[问题现象]
服务器在运行过程中,因人为意外导致电源被拔,服务器宕机,mysql重启不成功,报错如下
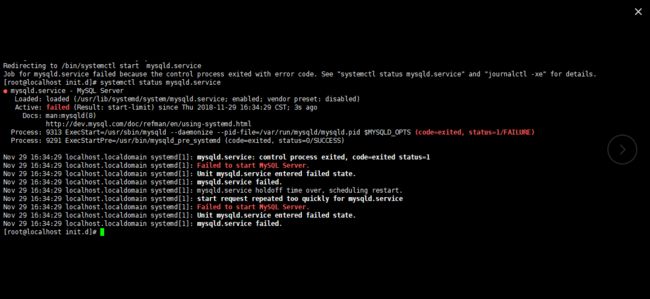
根据提示,输入systemctl status mysql.service和journalctl -xe查看日志,经过一番百度谷歌折腾也是无果。(很多时候,不能因为突发事件就“病急乱投医”)
最后在mysql 的日志处看到了报错日志
如果centos是通过yum安装的mysql,那么日志一般在/var/log/mysql.log
查看到日志
2018-11-29T08:39:18.977374Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
2018-11-29T08:39:18.978051Z 0 [Note] /usr/sbin/mysqld (mysqld 5.7.22) starting as process 11192 ...
2018-11-29T08:39:18.979893Z 0 [Note] InnoDB: PUNCH HOLE support available
2018-11-29T08:39:18.979910Z 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2018-11-29T08:39:18.979914Z 0 [Note] InnoDB: Uses event mutexes
2018-11-29T08:39:18.979916Z 0 [Note] InnoDB: GCC builtin __atomic_thread_fence() is used for memory barrier
2018-11-29T08:39:18.979918Z 0 [Note] InnoDB: Compressed tables use zlib 1.2.3
2018-11-29T08:39:18.979920Z 0 [Note] InnoDB: Using Linux native AIO
2018-11-29T08:39:18.980073Z 0 [Note] InnoDB: Number of pools: 1
2018-11-29T08:39:18.980135Z 0 [Note] InnoDB: Using CPU crc32 instructions
2018-11-29T08:39:18.981011Z 0 [Note] InnoDB: Initializing buffer pool, total size = 128M, instances = 1, chunk size = 128M
2018-11-29T08:39:18.985294Z 0 [Note] InnoDB: Completed initialization of buffer pool
2018-11-29T08:39:18.986268Z 0 [Note] InnoDB: If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority().
2018-11-29T08:39:18.997726Z 0 [Note] InnoDB: Highest supported file format is Barracuda.
2018-11-29T08:39:18.998629Z 0 [Note] InnoDB: Log scan progressed past the checkpoint lsn 23732273189
2018-11-29T08:39:18.998641Z 0 [Note] InnoDB: Doing recovery: scanned up to log sequence number 23732273507
2018-11-29T08:39:18.998881Z 0 [Note] InnoDB: Database was not shutdown normally!
2018-11-29T08:39:18.998887Z 0 [Note] InnoDB: Starting crash recovery.
2018-11-29T08:39:19.110899Z 0 [Note] InnoDB: Removed temporary tablespace data file: "ibtmp1"
2018-11-29T08:39:19.110915Z 0 [Note] InnoDB: Creating shared tablespace for temporary tables
2018-11-29T08:39:19.110957Z 0 [Note] InnoDB: Setting file './ibtmp1' size to 12 MB. Physically writing the file full; Please wait ...
2018-11-29T08:39:19.149162Z 0 [Note] InnoDB: File './ibtmp1' size is now 12 MB.
2018-11-29T08:39:19.149810Z 0 [Note] InnoDB: 96 redo rollback segment(s) found. 96 redo rollback segment(s) are active.
2018-11-29T08:39:19.149818Z 0 [Note] InnoDB: 32 non-redo rollback segment(s) are active.
2018-11-29T08:39:19.150158Z 0 [Note] InnoDB: Waiting for purge to start
2018-11-29 16:39:19 0x7f1219ffb700 InnoDB: Assertion failure in thread 139715722327808 in file fut0lst.ic line 85
InnoDB: Failing assertion: addr.page == FIL_NULL || addr.boffset >= FIL_PAGE_DATA
InnoDB: We intentionally generate a memory trap.
InnoDB: Submit a detailed bug report to http://bugs.mysql.com.
InnoDB: If you get repeated assertion failures or crashes, even
InnoDB: immediately after the mysqld startup, there may be
InnoDB: corruption in the InnoDB tablespace. Please refer to
InnoDB: http://dev.mysql.com/doc/refman/5.7/en/forcing-innodb-recovery.html
InnoDB: about forcing recovery.
08:39:19 UTC - mysqld got signal 6 ;
This could be because you hit a bug. It is also possible that this binary
or one of the libraries it was linked against is corrupt, improperly built,
or misconfigured. This error can also be caused by malfunctioning hardware.
Attempting to collect some information that could help diagnose the problem.
As this is a crash and something is definitely wrong, the information
collection process might fail.
通过搜索
InnoDB: Failing assertion: addr.page == FIL_NULL || addr.boffset >= FIL_PAGE_DATA
了解到,大部分都是因为服务器在数据库没用停止服务的情况下宕机,导致数据丢失
解决方法有俩个:
1、如果是大佬,则继续深入踩坑研究,运气好能在google查到相似问题解决方案(反正我是没查到
2、直接备份数据库,然后初始化数据库后进行恢复数据
[问题原因]
服务器宕机导致innodb的数据和实际数据库的数据不一致,在启动的时候就报错了
[解决方法]
1. Forcing InnoDB Recovery
在 /etc/my.cnf中添加如下配置:
[mysqld]
innodb_force_recovery = 1
其中后面的值设置为1、如果1不能启动成功,再逐步增加为2/3/4等。直到能启动mysql为止!!!
重启成功后,测试数据库是否可以正常连接:
mysql -u root -p 123456
能连进去的话就exit退出
2.数据备份
找一个自己找得到的目录做数据备份
mysqldump -u root -p 123456 --all-databases > all_mysql_backup.sql
3.初始化数据库
mysqld --initialize
启动数据库
service mysqld start
如果报错,则显得去删除mysql的data目录
这里的data目录实际就是你数据库存放的目录,比如知道的/var/lib/mysql
4.数据恢复
登录数据库
mysql -u root -p 123456
恢复
source /备份目录/all_mysql_backup.sql