式:默认的集群模式,以两个节点(rabbit01、rabbit02)为例来进行说明。对于 Queue 来说,消息实体只存在于其中一个节点 rabbit01(或者 rabbit02),rabbit01 和 rabbit02 两个节点仅有相同的元数据,即队列的结构。当消息进入 rabbit01 节点的 Queue 后,consumer 从 rabbit02 节点消费时,RabbitMQ 会临时在 rabbit01、rabbit02 间进行消息传输,把 A 中的消息实体取出并经过 B 发送给 consumer。所以 consumer 应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理 Queue。否则无论 consumer 连 rabbit01 或 rabbit02,出口总在 rabbit01,会产生瓶颈。当 rabbit01 节点故障后,rabbit02 节点无法取到 rabbit01 节点中还未消费的消息实体。如果做了消息持久化,那么得等 rabbit01 节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
- 镜像模式:将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现 RabbitMQ 的 HA 高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在 consumer 消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽。
镜像队列实现了 RabbitMQ 的高可用性(HA),具体的实现策略如下所示:
| ha-mode | ha-params | 功能 |
|---|---|---|
| all | 空 | 镜像队列将会在整个集群中复制。当一个新的节点加入后,也会在这 个节点上复制一份。 |
| exactly | count | 镜像队列将会在集群上复制 count 份。如果集群数量少于 count 时候,队列会复制到所有节点上。如果大于 Count 集群,有一个节点 crash 后,新进入节点也不会做新的镜像。 |
| nodes | node name | 镜像队列会在 node name 中复制。如果这个名称不是集群中的一个,这不会触发错误。如果在这个 node list 中没有一个节点在线,那么这个 queue 会被声明在 client 连接的节点。 |
实例列举:
queue_args("x-ha-policy":"all") //定义字典来设置额外的队列声明参数
channel.queue_declare(queue="hello-queue",argument=queue_args)如果需要设定特定的节点(以rabbit@localhost为例),再添加一个参数:
queue_args("x-ha-policy":"nodes",
"x-ha-policy-params":["rabbit@localhost"])
channel.queue_declare(queue="hello-queue",argument=queue_args)可以通过命令行查看那个主节点进行了同步:
$ rabbitmqctl list_queue name slave_pids synchronised_slave_pids以上内容主要参考:RabbitMQ 分布式集群架构
4. 搭建 RabbitMQ Server 高可用集群
理解了上面的概念之后,我们再搭建 RabbitMQ Server 高可用集群,就非常容易了。
默认.erlang.cookie文件是隐藏的,ls命令并不能查看,你也可以手动搜索下文件:
[root@node1 ~]# find / -name ".erlang.cookie"
/var/lib/rabbitmq/.erlang.cookie
[root@node1 ~]# cat /var/lib/rabbitmq/.erlang.cookie
LBOTELUJAMXDMIXNTZMB将node1服务器中的.erlang.cookie文件,拷贝到node2服务器上:
[root@node1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@node2:/var/lib/rabbitmq先停止运行节点,然后以后台方式启动 RabbitMQ Server(node1和node2分别执行):
[root@node1 ~]# rabbitmqctl stop
[root@node1 ~]# rabbitmq-server -detached然后我们以node1作为集群中心,在node2上执行加入集群中心命令(节点类型为磁盘节点):
[root@node1 ~]# rabbitmqctl stop_app
[root@node1 ~]# rabbitmqctl reset
[root@node1 ~]# rabbitmqctl join_cluster rabbit@node1
//默认是磁盘节点,如果是内存节点的话,需要加--ram参数
[root@node1 ~]# rabbitmqctl start_app查看集群的状态(包含node1和node2节点):
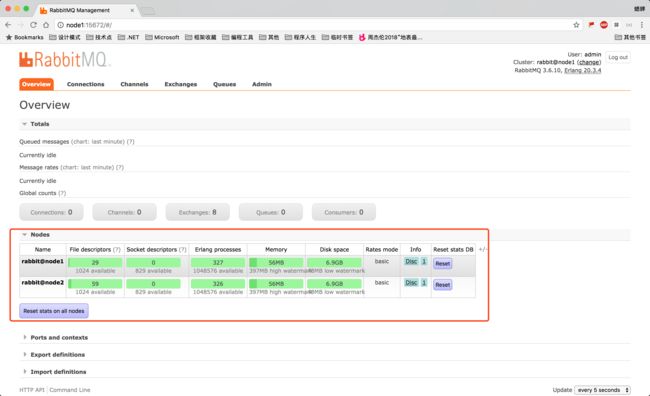
[root@node1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node1
[{nodes,[{disc,[rabbit@node1,rabbit@node2]}]},
{running_nodes,[rabbit@node2,rabbit@node1]},
{cluster_name,<<"rabbit@node1">>},
{partitions,[]},
{alarms,[{rabbit@node2,[]},{rabbit@node1,[]}]}]我们可以从 RabbitMQ Web 管理界面,看到集群的信息:
5. 搭建 HAProxy 负载均衡
HAProxy 是一个免费的负载均衡软件,可以运行于大部分主流的 Linux 操作系统上。
HAProxy 提供了 L4(TCP) 和 L7(HTTP) 两种负载均衡能力,具备丰富的功能。HAProxy 的社区非常活跃,版本更新快速(最新稳定版 1.7.2 于 2017/01/13 推出)。最关键的是,HAProxy 具备媲美商用负载均衡器的性能和稳定性。它当前不仅仅是免费负载均衡软件的首选,更几乎成为了唯一选择。
因为 RabbitMQ 本身不提供负载均衡,下面我们就搭建 HAProxy,用作 RabbitMQ 集群的负载均衡。
HAProxy 安装在node1服务器上,安装命令:
[root@node1 ~]# rpm -ivh http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-5.noarch.rpm//
[root@node1 ~]# yum -y install haproxy配置 HAProxy:
[root@node1 ~]# cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
[root@node1 ~]# vi /etc/haproxy/haproxy.cfg将下面的配置添加到/etc/haproxy/haproxy.cfg文件中:
global
log 127.0.0.1 local0 info
log 127.0.0.1 local1 notice
daemon
maxconn 4096
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option abortonclose
maxconn 4096
timeout connect 5000ms
timeout client 3000ms
timeout server 3000ms
balance roundrobin
listen private_monitoring
bind 0.0.0.0:8100
mode http
option httplog
stats refresh 5s
stats uri /stats
stats realm Haproxy
stats auth admin:admin
listen rabbitmq_admin
bind 0.0.0.0:8102
server node1 node1:15672
server node2 node2:15672
listen rabbitmq_cluster
bind 0.0.0.0:8101
mode tcp
option tcplog
balance roundrobin
timeout client 3h
timeout server 3h
server node1 node1:5672 check inter 5000 rise 2 fall 3
server node2 node2:5672 check inter 5000 rise 2 fall 3然后启动 HAProxy:
[root@node1 ~]# haproxy -f /etc/haproxy/haproxy.cfg外部访问的话,需要关闭下防火墙:
[root@node1 ~]# systemctl disable firewalld.service
rm '/etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service'
rm '/etc/systemd/system/basic.target.wants/firewalld.service'
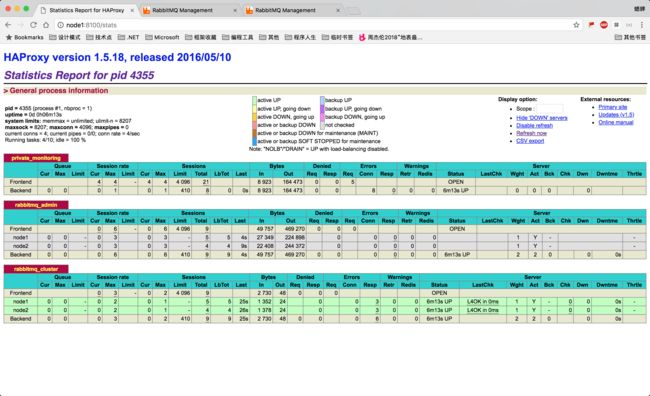
[root@node1 ~]# systemctl stop firewalld.serviceHAProxy 配置了三个地址:
http://node1:8100/stats:HAProxy 负载均衡信息地址,账号密码:admin/admin。http://node1:8101:RabbitMQ Server Web 管理界面(基于负载均衡)。http://node1:8102:RabbitMQ Server 服务地址(基于负载均衡)。
通过访问http://node1:8100/stats,查看 HAProxy 负载均衡信息:
参考资料:
- 如何在CentOS 7上安装RabbitMQ服务器(有点坑,要结合下面文章中的命令)
- Centos 6 通过 yum 安装 Rabbitmq
- RabbitMQ集群安装
- RabbitMQ分布式集群架构(推荐)
- RabbitMQ 分布式设置和高可用性讨论
- RabbitMQ 高可用集群