tags:
- 1880-2010年间全美婴儿姓名
- 分析命名趋势
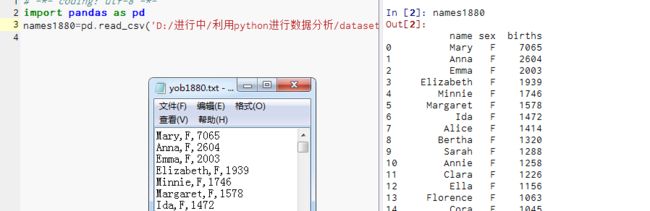
1880-2010年间全美婴儿姓名
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)[source]¶
将CSV(逗号分隔)文件读入DataFrame
数据中是以‘,’为分隔符,所以用'pandas.read_csv'将其加载到DataFrame中
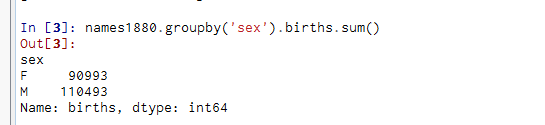
【目标】统计男女婴出生总数
【方式】分组;统计
数据集:
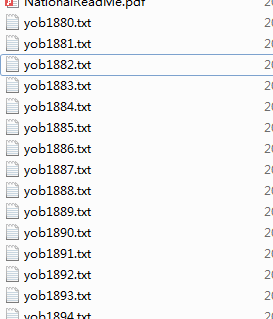
可以看见该数据集按年度被分隔成了多个文件,所以想要整体分析,需要将其全部合并到一个DataFrame中
【目标】将所有数据都组装到DataFrame里面,并加上一个year字段。
【方式】将所有数据组装到一个DataFrame中并加上year字段;使用pandas.concat整合数据。
*注意:1.concat默认是按行将多个DataFrame组合到一起的;
2.必须指定ignore_index=True,因为我们不希望保留read_csv所返回的原始行号。
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)[source]
Concatenate pandas objects along a particular axis with optional set logic along the other axes.
Can also add a layer of hierarchical indexing on the concatenation axis, which may be useful if the labels are the same (or overlapping) on the passed axis number.
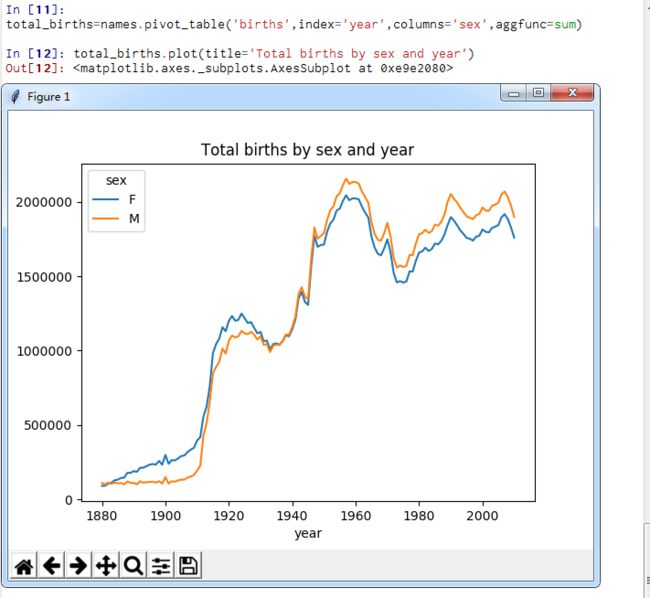
【目标】按年份性别对婴儿进行统计
【方式】利用groupby分组,pivot_table聚合成表。
【目标】插入一个prop列,存放指定名字的婴儿数相对于总出生数的比例。
【方式】先按year和sex分组,然后再将新列加到各个分组上。
**执行类似分组处理,应该做一些有效性检查:
【目标】这里可以验证所有分组的prop总和是否为1。
【方式】用np.allclose来检查这个分组的总计是否足够接近于1(可能不会精确等于1)

【目标】为了进一步分析,需要去除该数据一个子集:每对sex/year组合的前1000个名字。
【方式】分组
分析命名趋势
【目标】绘制部分名字numbers of births per year和year的线形图
【方式】1.分男女,2.统计各姓名出现总次数,3.绘图
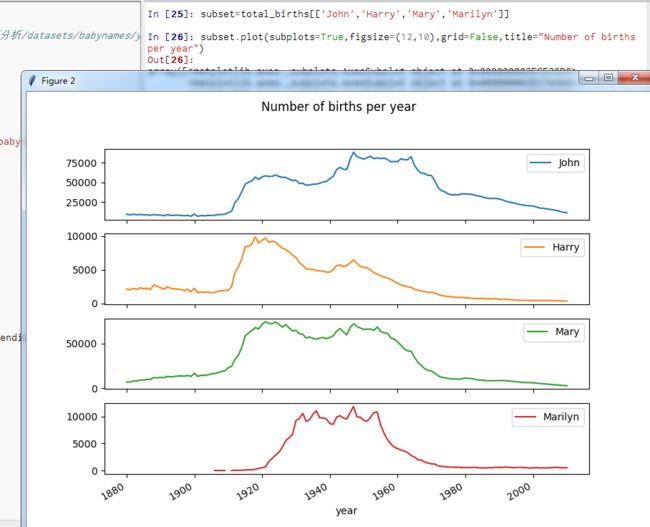
上图反映的降低情况可能意味着父母愿意给小孩起常见名字越来越少。
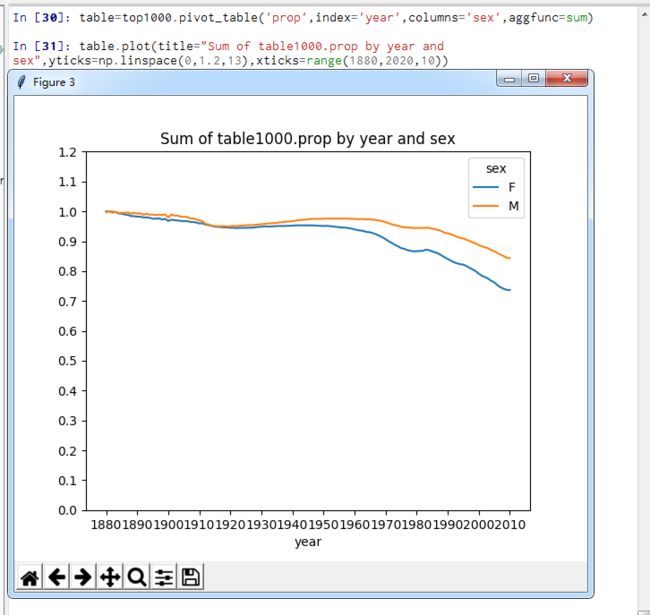
【目标】计算最流行的1000个名字所占的比例
【方式】按year和sex、进行聚合并绘图
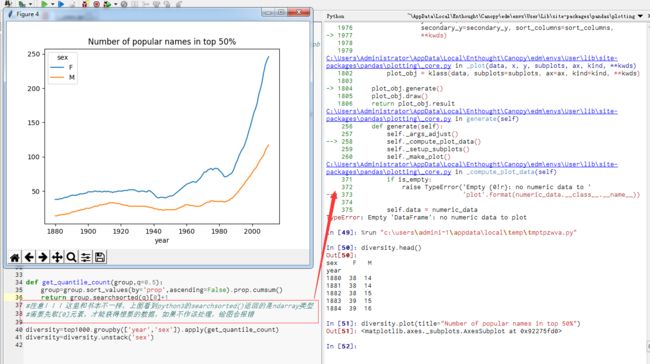
【目标】计算占总出生人数前50%的不同名字数量
【方式】可以通过for循环达到目的。但NumPy有一种更简单的矢量方法:
先计算prop的累积好cumsum,然后通过searchsorted方法找出0.5应该插入在哪个位置。
DataFrame.cumsum( axis = None, skipna = True, * args,_** kwargs _) [来源] ¶
返回DataFrame或Series轴上的累积和。
返回包含累积和的相同大小的DataFrame或Series。
Series.searchsorted(value,side ='left',_sorter = None _)¶
查找应插入元素以维护顺序的索引。
将索引查找到已排序的Series self中,这样,如果在索引之前插入值中的相应元素,则将保留self的顺序。
GroupBy.apply(func, *args, **kwargs)¶
Apply function func group-wise and combine the results together.
The function passed to apply must take a dataframe as its first argument and return a dataframe, a series or a scalar. apply will then take care of combining the results back together into a single dataframe or series. apply is therefore a highly flexible grouping method.
*“最后一个字母”的变革
【目标】证实“男孩名字在近百年来在对吼一个字母上的分布发生了显著的变化”。
【方式】1.将全部出生数据在年度、性别以及末字母上进行聚合;2.按总出生人数对该表进行规范化处理,计算各性别各末字母占总出生人数比例:
get_last_letter = lambda x:x[-1]
last_letters = names.names.map(get_last_letter)
last_letters.names = 'last_letter'
table = names.pivot_table('births',index=last_letters,columns=['sex','year'],aggfunc=sum)
subtable = table.reindex(columns=[1910,1960,2010],level='year')
import matplotlib.pyplot as plt
fig,axes = plt.subplots(2,1,figsize=(10,8))
letter_prop['M'].plot(kind='bar',rot=0,ax=axes[0],title='Male')
Out[149]:
letter_prop['F'].plot(kind='bar',rot=0,ax=axes[1],title='Female',legend=False)
Out[150]:
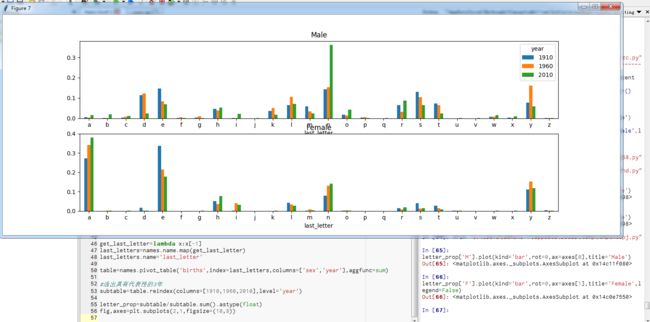
从上图可以看出,从20世纪60年代开始,以字母“n”结尾的男孩子名字出现显著的增长。回到之前创建的那个完整表,按年度和性别对其进行规范化处理,并在男孩子名字中选出几个字母,最后进行转置以便将各个列做成一个时间序列;有了这个时间序列的DataFrame之后,就可以通过其plot方法绘制出一张趋势图了:

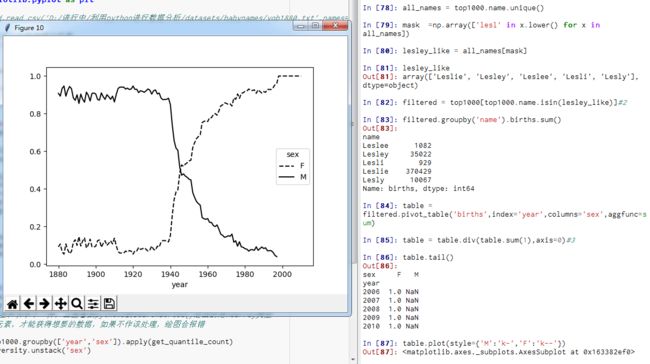
*变成女孩名字的男孩
all_names = top1000.name.unique()
mask =np.array(['lesl' in x.lower() for x in all_names])
lesley_like = all_names[mask]
lesley_like
Out[81]: array(['Leslie', 'Lesley', 'Leslee', 'Lesli', 'Lesly'], dtype=object)
filtered = top1000[top1000.name.isin(lesley_like)]#2
filtered.groupby('name').births.sum()
Out[83]:
name
Leslee 1082
Lesley 35022
Lesli 929
Leslie 370429
Lesly 10067
Name: births, dtype: int64
table = filtered.pivot_table('births',index='year',columns='sex',aggfunc=sum)
table = table.div(table.sum(1),axis=0)#3
table.tail()
Out[86]:
sex F M
year
2006 1.0 NaN
2007 1.0 NaN
2008 1.0 NaN
2009 1.0 NaN
2010 1.0 NaN
table.plot(style={'M':'k-','F':'k--'})
【目标】证实“一个有趣的趋势:早年流行于男孩的名字近年来‘变性了’,例如Lesley或Leslie。”
【方式1.】1.回到top1000数据集,找出其中以“lesl”开头的一组名字;2.然后利用这个结果过滤其他的名字,并按名字分组计算出生数已查看相对频率;3。按性别和年度进行聚合,并按年度进行规范化处理