这篇文章于去年4月发布在我的简书,现在把它放到这里,主要是为了宣传自己的分布式微博爬虫。下面是主要内容,希望能帮到有这个需求的朋友
最近由于需要一直在研究微博的爬虫,第一步便是模拟登陆,从开始摸索到走通模拟登陆这条路其实还是挺艰难的,需要一定的经验,为了让朋友们以后少走点弯路,这里我把我的分析过程和代码都附上来。
首先,我们先用正常的账号登陆,具体看会有些什么请求。这里我用的是Http Analyzer抓包(Filders也是一个不错的选择)。下面是正常登陆流程的截图:

接下来我会详细说明各个过程。
第一步:预登陆。
现在微博、空间等大型网站在输入用户名后基本都会做编码或者加密处理,这里在用户名输入框输入我的账号,通过抓包工具可以看到服务器会返回一段字符串:
![]()
这一步就是预登陆过程,同学们可以自己试试。登陆的时候我们需要用到其中的servertime、nonce、pubkey等字段。当然这个不是我自己猜想的,后面的步骤会做说明。
还有一点,就是预登陆的url:
http://login.sina.com.cn/sso/...
这里su的值是自己用户名经过base64编码的值。但可能你们会问我是如何知道的呢,待会儿我会讲到。经过实测,如果我们这里不给su传参数,其实也是可以的。为了最真实的模拟用户登录,我们最好还是带上它的值。
请看图一的第一条js请求http://i.sso.sina.com.cn/js/ssologin.js,同学们可以点进去看,这个就是前面提到的加密用户名和密码等一系列的加密文件了,如果有同学非要问我是怎么找到这个加密文件的,我也只有说:反复抓包,从在浏览器输入weibo.com过后就找js文件请求路径,然后再用代码格式化工具打开,挨着一个一个看,在代码中搜关键字,比如这里我们可以搜"nonce"、“servertime”等,就能找到加密文件了。
打开加密文件我们可以看到加密用户名的代码,在加密js文件中搜索'username',可以看到有一行代码为:
username = sinaSSOEncoder.base64.encode(urlencode(username))
现在我们可以直接查找encode方法(代码太多就不贴上来了),即可查找到对应方法了,为了验证我们的猜想,我们可以在webstorm中copy这个encode函数带上自己的用户名运行,返回的结果就是su的值,这个值在之后进行post提交的时候也会用到。如果对加密有一定经验的同学可能一眼就会看出这个是base64编码,python中有个base64模块可以干这个事情。我们再回到图一,http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)这个地址就是进行post提交数据的地址,下面是我自己提交的数据:

这里我们需要自己构造su(加密后的用户名),sp(加密后的密码),servertime,nonce,rsakv等数据,其它数据都不用变。有同学问我为哈其它数据不用变?你自己可以多登陆几次,看变化的值,那么那些值就是需要构造的值,其它值就直接拿过来用就行了。这里的su,servertime,nonce,rsakv都已经拿到了,所以当前需要的就只是sp的值了。我们还是按照原来的方法在js文件中查找“sp”,可以找到requests.sp=password这段代码,所以我们就只需要看password怎么构造的了。通过查找可以看到关键加密代码:
password = RSAKey.encrypt([me.servertime,me.nonce].join("t") +"n"+ password)
这一段代码便是加密密码的代码,有经验的同学一看就知道是用的RSA加密,python中也有相应的rsa加密库可用。但是我们假设大家都没看出来或者不知道python中有rsa这个第三方库。这时候就要给大家介绍一些我的经验了,我现在已经知道的有三种模拟登陆方案:
a)最简单暴力,效率也是最高的,直接把js源码转化为相应的python代码,模拟加密流程进行加密
b)使用selenium+phantomjs/firefox的方案直接模拟人的操作填写表单提交数据进行模拟登陆,这种方式最为简单,效率稍微低一些。如果有同学对这种简单暴力的方式感兴趣,可以到我的github上查看一下源码
c)比较折中的方案,通过pyv8/pyexecjs等渲染js代码进行执行,本文主要就是讲的这种方式。第一种方式如果是遇到微博调整了登陆加密算法,就必须改加密代码,第二种方式和第三种方式不存在这个问题。
由于我用的是Python3,并不支持PyV8,所以我选了和它类似的PyexecJS,这个也可以直接执行js代码。我也不是很熟悉Javascript代码,所以我直接定义了一个函数处理加密密码,并没对其加密源代码修改太多:
function get_pass(mypass,nonce,servertime,rsakey){
varRSAKey = newsinaSSOEncoder.RSAKey();
RSAKey.setPublic(rsakey,"10001");
password= RSAKey.encrypt([servertime,nonce].join("\t") +"\n"+ mypass)
return password
}
这个函数中的东西其实就是copy的加密文件的加密过程代码。为了试验,我直接使用之前自己登陆抓到的nonce、servertime、rsakey等数据,在webstorm中调用这个函数,但是报错了,提示"navigator is undefined",webstorm 使用的nodejs的运行时环境,而navigator为浏览器的某个属性,所以运行会出问题。于是我就是用phantomjs来作为运行时环境.考虑到有同学不知道phantomjs怎么使用,这里我简要说一下吧。使用windows的同学先要去phantomjs官网下载它的可执行文件,然后设置环境变量。在命令行输入"phantomjs some.js"即可执行some.js文件,其实就和在命令行执行python或者java文件一样,如果不清楚的可以百度执行命令行执行python的方法,仿照着来就可以了,再不清楚就问我。使用ubuntu的同学可以直接用sudo apt-get install phantomjs,就可以安装使用了。我直接把加密的js文件使用phantomjs运行,果然好着呢。原因是因为phantomjs其实就是一款无ui的浏览器,自然支持navigator、window等属性。而pyexecjs支持使用phantomjs作为运行时环境,具体用法pyexecjs的git主页有,我也在代码中有所体现。
with open('G:/javascript/sinajs.js','r') as f:
source = f.read()
phantom = execjs.get('PhantomJS')
getpass = phantom.compile(source)
mypass = getpass.call('get_pass',my_pass,nonce,servertime,pubkey)
这段代码就可以得到加密过后的密码了。
之后,便可以进行post提交,提交地址可以从抓包工具看到:http://login.sina.com.cn/sso/...。
根据经验,到这里过程基本就完了。但是微博有点坑啊,这里还需要有一步,就是图一所示的类似
http://passport.weibo.com/wbs...,
这一步会将请求重定向,返回当前账号的登陆信息,如下图:

那么问题来了,怎么获取上面的请求地址呢。分析上面地址,有ticket字段,这个应该是让你登陆的凭据,所以这个地址应该是服务端返回的,如果不是,起码ticket是服务端返回的,于是我们又使用抓包工具查看在请求这段url之前返回的信息,发现有和上述url吻合的信息:
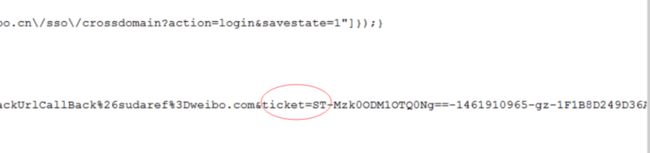
这段代码是使用post后回复的内容,所以可以直接从中提取出我们需要的url。然后再使用get方式请求上述的url,它会经历一次重定向,直接返回登陆信息。这个时候,就代表成功登陆了。
PS:授人以鱼不如授人以渔,这是我一直秉承的信念。可能有的老手觉得我写得很啰嗦,但其实很多新手可能都不知道这些细节,所以我把我在分析新浪微博模拟登陆的过程全写了出来。另外,除了这种方式,本文提到的另外两种方式也有实现。最暴力的方式需要使用rsa这个第三方库,具体我在代码上有详细注释,还有一种是使用selenium+phantomjs这种方式,我也在代码中关键地方有注释,如果想看看具体过程,可以点击这里(我的个人博客)查看分析过程。
Talk is cheap,show me the code!
最后奉上本文的所有方式的模拟登陆代码(如果觉得喜欢或者看了对你有帮助,不妨在github上给个star,也欢迎fork)
代码链接:smart_login,欢迎fork和star
看了本文还没看够?那么推荐你查看超详细的Python实现百度云盘模拟登陆,该文会从另外一个角度来谈模拟登陆
此外,打一个广告,如果对如何构建分布式爬虫或者大规模微博数据采集感兴趣的话,可以专注一下我的开源分布式微博爬虫项目,目前还在快速迭代,单从功能角度来讲,抓取部分基本上快实现和测试完了。