自然语言处理中的自注意力机制(Self-attention Mechanism)
近年来,注意力(Attention)机制被广泛应用到基于深度学习的自然语言处理(NLP)各个任务中,之前我对早期注意力机制进行过一些学习总结(可见http://www.cnblogs.com/robert-dlut/p/5952032.html)。随着注意力机制的深入研究,各式各样的attention被研究者们提出。在2017年6月google机器翻译团队在arXiv上放出的《Attention is all you need》论文受到了大家广泛关注,自注意力(self-attention)机制开始成为神经网络attention的研究热点,在各个任务上也取得了不错的效果。本人就这篇论文中的self-attention以及一些相关工作进行了学习总结(其中也参考借鉴了张俊林博士的博客"深度学习中的注意力机制(2017版)"和苏剑林的"《Attention is All You Need》浅读(简介+代码)"),和大家一起分享。
1 背景知识
Attention机制最早是在视觉图像领域提出来的,应该是在九几年思想就提出来了,但是真正火起来应该算是2014年google mind团队的这篇论文《Recurrent Models of Visual Attention》,他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将attention机制应用到NLP领域中。接着attention机制被广泛应用在基于RNN/CNN等神经网络模型的各种NLP任务中。2017年,google机器翻译团队发表的《Attention is all you need》中大量使用了自注意力(self-attention)机制来学习文本表示。自注意力机制也成为了大家近期的研究热点,并在各种NLP任务上进行探索。下图维attention研究进展的大概趋势。

Attention机制的本质来自于人类视觉注意力机制。人们视觉在感知东西的时候一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当人们发现一个场景经常在某部分出现自己想观察的东西时,人们会进行学习在将来再出现类似场景时把注意力放到该部分上。

下面我先介绍一下在NLP中常用attention的计算方法(里面借鉴了张俊林博士"深度学习中的注意力机制(2017版)"里的一些图)。Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射,如下图。
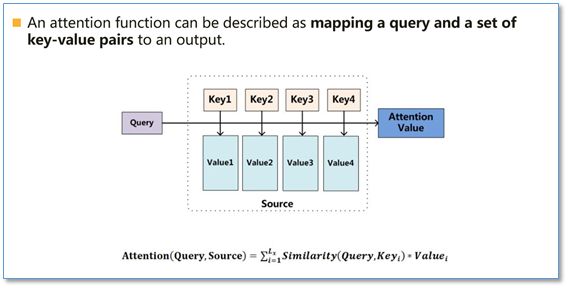
在计算attention时主要分为三步,第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;然后第二步一般是使用一个softmax函数对这些权重进行归一化;最后将权重和相应的键值value进行加权求和得到最后的attention。目前在NLP研究中,key和value常常都是同一个,即key=value。

2 Attention is all you need[1]
接下来我将介绍《Attention is all you need》这篇论文。这篇论文是google机器翻译团队在2017年6月放在arXiv上,最后发表在2017年nips上,到目前为止google学术显示引用量为119,可见也是受到了大家广泛关注和应用。这篇论文主要亮点在于1)不同于以往主流机器翻译使用基于RNN的seq2seq模型框架,该论文用attention机制代替了RNN搭建了整个模型框架。2)提出了多头注意力(Multi-headed attention)机制方法,在编码器和解码器中大量的使用了多头自注意力机制(Multi-headed self-attention)。3)在WMT2014语料中的英德和英法任务上取得了先进结果,并且训练速度比主流模型更快。
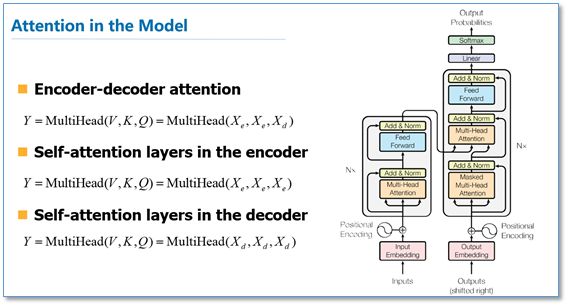
该论文模型的整体结构如下图,还是由编码器和解码器组成,在编码器的一个网络块中,由一个多头attention子层和一个前馈神经网络子层组成,整个编码器栈式搭建了N个块。类似于编码器,只是解码器的一个网络块中多了一个多头attention层。为了更好的优化深度网络,整个网络使用了残差连接和对层进行了规范化(Add&Norm)。

下面我们重点关注一下这篇论文中的attention。在介绍多头attention之前,我们先看一下论文中提到的放缩点积attention(scaled dot-Product attention)。对比我在前面背景知识里提到的attention的一般形式,其实scaled dot-Product attention就是我们常用的使用点积进行相似度计算的attention,只是多除了一个(为K的维度)起到调节作用,使得内积不至于太大。
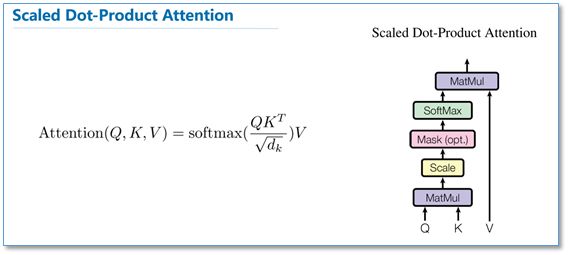
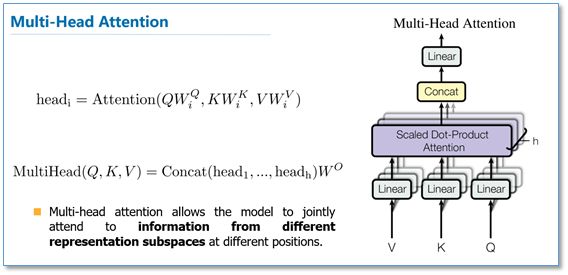
多头attention(Multi-head attention)结构如下图,Query,Key,Value首先进过一个线性变换,然后输入到放缩点积attention,注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数W是不一样的。然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。可以看到,google提出来的多头attention的不同之处在于进行了h次计算而不仅仅算一次,论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息,后面还会根据attention可视化来验证。
那么在整个模型中,是如何使用attention的呢?如下图,首先在编码器到解码器的地方使用了多头attention进行连接,K,V,Q分别是编码器的层输出(这里K=V)和解码器中都头attention的输入。其实就和主流的机器翻译模型中的attention一样,利用解码器和编码器attention来进行翻译对齐。然后在编码器和解码器中都使用了多头自注意力self-attention来学习文本的表示。Self-attention即K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
对于使用自注意力机制的原因,论文中提到主要从三个方面考虑(每一层的复杂度,是否可以并行,长距离依赖学习),并给出了和RNN,CNN计算复杂度的比较。可以看到,如果输入序列n小于表示维度d的话,每一层的时间复杂度self-attention是比较有优势的。当n比较大时,作者也给出了一种解决方案self-attention(restricted)即每个词不是和所有词计算attention,而是只与限制的r个词去计算attention。在并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。在长距离依赖上,由于self-attention是每个词和所有词都要计算attention,所以不管他们中间有多长距离,最大的路径长度也都只是1。可以捕获长距离依赖关系。

最后我们看一下实验结果,在WMT2014的英德和英法机器翻译任务上,都取得了先进的结果,且训练速度优于其他模型。
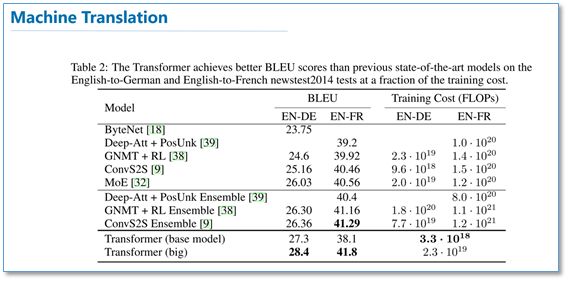
在模型的超参实验中可以看到,多头attention的超参h太小也不好,太大也会下降。整体更大的模型比小模型要好,使用dropout可以帮助过拟合。
作者还将这个模型应用到了句法分析任务上也取得了不错的结果。

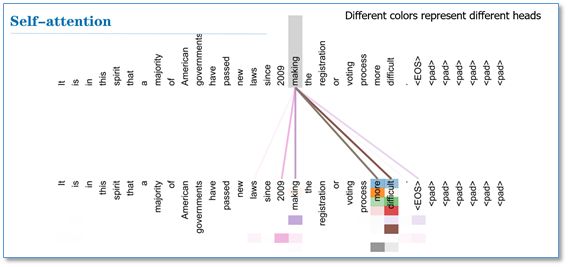
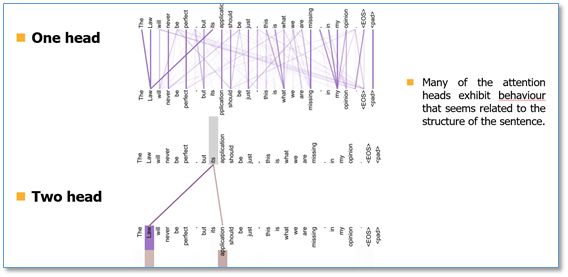
最后我们看一下attention可视化的效果(这里不同颜色代表attention不同头的结果,颜色越深attention值越大)。可以看到self-attention在这里可以学习到句子内部长距离依赖"making…….more difficult"这个短语。在两个头和单头的比较中,可以看到单头"its"这个词只能学习到"law"的依赖关系,而两个头"its"不仅学习到了"law"还学习到了"application"依赖关系。多头能够从不同的表示子空间里学习相关信息。
3 Self-attention in NLP
3.1 Deep Semantic Role Labeling with Self-Attention[8]
这篇论文来自AAAI2018,厦门大学Tan等人的工作。他们将self-attention应用到了语义角色标注任务(SRL)上,并取得了先进的结果。这篇论文中,作者将SRL作为一个序列标注问题,使用BIO标签进行标注。然后提出使用深度注意力网络(Deep Attentional Neural Network)进行标注,网络结构如下。在每一个网络块中,有一个RNN/CNN/FNN子层和一个self-attention子层组成。最后直接利用softmax当成标签分类进行序列标注。
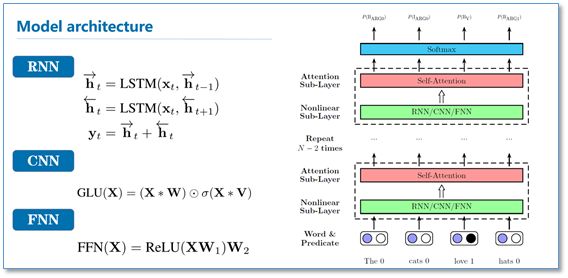
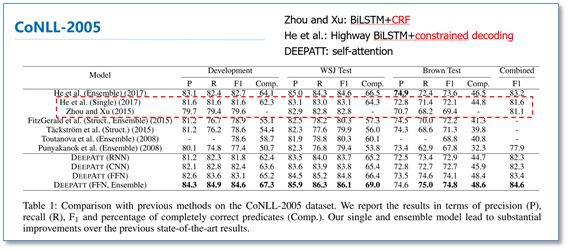
该模型在CoNLL-2005和CoNll-2012的SRL数据集上都取得了先进结果。我们知道序列标注问题中,标签之间是有依赖关系的,比如标签I,应该是出现在标签B之后,而不应该出现在O之后。目前主流的序列标注模型是BiLSTM-CRF模型,利用CRF进行全局标签优化。在对比实验中,He et al和Zhou and Xu的模型分别使用了CRF和constrained decoding来处理这个问题。可以看到本论文仅使用self-attention,作者认为在模型的顶层的attention层能够学习到标签潜在的依赖信息。

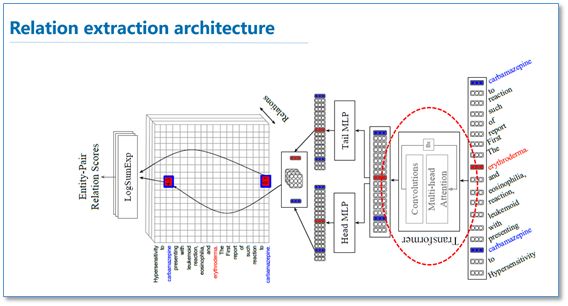
3.2 Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction[7]
这篇论文是Andrew McCallum团队应用self-attention在生物医学关系抽取任务上的一个工作,应该是已经被NAACL2018接收。这篇论文作者提出了一个文档级别的生物关系抽取模型,里面做了不少工作,感兴趣的读者可以更深入阅读原文。我们这里只简单提一下他们self-attention的应用部分。论文模型的整体结构如下图,他们也是使用google提出包含self-attention的transformer来对输入文本进行表示学习,和原始的transformer略有不同在于他们使用了窗口大小为5的CNN代替了原始FNN。
我们关注一下attention这部分的实验结果。他们在生物医学药物致病数据集上(Chemical Disease Relations,CDR)取得了先进结果。去掉self-attention这层以后可以看到结果大幅度下降,而且使用窗口大小为5的CNN比原始的FNN在这个数据集上有更突出的表现。

4 总结
最后进行一下总结,self-attention可以是一般attention的一种特殊情况,在self-attention中,Q=K=V每个序列中的单元和该序列中所有单元进行attention计算。Google提出的多头attention通过计算多次来捕获不同子空间上的相关信息。self-attention的特点在于无视词之间的距离直接计算依赖关系,能够学习一个句子的内部结构,实现也较为简单并行可以并行计算。从一些论文中看到,self-attention可以当成一个层和RNN,CNN,FNN等配合使用,成功应用于其他NLP任务。

除了Google提出的自注意力机制,目前也有不少其他相关工作,感兴趣的读者可以继续阅读。
参考文献
[1] Vaswani, Ashish, et al. Attention is all you need. Advances in Neural Information Processing Systems. 2017.
[2] Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017.
[3] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017.
[4] Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733, 2016.
[5] Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; and Zhang, C. Disan: Directional self-attention network for rnn/cnn-free language understanding. arXiv preprint arXiv:1709.04696, 2017.
[6] Im, Jinbae, and Sungzoon Cho. Distance-based Self-Attention Network for Natural Language Inference. arXiv preprint arXiv:1712.02047, 2017.
[7] Verga P, Strubell E, McCallum A. Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction. arXiv preprint arXiv:1802.10569, 2018.
[8] Tan Z, Wang M, Xie J, et al. Deep Semantic Role Labeling with Self-Attention. AAAI 2018.
[9] Shaw, Peter, Jakob Uszkoreit, and Ashish Vaswani. Self-Attention with Relative Position Representations. arXiv preprint arXiv:1803.02155 ,2018.
参考博客
张俊林,深度学习中的注意力机制(2017版),https://blog.csdn.net/malefactor/article/details/78767781
苏剑林,《Attention is All You Need》浅读(简介+代码),https://kexue.fm/archives/4765