2019独角兽企业重金招聘Python工程师标准>>> 

li Eta
机器学习 话题的优秀回答者
316 人赞同了该回答
word embedding的意思是:给出一个文档,文档就是一个单词序列比如 “A B A C B F G”, 希望对文档中每个不同的单词都得到一个对应的向量(往往是低维向量)表示。
比如,对于这样的“A B A C B F G”的一个序列,也许我们最后能得到:A对应的向量为[0.1 0.6 -0.5],B对应的向量为[-0.2 0.9 0.7] (此处的数值只用于示意)
之所以希望把每个单词变成一个向量,目的还是为了方便计算,比如“求单词A的同义词”,就可以通过“求与单词A在cos距离下最相似的向量”来做到。
word embedding不是一个新的topic,很早就已经有人做了,比如bengio的paper“Neural probabilistic language models”,这其实还不算最早,更早的时候,Hinton就已经提出了distributed representation的概念“Learning distributed representations of concepts”(只不过不是用在word embedding上面) ,AAAI2015的时候问过Hinton怎么看google的word2vec,他说自己20年前就已经搞过了,哈哈,估计指的就是这篇paper。
总之,常见的word embedding方法就是先从文本中为每个单词构造一组features,然后对这组feature做distributed representations,哈哈,相比于传统的distributed representations,区别就是多了一步(先从文档中为每个单词构造一组feature)。
既然word embedding是一个老的topic,为什么会火呢?原因是Tomas Mikolov在Google的时候发的这两篇paper:“Efficient Estimation of Word Representations in Vector Space”、“Distributed Representations of Words and Phrases and their Compositionality”。
这两篇paper中提出了一个word2vec的工具包,里面包含了几种word embedding的方法,这些方法有两个特点。一个特点是速度快,另一个特点是得到的embedding vectors具备analogy性质。analogy性质类似于“A-B=C-D”这样的结构,举例说明:“北京-中国 = 巴黎-法国”。Tomas Mikolov认为具备这样的性质,则说明得到的embedding vectors性质非常好,能够model到语义。
这两篇paper是2013年的工作,至今(2015.8),这两篇paper的引用量早已经超好几百,足以看出其影响力很大。当然,word embedding的方案还有很多,常见的word embedding的方法有:
1. Distributed Representations of Words and Phrases and their Compositionality
2. Efficient Estimation of Word Representations in Vector Space
3. GloVe Global Vectors forWord Representation
4. Neural probabilistic language models
5. Natural language processing (almost) from scratch
6. Learning word embeddings efficiently with noise contrastive estimation
7. A scalable hierarchical distributed language model
8. Three new graphical models for statistical language modelling
9. Improving word representations via global context and multiple word prototypes
word2vec中的模型至今(2015.8)还是存在不少未解之谜,因此就有不少papers尝试去解释其中一些谜团,或者建立其与其他模型之间的联系,下面是paper list
1. Neural Word Embeddings as Implicit Matrix Factorization
2. Linguistic Regularities in Sparse and Explicit Word Representation
3. Random Walks on Context Spaces Towards an Explanation of the Mysteries of Semantic Word Embeddings
4. word2vec Explained Deriving Mikolov et al.’s Negative Sampling Word Embedding Method
5. Linking GloVe with word2vec
6. Word Embedding Revisited: A New Representation Learning and Explicit Matrix Factorization Perspective
编辑于 2015-08-27
31610 条评论
分享
收藏感谢收起

知乎用户
218 人赞同了该回答
题主问的是embedding的含义,楼上几位的回答都是拿word embedding说了一通,也没解释出embedding的含义。我来说一下。
Embedding在数学上表示一个maping, f: X -> Y, 也就是一个function,其中该函数是injective(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)。那么对于word embedding,就是将单词word映射到另外一个空间,其中这个映射具有injective和structure-preserving的特点。
通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,那么该多维向量相当于嵌入到Y所属空间中,一个萝卜一个坑。
word embedding,就是找到一个映射或者函数,生成在一个新的空间上的表达,该表达就是word representation。
推广开来,还有image embedding, video embedding, 都是一种将源数据映射到另外一个空间
编辑于 2016-10-24
21811 条评论
分享
收藏感谢

李韶华
研究者
98 人赞同了该回答
(基于我之前做的一个slides编写。slides完整版:https://sites.google.com/site/shaohua03/intro-word-embedding.pdf )
词嵌入最粗浅的理解
o 词映射到低维连续向量(如图)
cat: (-0.065, -0.035, 0.019, -0.026, 0.085,…)
dog: (-0.019, -0.076, 0.044, 0.021,0.095,…)
table: (0.027, 0.013, 0.006, -0.023, 0.014, …)
o 相似词映射到相似方向 -- 语义相似性被编码了
o Cosine相似度衡量方向

词嵌入可以做类比题 o v(“国王”) – v(“王后”) ≈ v(“男”) – v(“女”) o v(“英国”) + v(“首都”) ≈ v(“伦敦”) o 反映出语义空间中的线性关系 o词嵌入编码了语义空间中的线性关系, 向量的不同部分对应不同的语义 o 质疑:然而并没有什么x用? o 两个句子: A含“英国”,“首都”,不含“伦敦”;B含“伦敦” o 所有词的词向量的和表示句子 o 两个句子仍会比较相似
相似词映射到相似方向:为什么 o 基本假设:“相似”词的邻居词分布类似 o 倒推:两个词邻居词分布类似 → 两个词语义相近 o 猫 宠物 主人 喂食 蹭 喵 o 狗 宠物 主人 喂食 咬 汪 o v(“猫”)≈v(“狗”) o Apple: tree red growth design music company engineering executive o v(“apple”)≈v(“orange”), v(“apple”)≈v(“microsoft”)
词嵌入的优点 传统one-hot编码: “天气”: (1,0,0…,0),“气候”: (0,1,0,…0) 权力/的/游戏: (1,0,0,1,1,0,0, …) 冰/与/火/之/歌: (0,1,1,0,0,1,1,…) o 维度高(几千–几万维稀疏向量),数据稀疏 o 没有编码不同词之间的语义相似性 o 难以做模糊匹配 词嵌入: o 维度低(100 – 500维), 连续向量,方便机器学习模型处理 o 无监督学习,容易获得大语料 o 天然有聚类后的效果 o 一个向量可以编码一词多义 (歧义的问题需另外处理) o 罕见词也可以学到不错的表示:“风姿绰约” ≈ “漂亮”
Word2vec 简介
o Mikolov 2013, Distributed Representations of Words and Phrases and their Compositionality
o 使用最广泛的词嵌入方法
o 速度快,效果好,容易扩展
o 原因:简单(Less is more)
Word2vec 模型
o 回归连结函数:
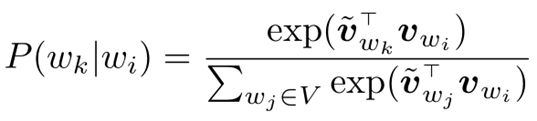
o (分母是归一化项,可暂时忽略)
o 和 方向相似: 预测的 大
方向不同: 预测的概率小
o 经常出现在周围, 大,驱使 和 指向相似方向
o 和 两套词向量,使用时只保留一套
o 没有耗时的矩阵乘,只留一个softmax变换,所以效率高
o 优化用随机梯度递降,罕见词不会主导优化目标
o 罕见词的统计数据噪音(随机性)很大;常用词的统计数据比较稳定,偏差很小
o 与之相对,基于矩阵分解的算法经常被罕见词主导优化目标,导致overfit噪音
编辑于 2017-06-30
988 条评论
分享
收藏感谢收起

YJango
日本会津大学 人机界面实验室博士在读
43 人赞同了该回答
YJango的Word Embedding--介绍 - 知乎专栏
该篇主要是讨论为什么要做word embedding:
gitbook阅读地址:Word Embedding介绍
目录
- 单词表达
- One hot representation
- Distributed representation
- Word embedding
- 目的
- 数据量角度
- 神经网络分析
- 训练简述
- 目的
至于word embedding的详细训练方法在下一节描述。
单词表达
先前在卷积神经网络的一节中,提到过图片是如何在计算机中被表达的。 同样的,单词也需要用计算机可以理解的方式表达后,才可以进行接下来的操作。
One hot representation
程序中编码单词的一个方法是one hot encoding。
实例:有1000个词汇量。排在第一个位置的代表英语中的冠词"a",那么这个"a"是用[1,0,0,0,0,...],只有第一个位置是1,其余位置都是0的1000维度的向量表示,如下图中的第一列所示。
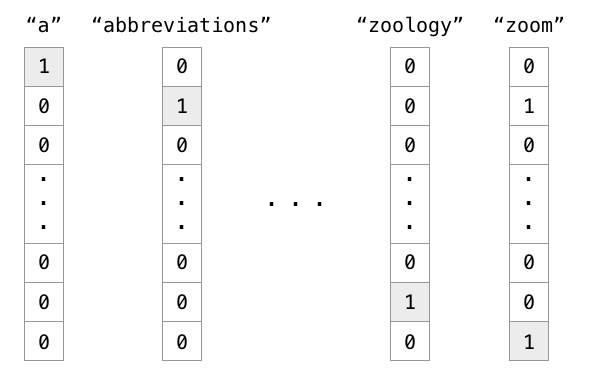
也就是说,
在one hot representation编码的每个单词都是一个维度,彼此independent。
Distributed representation
然而每个单词彼此无关这个特点明显不符合我们的现实情况。我们知道大量的单词都是有关。
语义:girl和woman虽然用在不同年龄上,但指的都是女性。
复数:word和words仅仅是复数和单数的差别。
时态:buy和bought表达的都是“买”,但发生的时间不同。
所以用one hot representation的编码方式,上面的特性都没有被考虑到。
我们更希望用诸如“语义”,“复数”,“时态”等维度去描述一个单词。每一个维度不再是0或1,而是连续的实数,表示不同的程度。
目的
但是说到底,为什么我们想要用Distributed representation的方式去表达一个单词呢?
数据量角度
这需要再次记住我们的目的:
机器学习:从大量的个样本 中,寻找可以较好预测未见过 所对应 的函数 。
实例:在我们日常生活的学习中,大量的 就是历年真题, 是题目,而 是对应的正确答案。高考时将会遇到的 往往是我们没见过的题目,希望可以通过做题训练出来的解题方法 来求解出正确的 。
如果可以见到所有的情况,那么只需要记住所有的 所对应的 就可以完美预测。但正如高考无法见到所有类型的题一样,我们无法见到所有的情况。这意味着,
机器学习需要从 有限的例子中寻找到合理的 。
高考有两个方向提高分数:
- 方向一:训练更多的数据:题海战术。
- 方向二:加入先验知识:尽可能排除不必要的可能性。
问题的关键在于训练所需要的数据量上。同理,如果我们用One hot representation去学习,那么每一个单词我们都需要实例数据去训练,即便我们知道"Cat"和"Kitty"很多情况下可以被理解成一个意思。为什么相同的东西却需要分别用不同的数据进行学习?
神经网络分析
假设我们的词汇只有4个,girl, woman, boy, man,下面就思考用两种不同的表达方式会有什么区别。
One hot representation
尽管我们知道他们彼此的关系,但是计算机并不知道。在神经网络的输入层中,每个单词都会被看作一个节点。 而我们知道训练神经网络就是要学习每个连接线的权重。如果只看第一层的权重,下面的情况需要确定4*3个连接线的关系,因为每个维度都彼此独立,girl的数据不会对其他单词的训练产生任何帮助,训练所需要的数据量,基本就固定在那里了。

Distributed representation
我们这里手动的寻找这四个单词之间的关系 。可以用两个节点去表示四个单词。每个节点取不同值时的意义如下表。 那么girl就可以被编码成向量[0,1],man可以被编码成[1,1](第一个维度是gender,第二个维度是age)。

那么这时再来看神经网络需要学习的连接线的权重就缩小到了2*3。同时,当送入girl为输入的训练数据时,因为它是由两个节点编码的。那么与girl共享相同连接的其他输入例子也可以被训练到(如可以帮助到与其共享female的woman,和child的boy的训练)。
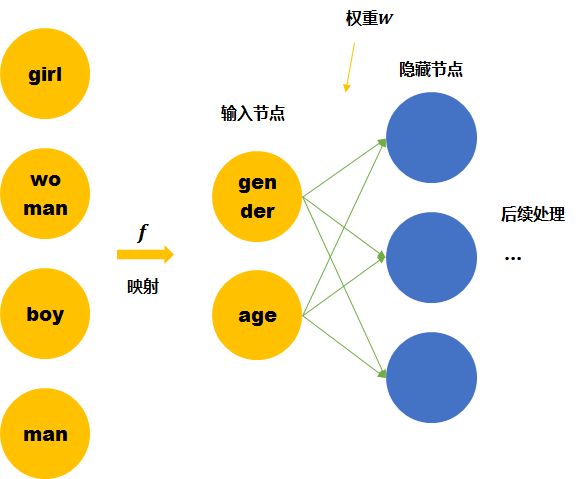
Word embedding也就是要达到第二个神经网络所表示的结果,降低训练所需要的数据量。
而上面的四个单词可以被拆成2个节点的是由我们人工提供的先验知识将原始的输入空间经过 (上图中的黄色箭头)投射到了另一个空间(维度更小),所以才能够降低训练所需要的数据量。 但是我们没有办法一直人工提供,机器学习的宗旨就是让机器代替人力去发现pattern。
Word embedding就是要从数据中自动学习到输入空间到Distributed representation空间的 映射 。
训练方法
问题来了,我们该如何自动寻找到类似上面的关系,将One hot representation转变成Distributed representation。 我们事先并不明确目标是什么,所以这是一个无监督学习任务。
无监督学习中常用思想是:当得到数据 后,我们又不知道目标(输出)时,
- 方向一:从各个输入 之间的关系找目标。 如聚类。
- 方向二:并接上以目标输出 作为新输入的另一个任务 ,同时我们知道的对应 值。用数据 训练得到 ,也就是 ,中间的表达 则是我们真正想要的目标。如生成对抗网络。
Word embedding更偏向于方向二。 同样是学习一个 ,但训练后并不使用 ,而是只取前半部分的 。
到这里,我们希望所寻找的 既有标签 ,又可以让 所转换得到的 的表达具有Distributed representation中所演示的特点。
同时我们还知道,
单词意思需要放在特定的上下文中去理解。
那么具有相同上下文的单词,往往是有联系的。
实例:那这两个单词都狗的品种名,而上下文的内容已经暗指了该单词具有可爱,会舔人的特点。
- 这个可爱的 泰迪 舔了我的脸。
- 这个可爱的 金巴 舔了我的脸。
而从上面这个例子中我们就可以找到一个 :预测上下文。
用输入单词 作为中心单词去预测其他单词 出现在其周边的可能性。
我们既知道对应的 。而该任务 又可以让 所转换得到的 的表达具有Distributed representation中所演示的特点。 因为我们让相似的单词(如泰迪和金巴)得到相同的输出(上下文),那么神经网络就会将泰迪的输入 和金巴的输入 经过神经网络 得到几乎相同的和泰迪的输出 和 金巴的输出 。
用输入单词作为中心单词去预测周边单词的方式叫做:Word2Vec The Skip-Gram Model。
用输入单词作为周边单词去预测中心单词的方式叫做:Continuous Bag of Words (CBOW)。
编辑于 2017-07-12
431 条评论
分享
收藏感谢收起
知乎用户
25 人赞同了该回答
竟然没人提分布式假设(distributional hypothesis)。
总的来说,word embedding就是一个词的低维向量表示(一般用的维度可以是几十到几千)。有了一个词的向量之后,各种基于向量的计算就可以实施,如用向量之间的相似度来度量词之间的语义相关性。其基于的分布式假设就是出现在相同上下文(context)下的词意思应该相近。所有学习word embedding的方法都是在用数学的方法建模词和context之间的关系。
如何得到word embedding?主要分为两种:基于矩阵分解和基于预测,可参见论文[1].
基于矩阵分解
- 首先基于语料库构建word context共现矩阵M,矩阵中每个单元可以是二值的表示是否二者共现,也可以是经过处理后的,如共现频率,共现的TF-IDF,共现的mutual information, point-wise mutual information和positive point-wise mutual information,还可以根据一些规则对单元值进行过滤(比如超过某个值后截断, Stanford的Glove用的这种方式[2]),等等。很多可衡量二个对象之间关联的指标都可以用来作为矩阵中每个单元的值。
- 得到矩阵之后,就可以进行矩阵分解,这里的矩阵分解可以是SVD分解 [4];,也可以是直接分解成两个子矩阵的形式,即M=AB [2]; 还可以是低秩矩阵分解。
基于矩阵分解(SVD)的方法我看到的最早的论文是1992年Schutze的文章[7].
这里如果不进行矩阵分解(降维),也可以得到一个词的向量表示(矩阵的行),只不过维度太高(词典大小),不方便计算。
基于预测
这种方法就是所谓的基于神经网络的方法了。其核心思想就是先用向量代表各个词,然后通过一个预测目标函数学习这些向量的参数。比如给定当前词预测窗口范围内的上下文词;给定周围几个词,预测中间这个词;给定前边几个词,预测下一个词(语言模型)。比如Bengio 2000年在NIPS上提出的neural language model [7],给定前n给词预测下一个词出现的概率;Hinton 2007年提出的用Restricted Boltzmann Machine作为language model, Collobert提出用CNN预测上下文词[8]。给定xx预测xxx的模型的输入都是词的向量,然后通过中间各种NN模型预测下一个词的概率。通过优化目标函数,最后得到这些向量的值。
比如word2vec中直接用二者的向量表示的内积来表示二者之间的关联,如下图公式 [3] (这里的向量是待学习的参数):

------------------------
基于矩阵分解和基于预测的模型之间有什么关联?Levy在文章[3]中证明了基于预测的SGNS (word2vec)和基于PMI的矩阵分解是等价的,二者差了一个常数。
各种各样的上下文:
既然语料库中的上下文可以反映一个词的语义信息,那么其他种类的上下文呢?于是各种各样的上下文被提出来,如topic, 如knowledge base相关联的词或对象,一个词的内部组成结构(部首,词根词缀,词的定义词, 多语言之间的一一对应的对象,句法树中特定dependency的词,和词对应的图片,和词对应的音频等等。所有这些信息都可以反应一个词的语义信息,即semantic evidence。于是各种集成不同context的方法也被提出来了 multi-view, multi-modal, multi-source [5,6]。
1. Baroni, Marco, Georgiana Dinu, and Germán Kruszewski. “Don’t Count, Predict! A Systematic Comparison of Context-Counting vs. Context-Predicting Semantic Vectors.” In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL), 238–247. Baltimore, MD, USA, 2014. http://anthology.aclweb.org/P/P14/P14-1023.pdf.
2.Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. “Glove: Global Vectors for Word Representation.” In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532--1543, 2014. http://nlp.stanford.edu/projects/glove/glove.pdf.
3. Levy, Omer, and Yoav Goldberg. “Neural Word Embedding as Implicit Matrix Factorization.” In Proceedings of NIPS, 2177–2185, 2014. http://papers.nips.cc/paper/5477-scalable-non-linear-learning-with-adaptive-polynomial-expansions.
4. Levy, Omer, Yoav Goldberg, and Ido Dagan. “Improving Distributional Similarity with Lessons Learned from Word Embeddings.” Transactions of the Association for Computational Linguistics 3 (2015): 211–225.
5. Faruqui, Manaal. “Diverse Context for Learning Word Representations.” Carnegie Mellon University, 2016. http://www.manaalfaruqui.com/.
6. Li, Yingming, Ming Yang, and Zhongfei Zhang. “Multi-View Representation Learning: A Survey from Shallow Methods to Deep Methods.” arXiv:1610.01206 [Cs], October 3, 2016. http://arxiv.org/abs/1610.01206.
7. Schutze, Hinrich. “Dimensions of Meaning.” In Proceedings of Supercomputing, 787–796. IEEE, 1992. http://ieeexplore.ieee.org/abstract/document/236684/.
8. Collobert, Ronan, and Jason Weston. “A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning,” 160–67. ACM, 2008.
编辑于 2017-07-13
252 条评论
分享
收藏感谢收起

Brad
30 人赞同了该回答
我觉得这是一篇很好的文章可以帮助理解word embedding:
Deep Learning, NLP, and Representations
http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/
如果不爱看英文的话,中文版也有:
深度学习、自然语言处理和表征方法
编辑于 2016-01-30
302 条评论
分享
收藏感谢

刘通
欢迎学术沟通,做自然语言处理方面,邮箱[email protected]
2 人赞同了该回答
WordEmbedding是文本挖掘的内容。文本挖掘的根本任务是分析文本,当前对文本进行分析基本上就是在两个层次:词汇和文档。(也有一些体系分为:词汇、句子和文档,其实句子也属于文档,俗称“短文本”)。
因此,只要将词汇和文档进行数值化处理,就可以进行大部分的语言分析任务了。传统的思路有两种:
思路1: 直接对文档进行数值化处理,分析时需要用到词汇时,把词汇视为特殊的文档
思路2:先对词汇进行数值化处理,然后再将文档的分析问题转化为对词汇集合的分析问题
WordEmbedding主要指基于思路2的技术实现,即WordEmbedding主要用于对词汇进行数值化处理。每个词对应一个数,就可以进行文本比较分析了。当然,为了丰富一下词汇的含义,可以把每个词对应成一个向量。