CDH集群安装&测试总结
0.绪论
之前完全没有接触过大数据相关的东西,都是书上啊,媒体上各种吹嘘啊,我对大数据,集群啊,分布式计算等等概念真是高山仰止,充满了仰望之情,觉得这些东西是这样的:

当我搭建的过程中,发现这些东西是这样的:

对于初学者来说,我认为缺点如下:
- 1.需要控制,配置的东西太多,并且配置对应并不是很清晰(以后优化集群是否会有很高含金量?)
- 2.整个集群,我觉的从硬件到软件整体来说还是稳定性有待提高,尤其CDH 集群这块一会这个主机失去联系,一会NameNode挂,一会monitor挂,整个使用过程就是在不断的挂,看日志,挑错。基本离自动化,智能化还有很大距离。
CDH集群测试主要包括以下几个方面的内容:
1.装机(pxe),搭建服务器集群基础环境
2.安装CDH集群,调试集群的健康状况,使集群可用
3.测试集群性能,优化集群,使用测试框架(如Intel的HiBench框架)测试集群性能
1.基础建设简称基建
上一篇文章,我们已经介绍了集群安装操作系统的大杀器:
pxe无人值守安装linux机器笔记
在批量安装完毕系统之后,本节主要围绕搭建CDH集群的基础建设进行介绍,基础建设简称基建,主要是为了支撑CDH集群后序工作流畅进行的一系列Linux系统的设置工作,基础建设工作没有做好,后面安装使用集群过程中会出现很多莫名奇妙的错误。基建主要包括,免密登录,时间同步,格式化硬盘,挂载目录等一些设置,下面为大家分别介绍:
1.1 建立主机分发脚本
新建一个host文件里面逐行设置为主机ip
eg.
192.168.1.1
192.168.1.2
192.168.1.3
新建一个自定义脚本文件:
#!/bin/sh
host= `cat host`
for i in $host
do
echo $i
#将需要分发的命令复制在此处
Done
1.2 免密码登陆
配置免密码登录
1. 执行ssh-keygen命令,点击两次“回车”,生成/root/.ssh/id_rsa.pub文件;(使用脚本分发下面两条命令)
2. cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
3. scp -r /root/.ssh $hostname:/root/
1.3 配置主机基础环境
-
修改默认语言为英文
vi /etc/sysconfig/i18n
LANG=”en_US.UTF-8” -
修改host文件
scp /etc/hosts root@$i:/etc
-
关闭防火墙以及SELinux
ssh $i ‘service iptables stop’
ssh $i ‘chkconfig iptables off’
ssh $i ‘service ip6tables stop’
ssh $i ‘chkconfig ip6tables off’
ssh $i ‘setenforce 0’
ssh $i ‘echo ‘service iptables stop’ >> /etc/rc.local’
ssh $i ‘echo ‘service ip6tables stop’ >> /etc/rc.local’
ssh $i ‘sed -i ‘s/SELINUX=enforcing/SELINUX=disabled/g’ /etc/selinux/config’ -
同步时间 启动ntp服务,每5分钟向服务器同步一次(还需修改时间服务器上的部分配置,具体请百度)
ssh $i ‘cat >>/var/spool/cron/root << EOF
*/5 * * * * /usr/sbin/ntpdate serverIP> /dev/null 2>&1
EOF’
ssh $i ‘echo ‘SYNC_HWCLOCK=yes’ >> /etc/sysconfig/ntpd’
ssh $i ‘hwclock -w’ -
修改用户句柄限制
ssh $i ‘cat >> /etc/security/limits.conf << EOF
hadoop soft nofile 65000
hadoop hard nofile 65000
hadoop soft nproc 401408
hadoop hard nproc 401408
* soft nofile 65000
* hard nofile 65000
* soft nproc 401408
* hard nproc 401408
EOF’ -
建立挂载目录(根据自己的硬盘个数)
ssh $i ‘mkdir /data01 /data02 /data03 /data04 /data05 /data06 /data07 /data08 /data09 ‘
-
格式化硬盘(需批量执行,此处脚本有待升级)
ssh $i
‘yes|parted /dev/sdb mklabel gpt
parted /dev/sdb mkpart primary 0% 100%
mkfs.ext4 -T largefile /dev/sdb1 -
修改/etc/fstab文件
ssh $i ‘cat >> /etc/fstab << EOF
/dev/sdb1 /data01 ext4 defaults,noatime 0 0 -
挂载目录
ssh $i
‘mount /dev/sdb1 /data01 -
关闭swap交换分区
ssh $i ‘swapoff -a’
ssh $i ‘sysctl -w vm.swappiness=0’
ssh $i ‘echo ‘vm.swappiness=0’ >> /etc/sysctl.conf’ -
关闭大内存页面
ssh $i ‘cat >> /sys/kernel/mm/transparent_hugepage/defrag << EOF
never
EOFssh $i ‘cat >> /etc/rc.local << EOF
echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
EOF -
卸载自带的java环境,可以根据自己的java版本卸载
检查集群机器是否安装过openJDK,如果有安装过,请卸载,执行命令 :rpm -qa | grep jdk
rpm -e xxx #xxx为上一步输出的rpm包名ssh $i
‘rpm -e –nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
rpm -e –nodeps java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
rpm -e –nodeps java-1.6.0-openjdk-devel-1.6.0.0-1.66.1.13.0.el6.x86_64
rpm -e –nodeps java-1.6.0-openjdk-javadoc-1.6.0.0-1.66.1.13.0.el6.x86_64’ -
安装pscp和scala包
ssh $i ‘rpm -i /root/rpms/pssh-2.3.1-5.el6.noarch.rpm /root/rpms/scala-2.10.4.rpm’
-
配置java1.8.0_66环境
scp -r /usr/java/jdk1.8.0_66 root@$i:/usr/java/
ssh $i ‘rm -rf /usr/java/lastest’
ssh $i ‘ln -s /usr/java/jdk1.8.0_66 /usr/java/lastest’ssh $i ‘cat >> /etc/profile << EOF
JAVA_HOME=/usr/java/jdk1.8.0_66
CLASS_PATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar
export JAVA_HOME
PATH=\$HOME/bin:\$JAVA_HOME/bin:\$PATH
export PATH
export CLASS_PATH
EOF’scp /etc/profile root@$i:/etc/
ssh $i ‘source /etc/profile’done
-
时间同步
ssh $i ‘service ntpd stop
ntpdate lcgm2
ssh $i ‘hwclock -w’
ssh $i ‘chkconfig ntpd on’
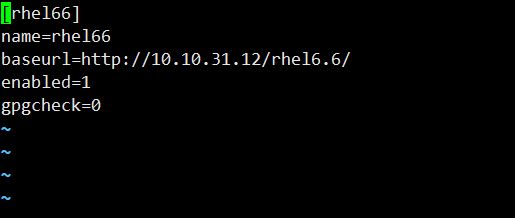
done 配置yum源,开启http服务
Yum源先mount在var/www/html/下面,在
/etc/yum.repos.d/rhel-source.repo文件修改内容
一些可能用到的命令:
建立多级目录: mkdir -p /x/xx
查看系统是否开启cloudera相关服务:chkconfig –list|grep cloudera
查看eth0网卡网络速度:ethtool eth0|grep -i speed
1.4 绑定网卡
决定集群性能很大因素是集群的网络性能呢,所以一般大数据集群都是多个网卡绑定的bond0模式,绑定shell如下
nmcli命令可能需要NetworkManager服务来支撑
ifconfig
systemctl stop firewalld.service
service iptables stop
setenforce 0
nmcli con add type bond con-name bond0 ifname bond0 mode 0
nmcli con add type bond-slave con-name bondeno1 ifname eno1 master bond0
nmcli con add type bond-slave con-name bondeno2 ifname eno2 master bond0
nmcli con add type bond-slave con-name bondeno3 ifname eno3 master bond0
nmcli con add type bond-slave con-name bondeno4 ifname eno4 master bond0
cd /etc/sysconfig/network-scripts/
vim ifcfg-bond0
BOOTPROTO=static
IPADDR=192.168.*.*
PREFIX=24
GATEWAY=192.168.*.*
service network restart
nmcli con reload
nmcli con up bondeno4
nmcli con up bondeno1
nmcli con up bondeno2
nmcli con up bondeno3
nmcli con up bond02.安装配置Cloudera-Manager(离线)
在线安装方式由于需要安装的安装包过大,时间可能非常长,建议大家下载安装包进行离线安装。主要安装Cloudera Manager Server 和Agent。
2.1 离线仓库安装准备
在cloudrea下载离线仓库,下载地址
下载cm5:
https://archive.cloudera.com/cm5/repo-as-tarball/5.8.0/cm5.8.0-centos6.tar.gz
下载cdh5:
https://archive.cloudera.com/cdh5/parcels/5.8.0/
列表:
CDH-5.8.0-1.cdh5.8.0.p0.42-el6.parcel
CDH-5.8.0-1.cdh5.8.0.p0.42-el6.parcel.sha1
manifest.json
下载验证:https://archive.cloudera.com/cm5/redhat/6/x86_64/cm/5.8.0/repodata/
下载安装脚本:
http://archive.cloudera.com/cm5/installer/latest/cloudera-manager-installer.bin
2.2 主节点解压安装
cloudera manager的目录默认位置在/opt下,解压:tar xzvf cloudera-manager*.tar.gz将解压后的cm-5.*和cloudera目录放到/opt目录下(类似在windows把软件安装在D:/software)。
为Cloudera Manager 5建立数据库,可以用Mysql,或者自带的postgresql ,本文采用自带的数据库进行测试。
配置离线仓库地址:
- 开启apache服务:service httpd start
- 将下载的cloudera仓库移到/var/www/html目录下,调整目录结构:
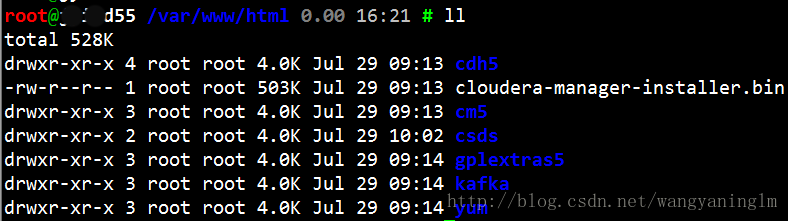
cdh5目录结构:

cm5目录结构:

chmod u+x cloudera-manager-installer.bin,然后./*.bin该文件相关启动脚本,就可以进入安装界面进行安装啦。
service cloudera-scm-server start (这个启动有点慢,可以关注日志变动情况 )
service cloudera-scm-agent start
其中,日志所在路径是
/var/log/cloudera-scm-server/cloudera-scm-server.log
启动server后,使用:
/sbin/iptables -I INPUT -p tcp –dport 7180 -j ACCEPT ( 打开7180端口 )
2.3 配置集群
- 1.根据CM引导界面,用户名admin ,密码admin。选择Cloudera Express 免费版。点击下一步到为CDH集群安装指定主机。

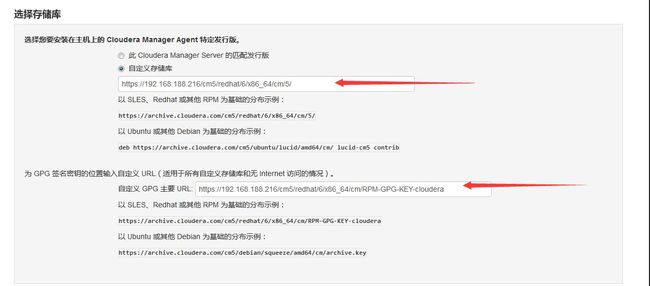
2.输入需要安装集群的机器IP地址,包括Cloudera Manager Server 机器。
3.选择集群的安装方式,选择使用数据包,CDH版本选择自定义,并输入yum源地址(基建中已经配置了的)

(上图链接地址https可能会出错)
升级过程中遇到的问题
提示Error Cannot retrieve repository metadata [repomod.xml] for cloudera-cdh5.Please verify its path and try again
(1) 检查机器的yum及cloudera的yum源配置是否正确
(2) 在Cloudera升级步骤(5)中填写的apache上cm5包地址是否正确,协议应该使用http而不是https,不然就会出现这种错误
(3) 若没有显示本地parcel包,可能是路径填写错误,可以根据配置的远程yum地址重新填写。
4.集群安装状态,可以看到每台集群的安装状态,如果正常则进入下一步。
5.选择要安装的CDH组件,我们选择安装HBase、HDFS、Hive、Spark、YARN、Zookeeper服务。点击继续(hibench测试主要需要这几个组件),角色服务分配参考如下:
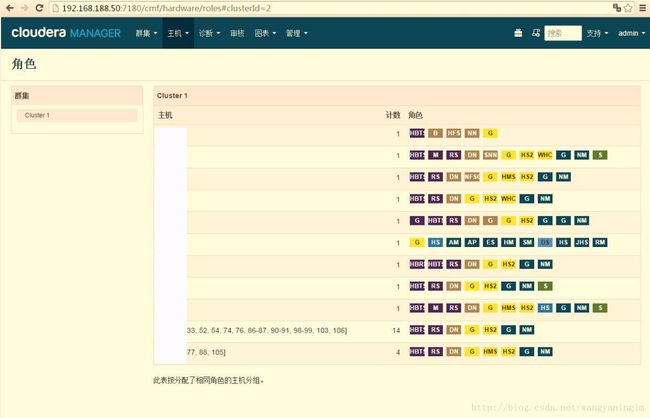
- 6. CM会检测安装环境,可能会提示一处安装警告,比如:
cloudera 建议将/proc/sys/vm/swappiness设置为0,当前设置为60,
则我们需要在集群每台机器上执行命令:
echo 0> /proc/sys/vm/swappiness
王道就是有错就看日志调试。 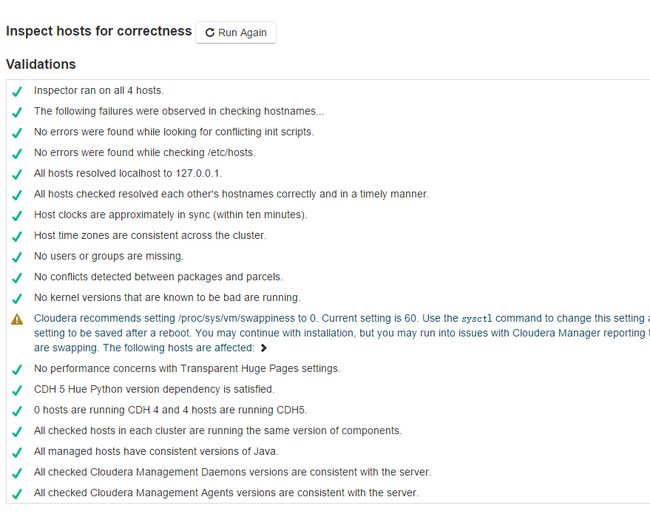
7.选择集群机器的角色分配,对于默认的选择都可以选择在Master机器上,当然像Second NameNode可以选择在非NameNode机器上。注意Cloudera Management Service都选Master。
8.数据库配置。根据创建数据表选择所对应的服务即可。
9.集群设置。选择默认,集群开始安装,完成,访问集群serverIP:7180/cmf,ok。
2.4 集群基本优化
2.4.1 关闭Linux THG服务
检查集群中的各个主机的THG(对虚拟化等的内存资源分配是有好处的,但是对hadoop离线计算IO密集型操作是没有优势的,关闭THG可加快处理速度)
-
1.查看THG
cat /sys/kernel/mm/redhat_transparent_hugepage/defrag
-
2.关闭THG
echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
2.4.2 设置linux内核参数:vm.swappiness
vm.swappiness值的范围为0~100,作用是控制应用数据在物理内存和虚拟内存之间的交换,值越低,交换的越少。默认值为60。
查看集群各个主机的此参数值:
cat /proc/sys/vm/swappiness
建议调整值为1:
sysctl -w vm.swappiness=1
2.4.3 配置HDFS
点击HDFS -> 配置 -> 高级:hdfs-site.xml 的 HDFS 服务高级配置代码段(安全阀),加入配置使用公平队列
<property>
<name>ipc.8020.callqueue.implname>
<value>org.apache.hadoop.ipc.FairCallQueuevalue>
property>2.4.4 配置Yarn资源
关于Yarn内存分配与管理,主要涉及到了ResourceManage(集群资源调度协调)、ApplicationMatser(任务资源配置)、NodeManager(YARN节点代理配置)这几个概念,相关的优化也要紧紧围绕着这几方面来开展。
点击Yarn -> 资源管理:
设置ApplicationMaster Java最大堆栈:800M(AM内存默认1G)
容器内存yarn.nodemanager.resource.memory-mb
计算一个节点需要分配的容器内存方法:
主机内存-操作系统预留内存(12G) - Cloudera Manager Agent(1G) - HDFS DN(1G) – Yarn NM(1G)
= 主机内存-15G
如果安装了hive.需减掉12G左右内存.
如果安装了hbase.还需减掉12-16G内存。
如果安装impala.还需减掉至少16G内存。
例:64G内存主机,如果安装了hbase,hive,则建议分配的容器内存大约为:25~30G
容器虚拟CPU内核yarn.nodemanager.resource.cpu-vcores
计算一个节点需要分配的容器虚拟内核方法:
(主机cpu核数 – 系统预留1 – Cloudera1 – HDFS1 – Yarn NN 1) * 4
Hbase : -1
例:24核机器,为yarn分配可用cpu核数大约20核左右,按照 核数:处理任务数=1:4(比例可酌情调整),建议分配为80。由于本次集群CPU计算能力没达到官网建议的比例的要求,大约分配的比例为1:2,分配的核数为30核左右。高级配置中:mapred-site.xml 的 MapReduce 客户端高级配置代码段(安全阀)
<property>
<name>mapreduce.tasktracker.outofband.heartbeatname>
<value>truevalue>
property>2.4.5 配置oozie
点击oozie –> 配置 -> 高级 : oozie-site.xml 的 Oozie Server 高级配置代码段(安全阀),增加配置:
<property>
<name>oozie.launcher.fs.hdfs.impl.disable.cachename>
<value>truevalue>
property>
<property>
<name>oozie.action.max.output.dataname>
<value>5000000value>
property>2.4.6 配置Oozie HA(用HAproxy负载均衡)
- Web界面操作略
- error:
Oozie could not be start
REASON:java.lang.noSuchFieldError:EXTERNAL_PROPERTY
ERROR: java.lang.noSuchFieldError:EXTERNAL_PROPERTY
Org.cod… jaskson…
导致上面错误是oozie的jaskson版本低,替换成1.9.13版本即可
只替换jackson-mapper-asl和jackson-core-asl即可
替换步骤:
1.
先将192.168.188.13的两jar包拷贝到/opt/cloudera/parcels/CDH/lib/oozie下
2.
find . -name “jackson*” | grep -e “^./lib” | xargs -i dirname {} | sort |uniq | xargs -i cp jackson-* {}
3.
find . -name “jackson*” | grep -e “^./lib” | xargs -i dirname {} |sort | uniq | xargs -i mv {}/jackson-mapper-asl-1.8.8.jar .
4.
find . -name “jackson*” | grep -e “^./lib” | xargs -i dirname {} |sort | uniq | xargs -i mv {}/jackson-core-asl-1.8.8.jar .
2.4.7 其他优化
1.DRF策略
CDH集群调优:内存、Vcores和DRF
默认配置下,CPU核数和内存是1:1G的比例来启动任务的。可通过调整参数yarn.nodemanager.resource.memory-mb进行调整
2.每个container的分配多少内存和cpu
当应用程序向resource manager 申请资源(即申请container )时, RM分配给一个container 多大的内存是按照一个最小单位进行分配的。 例如, 我们设置分配的最小单位为4GB, 则RM分配出来的container的内存一定是4G的倍数。 假设现在有一个程序向RM申请 5.1G的内存, 则RM会分配给它一个8GB的container去执行。
yarn.scheduler.minimum-allocation-mb=4096
在实际执行map reduce的job中, 一个container实际上是执行一个map 或者reduce task的jvm的进程。 那么这个jvm在执行中会不断的请求内存,假设它的物理内存或虚拟内存占用超出了container的内存设定, 则node manager 会主动的把这个进程kill 掉。
这里需要澄清一点, JVM使用的内存实际上分为虚拟内存和物理内存。 JVM中所有存在内存中的对象都是虚拟内存, 但在实际运行中只有一部分是实际加载在物理内存中的。 我们使用linux的top 可以看到 VM, RES, 前者是虚拟内存,后者可以看成近似是实际占用的物理内存。 因此在设置mapreduce的task的 jvm opts 参数时, 应将heap size 设置的比container允许的最大虚拟内存小。 这样jvm 不会因为申请过多的内存而被node manager 强制关闭。 当然设置最大heap size 如果在执行中被超过, jvm就会报 OutOfMemoryException。
同时还有一个参数,设定了RM可以分配的最大的container是多大。 假设应用程序向RM申请的资源超过了这个值, RM会直接拒绝这个请求。
yarn.scheduler.maximum-allocation-mb
3.HiBench集群性能测试
在大数据领域中,集群的性能很大程度上我认为主要是由整体的网络,数据吞吐量决定的,在使用HiBench测试时候发现,使用传统电口千兆网络的任务运行时间比光网任务运行时间要慢10s左右。HiBench的基准测试集是用来衡量一个大数据平台(基于Hadoop)性能的基准测试集,包含了文件系统的IO性能,系统的批处理吞吐,数据仓库用的OLAP分析算子,机器学习的处理能力,以及流处理系统的能力。
切换到光纤后,需要修改机器机器ip,这时候cdh居然没法启动了,百度之后,发现如果使用自带数据库postgresql,需要修改hosts表中记录的元数据信息:修改CDH集群ip
3.1 简介
hibench作为一个测试hadoop的基准测试框架,提供了对于hive:(aggregation,scan,join),排序(sort,TeraSort),大数据基本算法(wordcount,pagerank,nutchindex),机器学习算法(kmeans,bayes),集群调度(sleep),吞吐(dfsio),以及新加入5.0版本的流测试:
we provide following streaming workloads for SparkStreaming, Storm . 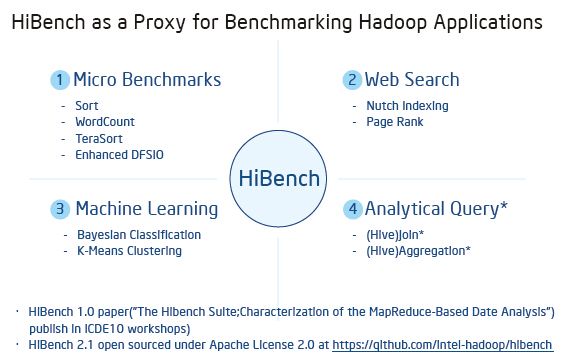
一个完整的TeraSort测试需要按以下三步执行:
- 用TeraGen生成随机数据
- 对输入数据运行TeraSort
- 用TeraValidate验证排好序的输出数据
所有hibench测试基本都是这样的流程,生成数据,运行,输出结果。
3.2 配置并编译HiBench
从GitHub下载HiBench开源包,本篇会基于HiBench-5.0为例。https://github.com/intel-hadoop/HiBench。如果是基于CDH 5.5测试,建议使用HiBench-5.0,其中包含了Spark 1.5的编译包。
编译
- 添加JAVA_HOME 环境变量
- 注释掉${HIBENCH_HOME} /src/streambench/pom.xml中两行
- 调用编译脚本:${HIBENCH_HOME}/bin/build-all.sh
配置
-
编辑 HiBench Configuration File:
cd ${HIBENCH_HOME}/conf
cp 99-user_defined_properties.conf.template 99-user_defined_properties.conf
编译配置文件,如下修改一些参数:
hibench.hadoop.home /opt/cloudera/parcels/CDH/lib/hadoop
hibench.hadoop.mapreduce.home /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce
hibench.spark.home /opt/cloudera/parcels/CDH/lib/spark
hibench.hdfs.master hdfs://cdh-node-11.cdhtest.com
hibench.hadoop.configure.dir /etc/hadoop/conf
hibench.masters.hostnames master # Resource Manager addresses
hibench.slaves.hostnames hostname…# Node Manager addresses
hibench.spark.master yarn-client
hibench.spark.version spark1.6
spark.kryoserializer.buffer 2000m # 否则会出现大量spark.kryoserializer.buffer.mb被启用的警告
hibench.streamingbench.zookeeper.host zookeeper-hostnames
hibench.streamingbench.brokerList all-hostnames
hibench.streamingbench.kafka.home /opt/cloudera/parcels/KAFKA -
修改benchmarks.lst文件,只运行有必要的测试集,例:
#aggregation
#join
#kmeans
#pagerank
#scan
#sleep
sort
wordcount
#bayes
terasort
#nutchindexing
dfsioe -
修改language.lst文件,只运行有必要的语言
cd ${HIBENCH_HOME}/conf
在language.lst文件中,将以下两行删除
spark/java
spark/python -
修改load-config.py文件,确保Bench在运行时能找到唯一的包:
$HiBench-Home/bin/functions/load-config.py
将hadoop-mapreduce-client-jobclient*-tests.jar改为hadoop-mapreduce-client-jobclient-tests.jar
-
Bench在运行时有一些固化的目录和CDH不一致,需要建立目录引用
建立目录引用
mkdir -p /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/share/hadoop
cd /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/share/hadoop
ln -sf /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce mapreduce2 -
Bench会在HDFS根目录下生成文件,将HDFS的根目录权限修改为777:
sudo -u hdfs hadoop fs -chmod 777 /
-
(可选)如果在Kerberos启用的状况下,请增加以下步骤:
# 设置环境变量
export HIBENCH_HOME=/root/Downloads/HiBench-master
export JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera
export JAVA_LIBRARY_PATH=$JAVA_LIBRARY_PATH:/opt/cloudera/parcels/CDH/lib/hadoop/lib/native
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/cloudera/parcels/CDH/lib/hadoop/lib/native
export SPARK_YARN_USER_ENV=”JAVA_LIBRARY_PATH=$JAVA_LIBRARY_PATH,LD_LIBRARY_PATH=$LD_LIBRARY_PATH”# 重新登录Kerberos
kdestroy
kinit -k -t
运行
- 命令行输入
${HIBENCH_HOME}/bin/run-all.sh
3.3 HiBench基本优化配置
**优化基本原则** 在固定数据量的前提下,一般设置成让MapReduce作业在一轮Map、Reduce内结束,否则会增加MapReduce进程的调度开销。但如果输入的数据量过大,有可能会因为单个Map或者Reduce的内存消耗过大而到时严重的GC问题,这个需要在运行时对Map或者Reduce任务进程需要监测。 **YARN基本配置**| – | – |
|---|---|
| NodeManager | Container vCores数量就是系统的virtual core的数量 Container Memory配置成节点上可用内存的75%到80%之间(如128GB的机器,可以设置96GB) |
| ResourceManager | Fair Scheduler调度器 最小容器内存1GB 最小容器CPU 1个核 最大容器内存=NodeManager Container内存的75%~80% 最大容器CPU=NodeManager Container CPU的75%~80% 增量内存512MB 增量CPU 1个核 |
| Gateway | mapreduce.map/reduce.max.mb = 2GB mapreduce.map/reduce.java.opts = max.mb * 0.8 |
附录(CDH 相关目录结构功能简介)
**1.相关目录****2.配置**/var/log/cloudera-scm-installer : 安装日志目录。
/var/log/* : 相关日志文件(相关服务的及CM的)。
/usr/lib64/cmf/ : Agent程序代码。
/var/lib/cloudera-scm-server-db/data : 内嵌数据库目录。
/usr/bin/postgres : 内嵌数据库程序。
/etc/cloudera-scm-agent/ : agent的配置目录。
/etc/cloudera-scm-server/ : server的配置目录。
/etc/clouder-scm-server/db.properties 默认元数据库用户名密码配置
/opt/cloudera/parcels/ : Hadoop相关服务安装目录。
/opt/cloudera/parcel-repo/ : 下载的服务软件包数据,数据格式为parcels。
/opt/cloudera/parcel-cache/ : 下载的服务软件包缓存数据。
/etc/hadoop/* : 客户端配置文件目录。
- Hadoop配置文件:
配置文件放置于/var/run/cloudera-scm-agent/process/目录下。如:
/var/run/cloudera-scm-agent/process/193-hdfs-NAMENODE/core-site.xml
这些配置文件是通过Cloudera Manager启动相应服务(如HDFS)时生成的,内容从数据库中获得(即通过界面配置的参数)。
在CM界面上更改配置是不会立即反映到配置文件中,这些信息会存储于数据库中,等下次重启服务时才会生成配置文件。且每次启动时都会产生新的配置文件。
CM Server主要数据库为scm基中放置配置的数据表为configs。里面包含了服务的配置信息,每一次配置的更改会把当前页面的所有配置内容添加到数据库中,以此保存配置修改历史。
scm数据库被配置成只能从localhost访问,如果需要从外部连接此数据库,修改
vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf
文件,之后重启数据库。运行数据库的用户为cloudera-scm。
- 查看配置内容
直接查询scm数据库的configs数据表的内容。
访问REST API: http://hostname:7180/api/v4/cm/deployment,返回JSON格式部署配置信息。
- 配置生成方式
CM为每个服务进程生成独立的配置目录(文件)。所有配置统一在服务端查询数据库生成(因为scm数据库只能在localhost下访问)生成配置文件,再由agent通过网络下载包含配置文件的zip包到本地解压到指定的目录。
-
配置修改
CM对于需要修改的配置预先定义,对于没有预先定义的配置,则通过在高级配置项中使用xml配置片段的方式进行配置。而对于/etc/hadoop/下的配置文件是客户端的配置,可以在CM通过部署客户端生成客户端配置。数据库
Cloudera manager主要的数据库为scm,存储Cloudera manager运行所需要的信息:配置,主机,用户等。CM结构
CM分为Server与Agent两部分及数据库(自带更改过的嵌入Postgresql)。它主要做三件事件:
管理监控集群主机。
统一管理配置。
管理维护Hadoop平台系统。
实现采用C/S结构,Agent为客户端负责执行服务端发来的命令,执行方式一般为使用python调用相应的服务shell脚本。Server端为Java REST服务,提供REST API,Web管理端通过REST API调用Server端功能,Web界面使用富客户端技术(Knockout)。
Server端主体使用Java实现。
Agent端主体使用Python, 服务的启动通过调用相应的shell脚本进行启动,如果启动失败会重复4次调用启动脚本。
Agent与Server保持心跳,使用Thrift RPC框架。升级
在CM中可以通过界面向导升级相关服务。升级过程为三步:
1.下载服务软件包。
2.把所下载的服务软件包分发到集群中受管的机器上。
3.安装服务软件包,使用软链接的方式把服务程序目录链接到新安装的软件包目录上。卸载
sudo /usr/share/cmf/uninstall-scm-express.sh, 然后删除/var/lib/cloudera-scm-server-db/目录,不然下次安装可能不成功。开启postgresql远程访问
CM内嵌数据库被配置成只能从localhost访问,如果需要从外部查看数据,数据修改vim /var/lib/cloudera-scm-server-db/data/pg_hba.conf文件,之后重启数据库。运行数据库的用户为cloudera-scm。
参考文献
1.CDH官方文档
2.http://www.cloudera.com/documentation.html
3.CDH5.8官方文档 http://www.cloudera.com/documentation/enterprise/latest.html
4.http://blog.selfup.cn/1631.html#comment-403
5.https://github.com/intel-hadoop/HiBench