即将上线的flume服务器面临的一系列填坑笔记
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.flume缺少依赖包导致启动失败!
报错信息如下:
2018-10-17 11:07:43,369 (conf-file-poller-0) [ERROR - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:146)] Failed to start agent because dependencies were not found in classpath. Error follows.

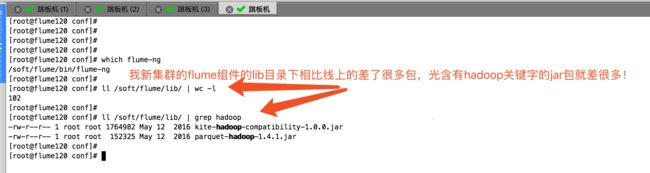
上面的报错信息很明显的告诉了我们,缺少依赖包。没有找到依赖环境!我对比了线上的flume的lib目录下和我新集群的lib目录,发现是有点不一样!下图就是我线上的环境:

下图就是我新集群的环境:
此时相信大家看到这种情况,已经迫不及待的想把线上的jar包都拷贝过来,观察问题是否解决,没错,我也是这么想的,于是我将线上的jar包拷贝到了我的集群。如下图:

拷贝完成后,观察我的新集群的jar包和线上jar包环境是一致的!如下图: 
我新集群的环境和线上的保持一致后,重新执行上述的错误就不在出现啦!
二.内存溢出,导致flume运行崩溃
解决了上面关于依赖包的问题,发现新错又出现了,报错OOM,报错信息如下:
Exception in thread "PollableSourceRunner-KafkaSource-kafkaSource" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.ArrayList.iterator(ArrayList.java:834)
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "PollableSourceRunner-KafkaSource-kafkaSource"
Exception in thread "SinkRunner-PollingRunner-DefaultSinkProcessor" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "SinkRunner-PollingRunner-DefaultSinkProcessor"
相必须看到上述的报错的小伙伴应该都跟我一样,第一反应就是调大内存,在将堆内存调大之前,我们先看一下flume默认给我分配堆堆内存是多大,如下图:(我们看到flume默认指定堆堆大堆内存为20M,它崩溃了是理所当然的,毕竟我们公司的数据量也不小!)

你是不是很好奇,这个20M大小在哪里设置的呢?其实就是在flume-ng这个脚本里写死了,编辑你的flume-ng脚本,查看第225行,如下图:

找到原因呢后,我们可以修改这个上面的配置文件(/soft/apache-flume-1.7.0-bin/bin/flume-ng,这个路径跟你安装flume的路径去找,推荐使用which,find命令将他找出来!)参数(JAVA_OPTS="-Xmx10240m"),我们将20M改为10G,具体操作如下:

当然,如果你不想修改默认的参数,我们也可以在启动的时候修改JVM的堆内存空间。我在命令行启动flume进程的时候手动分配Java的堆内存大小为2G,如下图:

三.缺少Hadoop的运行环境导致无法通过kafka将数据拷贝到hdfs中。
报错信息如下:
2018-10-17 13:06:45,287 (SinkRunner-PollingRunner-DefaultSinkProcessor) [WARN - org.apache.flume.sink.hdfs.BucketWriter.getRefIsClosed(BucketWriter.java:182)] isFileClosed is not available in the version of HDFS being used. Flume will not attempt to close files if the close fails on the first attempt
java.lang.NoSuchMethodException: org.apache.hadoop.fs.LocalFileSystem.isFileClosed(org.apache.hadoop.fs.Path)
遇到上面的这种情况,首先请确认你的hdfs的环境是否安装了,我的flume机器上仅仅部署了jdk和flume环境,其他的环境都没部署。如果你跟我一样没有部署的话,我给你个思路:
1>.去Apache官网下载和你集群中hdfs版本一致的包,安装到你的服务器上;(我cdh默认hdfs版本是2.6.0,于是我就去官网下载相应的包:https://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/)
2>.安装过程很简单,解压即可,然后在“/etc/profile”这个配置文件中配置一下环境变了,最后别忘记将你要上传到hdfs集群中的配置文件(core-site.xml和hdfs-site.xml )拷贝一份到本地,将这两个配置文件覆盖到本地到配置文件,配置文件生效后,需要使用“source /etc/profile”命令来重新加载一个系统的环境变量的配置文件,配置完成后我们可以通过下面的命令查看hdfs的版本。

按照上述方法操作后,我们再次运行flume,发现不报错了,数据也开始在hdfs中写了,是不是没有报错信息了?没有报错就是最好的结果,如下图:

接下来我们去集群的webUI查看相应的文件是否生产,果不其然,文件已经写到hdfs中了:

四.broker节点时间不同步导致的
报错信息如下:
2018-10-18 16:28:37,329 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator$SyncGroupRequestHandler.handle(AbstractCoordinator.java:431)] SyncGroup for group flume-consumer-against_cheating_01 failed due to coordinator rebalance, rejoining the group
2018-10-18 16:28:37,957 (PollableSourceRunner-KafkaSource-kafkaSource) [WARN - org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:560)] Sending events to Kafka failed
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: The request timed out.
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:56)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:43)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:25)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:552)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194)
at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:295)
at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:60)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.kafka.common.errors.TimeoutException: The request timed out.
这个问题,困扰了我好久,百度谷歌接近2个小时,都没有找到答案,手动去kafka集群拉去数据也是可以正常拉去都,就是一直报上面都错误,最后我们运维小组都人一起在办公室帮我分析一下原因,我自己也纳闷,为什么上午还好好都,下午就不好使了。我一个同时说会不会是下午你让我同步Hadoop集群都时间了?导致这个错误都发生?我寻思了一番,于是重启了一下Hadoop集群,发现以上错误烟消云散啦!那么问题来了,为什么会这样的呢?
说到这,我们就不得不探讨一下Kafka的工作原理了。