2019独角兽企业重金招聘Python工程师标准>>> 
流程简介
使用logstash从MySQL增量提取数据,传入elasticsearch中,并通过kibana做简单的图表
logstash
logstash安装
#下载,logstash5及以上版本需要jdk8
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.1.1.zip
#解压
unzip logstash-6.1.1.zip
#To test your Logstash installation, run the most basic Logstash pipeline
#测试logstash环境,运行如下demo(input {stdin{}}:接收终端输入;output {stdout{}}:输出到终端),出现Pipeline main started为正常
cd logstash-6.1.1
./bin/logstash -e 'input {stdin{}} output {stdout{}}'
#-----------------------------------start-----------------------------------
Settings: Default pipeline workers: 24
Pipeline main started
#------------------------------------end------------------------------------
#The -e flag enables you to specify a configuration directly from the command line. Specifying configurations at the command line lets you quickly test configurations without having to edit a file between iterations. The pipeline in the example takes input from the standard input, stdin, and moves that input to the standard output, stdout, in a structured format.
#测试,输入hello world,然后回车
#出现如下信息即为安装成功
#-----------------------------------start-----------------------------------
2018-01-04T02:44:41.024Z hostname hello world
#------------------------------------end------------------------------------
logstash-input-jdbc插件
#logstash-6.1.1已支持logstash-input-jdbc,不需要单独安装
#老版本安装logstash-input-jdbc
./bin/plugin install logstash-input-jdbc配置logstash增量提取MySQL数据
cat mysql_pipelines.yml
#-----------------------------------start-----------------------------------
#输入部分
input {
jdbc {
#连接MySQL驱动,需要自己下载
jdbc_driver_library => "/es/mysql-connector-java-5.1.31.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://10.112.29.30:3306/mstore"
#连接数据库账号信息
jdbc_user => "MySQL_admin"
jdbc_password => "password"
#分页
jdbc_paging_enabled => true
#分页大小
jdbc_page_size => 100000
#流式获取数据,每次取10000.
jdbc_fetch_size => 10000
#Maximum number of times to try connecting to database
connection_retry_attempts => 3
#Number of seconds to sleep between connection attempts
connection_retry_attempts_wait_time => 1
#Connection pool configuration. The amount of seconds to wait to acquire a connection before raising a PoolTimeoutError (default 5)
jdbc_pool_timeout => 5
#Whether to force the lowercasing of identifier fields
lowercase_column_names => true
#Whether to save state or not in last_run_metadata_path
#保存上次运行记录,增量提取数据时使用
record_last_run = > true
#"* * * * *"为每分钟执行一次
schedule => "* * * * *"
#Use an incremental column value rather than a timestamp
use_column_value => true
#sql_last_value
#The value used to calculate which rows to query. Before any query is run, this is set to Thursday, 1 January 1970, or 0 if use_column_value is true and tracking_column is set. It is updated accordingly after subsequent queries are run.
tracking_column => "id"
#查询语句
statement => "SELECT id,package_name,name,sub_name,editor_comment,high_quality,sub_category,tag,update_time FROM tbl_app WHERE id > :sql_last_value"
}
}
#过滤部分
filter {
json {
source => "message"
remove_field => ["message"]
}
date{
match => ["update_time","yyy-MM-dd HH:mm:ss"]
}
}
#输出到elastsicearch
output {
elasticsearch {
#elasticsearch集群地址,不用列出所有节点,默认端口号也可省略
hosts => ["10.127.92.181:9200", "10.127.92.212:9200", "10.127.92.111:9200"]
#索引值,查询的时候会用到;需要先在elasticsearch中创建对应的mapping,也可以采用默认的mapping
index => "store"
#指定插入elasticsearch文档ID,对应input中sql字段id
document_id => "%{id}"
}
}
#------------------------------------end------------------------------------
#注:使用时请去掉此文件中的注释,不然会报错
#logstash会把执行记录默认存在账户根目录下: /root/.logstash_jdbc_last_run
#如果需要重新加载数据到elasticsearch,需要删除这个文件启动logstash
请在启动elasticsearch之后再启动logstash,不然连接elasticsearch会报错
#后台启动logstash ./bin/logstash -f config/mysql_pipelines.yml & #如果报下面错误,说明jdk版本不支持 #-----------------------------------start----------------------------------- NameError: cannot link Java class org.logstash.RubyUtil org/logstash/RubyUtil : Unsupported major.minor version 52.0 method_missing at org/jruby/javasupport/JavaPackage.java:259at /disk2/es/logstash-6.1.1/logstash-core/lib/logstash-core/logstash-core.rb:37 require at org/jruby/RubyKernel.java:955at /disk2/es/logstash-6.1.1/logstash-core/lib/logstash/runner.rb:1 require at org/jruby/RubyKernel.java:955at /disk2/es/logstash-6.1.1/lib/bootstrap/environment.rb:66 #------------------------------------end------------------------------------ #logstash-6.1.1需要jdk1.8 #请自行下载jdk1.8版本放到/opt/jdk1.8.0_151 #编写启动脚本如下 cat exec_logstash.sh #-----------------------------------start----------------------------------- #!/bin/sh #配置jdk1.8执行环境 export JAVA_HOME=/opt/jdk1.8.0_151 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar ./bin/logstash -f config/mysql_pipelines.yml & #------------------------------------end------------------------------------
elasticearch
elasticsearch安装
#下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.1.1.zip
#解压
unzip elasticsearch-6.1.1.zip
cd elasticsearch-6.1.1
#配置jvm内存
vim config/jvm.options
#-----------------------------------start-----------------------------------
-Xms8g
-Xmx8g
#------------------------------------end------------------------------------
#注:把内存(少于)一半给Lucene,内存对于 Elasticsearch 来说绝对是重要的,它可以被许多内存数据结构使用来提供更快的操作。但是说到这里, 还有另外一个内存消耗大户 非堆内存 (off-heap):Lucene。
#Lucene 被设计为可以利用操作系统底层机制来缓存内存数据结构。 Lucene 的段是分别存储到单个文件中的。因为段是不可变的,这些文件也都不会变化,这是对缓存友好的,同时操作系统也会把这些段文件缓存起来,以便更快的访问。
#Lucene 的性能取决于和操作系统的相互作用。如果你把所有的内存都分配给 Elasticsearch 的堆内存,那将不会有剩余的内存交给 Lucene。 这将严重地影响全文检索的性能。
#标准的建议是把 50% 的可用内存作为 Elasticsearch 的堆内存,保留剩下的 50%。当然它也不会被浪费,Lucene 会很乐意利用起余下的内存。
#如果你不需要对分词字符串做聚合计算(例如,不需要 fielddata )可以考虑降低堆内存。堆内存越小,Elasticsearch(更快的 GC)和 Lucene(更多的内存用于缓存)的性能越好。
#分配给Elasticsearch的内存不能超过32G。JVM 在内存小于 32 GB 的时候会采用一个内存对象指针压缩技术。
#在 Java 中,所有的对象都分配在堆上,并通过一个指针进行引用。 普通对象指针(OOP)指向这些对象,通常为 CPU 字长 的大小:32 位或 64 位,取决于你的处理器。指针引用的就是这个 OOP 值的字节位置。
#对于 32 位的系统,意味着堆内存大小最大为 4 GB。对于 64 位的系统, 可以使用更大的内存,但是 64 位的指针意味着更大的浪费,因为你的指针本身大了。更糟糕的是, 更大的指针在主内存和各级缓存(例如 LLC,L1 等)之间移动数据的时候,会占用更多的带宽。
#Java 使用一个叫作 内存指针压缩(compressed oops)的技术来解决这个问题。 它的指针不再表示对象在内存中的精确位置,而是表示 偏移量 。这意味着 32 位的指针可以引用 40 亿个 对象 , 而不是 40 亿个字节。最终, 也就是说堆内存增长到 32 GB 的物理内存,也可以用 32 位的指针表示。
#一旦你越过那个神奇的 ~32 GB 的边界,指针就会切回普通对象的指针。 每个对象的指针都变长了,就会使用更多的 CPU 内存带宽,也就是说你实际上失去了更多的内存。事实上,当内存到达 40–50 GB 的时候,有效内存才相当于使用内存对象指针压缩技术时候的 32 GB 内存。
#即便你有足够的内存,也尽量不要 超过 32 GB。因为它浪费了内存,降低了 CPU 的性能,还要让 GC 应对大内存。
#设置堆内存为 31 GB 是一个安全的选择。 另外,你可以在你的 JVM 设置里添加 -XX:+PrintFlagsFinal 用来验证 JVM 的临界值, 并且检查 UseCompressedOops 的值是否为 true。对于你自己使用的 JVM 和操作系统,这将找到最合适的堆内存临界值。
#具体请参考:https://www.elastic.co/guide/cn/elasticsearch/guide/current/heap-sizing.html
#elasticsearch集群信息配置
vim config/elasticsearch.yml
#-----------------------------------start-----------------------------------
#配置集群名称,每个节点集群名称请保持一致
cluster.name: my-app
#配置节点名称,每个节点需要起不同的名称
node.name: node-1
#配置数据存储目录
path.data: /disk3/to/data,/disk4/to/data
#log存储位置
path.logs: /disk3/to/logs
#Set the bind address to a specific IP (IPv4 or IPv6)
#0.0.0.0为不限制访问
network.host: 0.0.0.0
#端口
http.port: 9200
#配置集群
discovery.zen.ping.unicast.hosts: ["10.127.92.212", "10.127.92.181"]
#Lock the memory on startup
#true表示不允许内存交换(内存交换影响速度)
#如果报错,使用执行ulimit -l unlimited,取消限制最大加锁内存
bootstrap.memory_lock: true
#系统调用过滤器,建议禁用该项检查,因为很多检查项需要Linux 3.5以上的内核
bootstrap.system_call_filter: false
#------------------------------------end------------------------------------elasticsearch配置
#在其他资源可用的前提下,单个JVM能开启的最大线程数是/proc/sys/vm/max_map_count的设置数的一半
#永久生效,把vm.max_map_count=262144写入/etc/sysctl.conf中,然后执行sysctl -p
#默认vm.max_map_count=65530,会报错,导致elasticsearch无法启动
sysctl -w vm.max_map_count=262144
sysctl -p
#默认elasticsearch无法以root账户启动,需要创建单独账户
#创建用户组
groupadd elastic
#创建用户es,指定附属组root
useradd -g elastic -G root es
#配置jdk1.8环境
vim bin/elasticsearch
#-----------------------------------start-----------------------------------
#最上面加入下面内容
export JAVA_HOME=/disk4/es/jdk1.8.0_151
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#------------------------------------end------------------------------------
中文分词插件安装
#不需要中文分词搜索的请忽略这一步
#下载中文分词插件ik
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.1.1/elasticsearch-analysis-ik-6.1.1.zip
#解压
unzip elasticsearch-analysis-ik-6.1.1.zip
#移动解压文件到elasticsearch内plugins下即可
mv elasticsearch-analysis-ik-6.1.1 elasticsearch-6.1.1/plugins/ik
#ik在github地址:https://github.com/medcl/elasticsearch-analysis-ik
#Analyzer: ik_smart , ik_max_word ; Tokenizer: ik_smart , ik_max_word
#ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
#ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
#在elasticsearch启动之后可以测试
curl -H 'content-type: application/json' 'http://localhost:9200/store/_analyze?pretty=true' -d '{"text":"中华人民共和国国歌","analyzer":"ik_max_word"}'
curl -H 'content-type: application/json' 'http://localhost:9200/store/_analyze?pretty=true' -d '{"text":"中华人民共和国国歌","analyzer":"ik_smart"}'
启动elasticsearch
#以用户es启动elasticsearch
#-d指定后台启动
sudo -u es ./bin/elasticsearch -d
#逐个启动集群节点
#检查集群
curl -XGET http://localhost:9200?pretty
#-----------------------------------start-----------------------------------
{
"name" : "node-1",
"cluster_name" : "my-app",
"cluster_uuid" : "ncrtFPuhRJuv9D7R4cOp4w",
"version" : {
"number" : "6.1.1",
"build_hash" : "bd92e7f",
"build_date" : "2017-12-17T20:23:25.338Z",
"build_snapshot" : false,
"lucene_version" : "7.1.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
#------------------------------------end------------------------------------
#查看集群
curl -XGET 'localhost:9200/_cat/nodes?v&pretty'
#-----------------------------------start-----------------------------------
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.127.92.212 25 92 0 0.00 0.00 0.00 mdi - node-2
10.127.92.181 13 99 1 0.18 0.21 0.10 mdi - node-1
10.127.92.111 12 70 3 0.14 0.04 0.01 mdi * node-3
#------------------------------------end------------------------------------
#*号表示为master节点
#查看elasticsearch安装插件
curl -XGET localhost:9200/_cat/plugins?v
#-----------------------------------start-----------------------------------
name component version
node-2 analysis-ik 6.1.1
node-1 analysis-ik 6.1.1
node-3 analysis-ik 6.1.1
#------------------------------------end------------------------------------
创建mapping
mapping类似于关系型数据库中的表结构定义
#创建mapping文件
vim store_mapping.json
#-----------------------------------start-----------------------------------
{
"settings": {
"number_of_shards": 5,#主分片数,默认5
"number_of_replicas": 1#副本数,写1为每个主分片有一个副本
},
"mappings": {
#type类型,新版貌似不能修改了,默认就是doc。也就是说这个位置现在固定为doc了
"doc": {
"properties": {
#sql中对应字段信息
"id": {
#支持的数据类型:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
"type": "long",
#The index option controls whether field values are indexed. It accepts true or false and defaults to true. Fields that are not indexed are not queryable.
"index": false,
#是否存在于_source,和source filtering使用相关,默认true
"store": true
},
"package_name": {
"index": false,
#keyword表示是不会拆解,表示准确值
#They are typically used for filtering (Find me all blog posts where status is published), for sorting, and for aggregations. Keyword fields are only searchable by their exact value.
#If you need to index structured content such as email addresses, hostnames, status codes, or tags, it is likely that you should rather use a keyword field.
#If you need to index full text content such as email bodies or product descriptions, it is likely that you should rather use a text field.
"type": "keyword"
},
"name": {
#type为text会被拆解成词元
#an analyzer to convert the string into a list of individual terms before being indexed
#The analysis process allows Elasticsearch to search for individual words within each full text field. Text fields are not used for sorting and seldom used for aggregations
"type": "text",
#指定解析者,默认standard
"analyzer": "ik_max_word",
#The analyzer that should be used at search time on analyzed fields. Defaults to the analyzer setting.
"search_analyzer": "ik_max_word"
},
"sub_name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"editor_comment": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"high_quality": {
"type": "integer",
"store": true
},
"sub_category": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"tag": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"update_time": {
"type": "date"
}
}
}
}
}
#------------------------------------end------------------------------------
#新建index,这里为store(和logstash配置文件中保持一致)
curl -XPUT 'localhost:9200/store'
#上传mapping到创建的index中
curl -XPUT -H 'content-type: application/json' 'http://localhost:9200/store' -d @store_mapping.json
#查看创建的mapping
curl -XGET http://localhost:9200/store/doc/_mapping?pretty
#这个时候就可以启动logstash了
#查看elasticsearch是否已经有数据
curl -XGET http://localhost:9200/store/doc/_search?pretty=true
#v:显示详细信息;pretty:格式化显示信息
#来个复杂点的查询。查询name或者editor_comment包含“自由”,并以update_time降序,_score降序排序搜索结果
curl -XPOST -H 'content-type: application/json' 'http://localhost:9200/store/doc/_search?pretty=true' -d '
{
"query": {
"multi_match" : {
"query": "自由",
"fields": [ "name", "editor_comment" ]
}
},
"sort": [
{ "update_time": { "order": "desc" }},
{ "_score": { "order": "desc" }}
]
}'
kibana
kibana安装配置
#下载kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.1.1-linux-x86_64.tar.gz
#解压
tar -zxvf kibana-6.1.1-linux-x86_64.tar.gz
cd kibana-6.1.1-linux-x86_64
#配置
vim config/kibana.yml
#-----------------------------------start-----------------------------------
#配置kibana访问端口
server.port: 5601
#配置允许访问kibana的ip,0.0.0.0表示不做限制
server.host: "0.0.0.0"
#elasticsearch集群连接
elasticsearch.url: "http://localhost:9200"
#kibana运行ID位置
pid.file: /var/run/kibana.pid
#------------------------------------end------------------------------------
#启动kibana
./bin/kibana &
访问kibana:http://ip:port
界面如下:

点击Management,然后点击Index Patterns,创建一个index过滤器
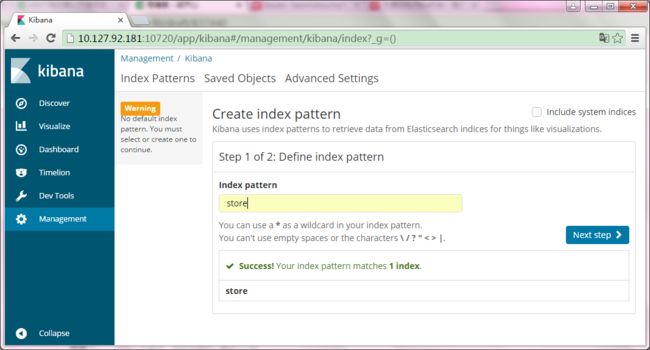
点击Next step,选择是否通过时间过滤数据

点击Create index pattern即创建

点击左侧Discover,创建一个查询

点击查询

左侧Avaliable Fields可以设置右侧显示字段信息,点击上方Save可以保存查询条件

点击左侧Visualize,点击Create a visualization
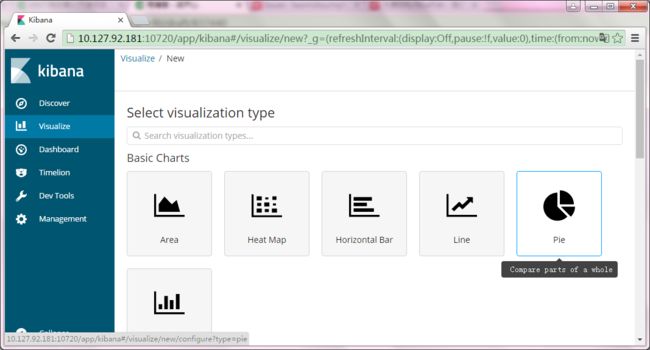
选择一个你要创建的图表,我选择了饼图
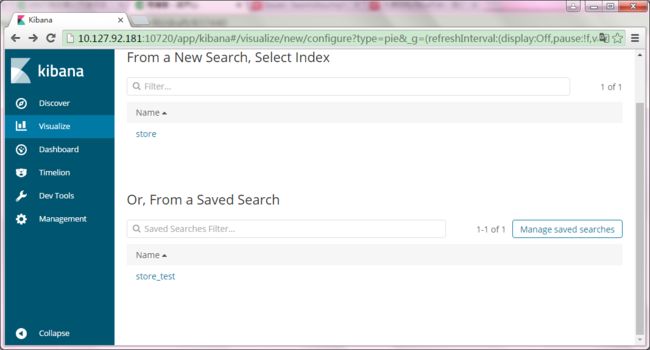
store_test为Discover中保存的搜索条件名称,点击store_test

点击页面靠左侧部分的Split Slices,然后选择Aggregation类型,配置结果如下

然后点击执行按钮,结果如下,From为>=,to为<

点击上方Save,并定义个Visualization名称
注:如果需要配置双层圆环,可以点击Add sub-buckets,操作同Split Slices

点击左侧Dashboard,点击Create a dashboard
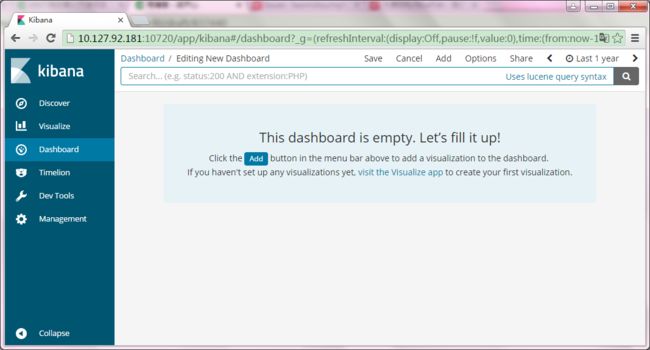
点击Add按钮

点击visualize名称,下方出现图表如下
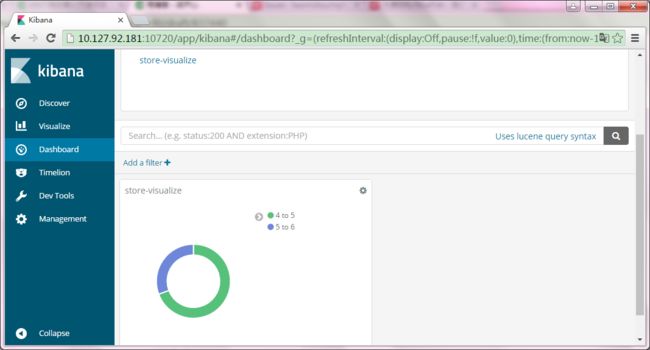
点击上方Save,并输入Dashbioard名称

注:创建的图表都可以以这种方式放到Dashboard中