2019独角兽企业重金招聘Python工程师标准>>> 
什么是 socket?
socket 的原意是“插座”,在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。
我们把插头插到插座上就能从电网获得电力供应,同样,为了与远程计算机进行数据传输,需要连接到因特网,而 socket 就是用来连接到因特网的工具。

socket 的典型应用就是 Web 服务器和浏览器:浏览器获取用户输入的 URL,向服务器发起请求,服务器分析接收到的 URL,将对应的网页内容返回给浏览器,浏览器再经过解析和渲染,就将文字、图片、视频等元素呈现给用户。
学习 socket,也就是学习计算机之间如何通信,并编写出实用的程序。
UNIX/Linux 中的 socket 是什么?
在 UNIX/Linux 系统中,为了统一对各种硬件的操作,简化接口,不同的硬件设备也都被看成一个文件。对这些文件的操作,等同于对磁盘上普通文件的操作。
你也许听很多高手说过,UNIX/Linux 中的一切都是文件!那个家伙说的没错。
为了表示和区分已经打开的文件,UNIX/Linux 会给每个文件分配一个 ID,这个 ID 就是一个整数,被称为文件描述符(File Descriptor)。例如:
- 通常用 0 来表示标准输入文件(stdin),它对应的硬件设备就是键盘;
- 通常用 1 来表示标准输出文件(stdout),它对应的硬件设备就是显示器。
UNIX/Linux 程序在执行任何形式的 I/O 操作时,都是在读取或者写入一个文件描述符。一个文件描述符只是一个和打开的文件相关联的整数,它的背后可能是一个硬盘上的普通文件、FIFO、管道、终端、键盘、显示器,甚至是一个网络连接。
请注意,网络连接也是一个文件,它也有文件描述符!你必须理解这句话。
我们可以通过 socket() 函数来创建一个网络连接,或者说打开一个网络文件,socket() 的返回值就是文件描述符。有了文件描述符,我们就可以使用普通的文件操作函数来传输数据了,例如:
- 用 read() 读取从远程计算机传来的数据;
- 用 write() 向远程计算机写入数据。
你看,只要用 socket() 创建了连接,剩下的就是文件操作了,网络编程原来就是如此简单!
WIndow 系统中的 socket 是什么?
Windows 也有类似“文件描述符”的概念,但通常被称为“文件句柄”。因此,本教程如果涉及 Windows 平台将使用“句柄”,如果涉及 Linux 平台则使用“描述符”。
与 UNIX/Linux 不同的是,Windows 会区分 socket 和文件,Windows 就把 socket 当做一个网络连接来对待,因此需要调用专门针对 socket 而设计的数据传输函数,针对普通文件的输入输出函数就无效了。
这个世界上有很多种套接字(socket),比如 DARPA Internet 地址(Internet 套接字)、本地节点的路径名(Unix套接字)、CCITT X.25地址(X.25 套接字)等。但本教程只讲第一种套接字——Internet 套接字,它是最具代表性的,也是最经典最常用的。以后我们提及套接字,指的都是 Internet 套接字。
根据数据的传输方式,可以将 Internet 套接字分成两种类型。通过 socket() 函数创建连接时,必须告诉它使用哪种数据传输方式。
Internet 套接字其实还有很多其它数据传输方式,但是我可不想吓到你,本教程只讲常用的两种。
流格式套接字(SOCK_STREAM)
流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。
SOCK_STREAM 是一种可靠的、双向的通信数据流,数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送。
流格式套接字有自己的纠错机制,在此我们就不讨论了。
SOCK_STREAM 有以下几个特征:
- 数据在传输过程中不会消失;
- 数据是按照顺序传输的;
- 数据的发送和接收不是同步的(有的教程也称“不存在数据边界”)。
可以将 SOCK_STREAM 比喻成一条传送带,只要传送带本身没有问题(不会断网),就能保证数据不丢失;同时,较晚传送的数据不会先到达,较早传送的数据不会晚到达,这就保证了数据是按照顺序传递的。

为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达并且没有错误。
你也许见过 TCP,是因为你经常听说“TCP/IP”。TCP 用来确保数据的正确性,IP(Internet Protocol,网络协议)用来控制数据如何从源头到达目的地,也就是常说的“路由”。
那么,“数据的发送和接收不同步”该如何理解呢?
假设传送带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持同步,只要根据自己的节奏来装袋即可,不用管传送带传送了几批,也不用每到一批就装袋一次,可以等到凑够了 100 个水果再装袋。
流格式套接字的内部有一个缓冲区(也就是字符数组),通过 socket 传输的数据将保存到这个缓冲区。接收端在收到数据后并不一定立即读取,只要数据不超过缓冲区的容量,接收端有可能在缓冲区被填满以后一次性地读取,也可能分成好几次读取。
也就是说,不管数据分几次传送过来,接收端只需要根据自己的要求读取,不用非得在数据到达时立即读取。传送端有自己的节奏,接收端也有自己的节奏,它们是不一致的。
流格式套接字有什么实际的应用场景吗?浏览器所使用的 http 协议就基于面向连接的套接字,因为必须要确保数据准确无误,否则加载的 HTML 将无法解析。
数据报格式套接字(SOCK_DGRAM)
数据报格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。
计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。
因为数据报套接字所做的校验工作少,所以在传输效率方面比流格式套接字要高。
可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:
- 强调快速传输而非传输顺序;
- 传输的数据可能丢失也可能损毁;
- 限制每次传输的数据大小;
- 数据的发送和接收是同步的(有的教程也称“存在数据边界”)。
众所周知,速度是快递行业的生命。用摩托车发往同一地点的两件包裹无需保证顺序,只要以最快的速度交给客户就行。这种方式存在损坏或丢失的风险,而且包裹大小有一定限制。因此,想要传递大量包裹,就得分配发送。

另外,用两辆摩托车分别发送两件包裹,那么接收者也需要分两次接收,所以“数据的发送和接收是同步的”;换句话说,接收次数应该和发送次数相同。
总之,数据报套接字是一种不可靠的、不按顺序传递的、以追求速度为目的的套接字。
数据报套接字也使用 IP 协议作路由,但是它不使用 TCP 协议,而是使用 UDP 协议(User Datagram Protocol,用户数据报协议)。
QQ 视频聊天和语音聊天就使用 SOCK_DGRAM 来传输数据,因为首先要保证通信的效率,尽量减小延迟,而数据的正确性是次要的,即使丢失很小的一部分数据,视频和音频也可以正常解析,最多出现噪点或杂音,不会对通信质量有实质的影响。
注意:SOCK_DGRAM 没有想象中的糟糕,不会频繁的丢失数据,数据错误只是小概率事件。
流格式套接字(Stream Sockets)就是“面向连接的套接字”,它基于 TCP 协议;数据报格式套接字(Datagram Sockets)就是“无连接的套接字”,它基于 UDP 协议。
这给大家造成一种印象,面向连接就是可靠的通信,无连接就是不可靠的通信,实际情况是这样吗?
另外,不管是哪种数据传输方式,都得通过整个 Internet 网络的物理线路将数据传输过去,从这个层面理解,所有的 socket 都是有物理连接的呀,为什么还有无连接的 socket 呢?
本节就来给大家解开种种谜团,加深大家对数据传输方式的认识。
从字面上理解,面向连接好像有一条管道,它连接发送端和接收端,数据包都通过这条管道来传输。当然,两台计算机在通信之前必须先搭建好管道。
无连接好像没头苍蝇乱撞,数据包从发送端到接收端并没有固定的线路,爱怎么走就怎么走,只要能到达就行。每个数据包都比较自私,不和别人分享自己的线路,但是,大家最终都能殊途同归,到达接收端。
这样理解没错,但是我相信这还不够深入,大家还是感觉云里雾里,没有看到本质。好,接下来就是见证奇迹的时刻,我会用实例给大家演示!
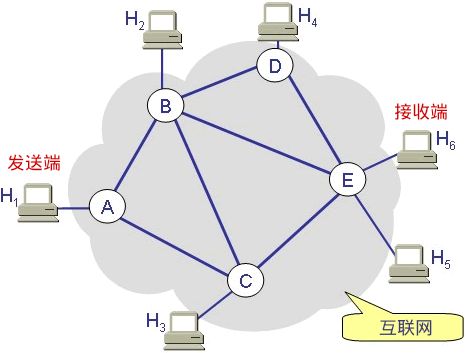
上图是一个简化的互联网模型,H1 ~ H6 表示计算机,A~E 表示路由器,发送端发送的数据必须经过路由器的转发才能到达接收端。
假设 H1 要发送若干个数据包给 H6,那么有多条路径可以选择,比如:
- 路径①:H1 --> A --> C --> E --> H6
- 路径②:H1 --> A --> B --> E --> H6
- 路径③:H1 --> A --> B --> D --> E --> H6
- 路径④:H1 --> A --> B --> C --> E --> H6
- 路径⑤:H1 --> A --> C --> B --> D --> E --> H6
数据包的传输路径是路由器根据算法来计算出来的,算法会考虑很多因素,比如网络的拥堵状况、下一个路由器是否忙碌等。
无连接的套接字
对于无连接的套接字,每个数据包可以选择不同的路径,比如第一个数据包选择路径④,第二个数据包选择路径①,第三个数据包选择路径②……当然,它们也可以选择相同的路径,那也只不过是巧合而已。
每个数据包之间都是独立的,各走各的路,谁也不影响谁,除了迷路的或者发生意外的数据包,最后都能到达 H6。但是,到达的顺序是不确定的,比如:
- 第一个数据包选择了一条比较长的路径(比如路径⑤),第三个数据包选择了一条比较短的路径(比如路径①),虽然第一个数据包很早就出发了,但是走的路比较远,最终还是晚于第三个数据包达到。
- 第一个数据包选择了一条比较短的路径(比如路径①),第三个数据包选择了一条比较长的路径(比如路径⑤),按理说第一个数据包应该先到达,但是非常不幸,第一个数据包走的路比较拥堵,这条路上的数据量非常大,路由器处理得很慢,所以它还是晚于第三个数据包达到了。
还有一些意外情况会发生,比如:
- 第一个数据包选择了路径①,但是路由器C突然断电了,那它就到不了 H6 了。
- 第三个数据包选择了路径②,虽然路不远,但是太拥堵,以至于它等待的时间太长,路由器把它丢弃了。
总之,对于无连接的套接字,数据包在传输过程中会发生各种不测,也会发生各种奇迹。H1 只负责把数据包发出,至于它什么时候到达,先到达还是后到达,有没有成功到达,H1 都不管了;H6 也没有选择的权利,只能被动接收,收到什么算什么,爱用不用。
无连接套接字遵循的是「尽最大努力交付」的原则,就是尽力而为,实在做不到了也没办法。无连接套接字提供的没有质量保证的服务。
面向连接的套接字
面向连接的套接字在正式通信之前要先确定一条路径,没有特殊情况的话,以后就固定地使用这条路径来传递数据包了。当然,路径被破坏的话,比如某个路由器断电了,那么会重新建立路径。

这条路径是由路由器维护的,路径上的所有路由器都要存储该路径的信息(实际上只需要存储上游和下游的两个路由器的位置就行),所以路由器是有开销的。
H1 和 H6 通信完毕后,要断开连接,销毁路径,这个时候路由器也会把之前存储的路径信息擦除。
在很多网络通信教程中,这条预先建立好的路径被称为“虚电路”,就是一条虚拟的通信电路。
为了保证数据包准确、顺序地到达,发送端在发送数据包以后,必须得到接收端的确认才发送下一个数据包;如果数据包发出去了,一段时间以后仍然没有得到接收端的回应,那么发送端会重新再发送一次,直到得到接收端的回应。这样一来,发送端发送的所有数据包都能到达接收端,并且是按照顺序到达的。
发送端发送一个数据包,如何得到接收端的确认呢?很简单,为每一个数据包分配一个 ID,接收端接收到数据包以后,再给发送端返回一个数据包,告诉发送端我接收到了 ID 为 xxx 的数据包。
面向连接的套接字会比无连接的套接字多出很多数据包,因为发送端每发送一个数据包,接收端就会返回一个数据包。此外,建立连接和断开连接的过程也会传递很多数据包。
不但是数量多了,每个数据包也变大了:除了源端口和目的端口,面向连接的套接字还包括序号、确认信号、数据偏移、控制标志(通常说的 URG、ACK、PSH、RST、SYN、FIN)、窗口、校验和、紧急指针、选项等信息;而无连接的套接字则只包含长度和校验和信息。
有连接的数据包比无连接大很多,这意味着更大的负载和更大的带宽。许多即时聊天软件采用 UDP 协议(无连接套接字),与此有莫大的关系。
总结
两种套接字各有优缺点:
- 无连接套接字传输效率高,但是不可靠,有丢失数据包、捣乱数据的风险;
- 有连接套接字非常可靠,万无一失,但是传输效率低,耗费资源多。
两种套接字的特点决定了它们的应用场景,有些服务对可靠性要求比较高,必须数据包能够完整无误地送达,那就得选择有连接的套接字(TCP 服务),比如 HTTP、FTP 等;而另一些服务,并不需要那么高的可靠性,效率和实时才是它们所关心的,那就可以选择无连接的套接字(UDP 服务),比如 DNS、即时聊天工具等。
不管是 Windows 还是 Linux,都使用 socket() 函数来创建套接字。socket() 在两个平台下的参数是相同的,不同的是返回值。
在《socket是什么》一节中我们讲到了 Windows 和 Linux 在对待 socket 方面的区别。
Linux 中的一切都是文件,每个文件都有一个整数类型的文件描述符;socket 也是一个文件,也有文件描述符。使用 socket() 函数创建套接字以后,返回值就是一个 int 类型的文件描述符。
Windows 会区分 socket 和普通文件,它把 socket 当做一个网络连接来对待,调用 socket() 以后,返回值是 SOCKET 类型,用来表示一个套接字。
Linux 下的 socket() 函数
在 Linux 下使用
int socket(int af, int type, int protocol);
1) af 为地址族(Address Family),也就是 IP 地址类型,常用的有 AF_INET 和 AF_INET6。AF 是“Address Family”的简写,INET是“Inetnet”的简写。AF_INET 表示 IPv4 地址,例如 127.0.0.1;AF_INET6 表示 IPv6 地址,例如 1030::C9B4:FF12:48AA:1A2B。
大家需要记住127.0.0.1,它是一个特殊IP地址,表示本机地址,后面的教程会经常用到。
你也可以使用 PF 前缀,PF 是“Protocol Family”的简写,它和 AF 是一样的。例如,PF_INET 等价于 AF_INET,PF_INET6 等价于 AF_INET6。
2) type 为数据传输方式/套接字类型,常用的有 SOCK_STREAM(流格式套接字/面向连接的套接字) 和 SOCK_DGRAM(数据报套接字/无连接的套接字),我们已经在《套接字有哪些类型》一节中进行了介绍。
3) protocol 表示传输协议,常用的有 IPPROTO_TCP 和 IPPTOTO_UDP,分别表示 TCP 传输协议和 UDP 传输协议。
有了地址类型和数据传输方式,还不足以决定采用哪种协议吗?为什么还需要第三个参数呢?
正如大家所想,一般情况下有了 af 和 type 两个参数就可以创建套接字了,操作系统会自动推演出协议类型,除非遇到这样的情况:有两种不同的协议支持同一种地址类型和数据传输类型。如果我们不指明使用哪种协议,操作系统是没办法自动推演的。
本教程使用 IPv4 地址,参数 af 的值为 PF_INET。如果使用 SOCK_STREAM 传输数据,那么满足这两个条件的协议只有 TCP,因此可以这样来调用 socket() 函数:
int tcp_socket = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); //IPPROTO_TCP表示TCP协议
这种套接字称为 TCP 套接字。
如果使用 SOCK_DGRAM 传输方式,那么满足这两个条件的协议只有 UDP,因此可以这样来调用 socket() 函数:
int udp_socket = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP); //IPPROTO_UDP表示UDP协议
这种套接字称为 UDP 套接字。
上面两种情况都只有一种协议满足条件,可以将 protocol 的值设为 0,系统会自动推演出应该使用什么协议,如下所示:
int tcp_socket = socket(AF_INET, SOCK_STREAM, 0); //创建TCP套接字 int udp_socket = socket(AF_INET, SOCK_DGRAM, 0); //创建UDP套接字
后面的教程中多采用这种简化写法。
在Windows下创建socket
Windows 下也使用 socket() 函数来创建套接字,原型为:
SOCKET socket(int af, int type, int protocol);
除了返回值类型不同,其他都是相同的。Windows 不把套接字作为普通文件对待,而是返回 SOCKET 类型的句柄。请看下面的例子:
SOCKET sock = socket(AF_INET, SOCK_STREAM, 0); //创建TCP套接字
socket() 函数用来创建套接字,确定套接字的各种属性,然后服务器端要用 bind() 函数将套接字与特定的 IP 地址和端口绑定起来,只有这样,流经该 IP 地址和端口的数据才能交给套接字处理。类似地,客户端也要用 connect() 函数建立连接。
bind() 函数
bind() 函数的原型为:
int bind(int sock, struct sockaddr *addr, socklen_t addrlen); //Linux int bind(SOCKET sock, const struct sockaddr *addr, int addrlen); //Windows
下面以 Linux 为例进行讲解,Windows 与此类似。
sock 为 socket 文件描述符,addr 为 sockaddr 结构体变量的指针,addrlen 为 addr 变量的大小,可由 sizeof() 计算得出。
下面的代码,将创建的套接字与IP地址 127.0.0.1、端口 1234 绑定:
- //创建套接字
- int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
- //创建sockaddr_in结构体变量
- struct sockaddr_in serv_addr;
- memset(&serv_addr, 0, sizeof(serv_addr)); //每个字节都用0填充
- serv_addr.sin_family = AF_INET; //使用IPv4地址
- serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具体的IP地址
- serv_addr.sin_port = htons(1234); //端口
- //将套接字和IP、端口绑定
- bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
这里我们使用 sockaddr_in 结构体,然后再强制转换为 sockaddr 类型,后边会讲解为什么这样做。
sockaddr_in 结构体
接下来不妨先看一下 sockaddr_in 结构体,它的成员变量如下:
- struct sockaddr_in{
- sa_family_t sin_family; //地址族(Address Family),也就是地址类型
- uint16_t sin_port; //16位的端口号
- struct in_addr sin_addr; //32位IP地址
- char sin_zero[8]; //不使用,一般用0填充
- };
1) sin_family 和 socket() 的第一个参数的含义相同,取值也要保持一致。
2) sin_prot 为端口号。uint16_t 的长度为两个字节,理论上端口号的取值范围为 0~65536,但 0~1023 的端口一般由系统分配给特定的服务程序,例如 Web 服务的端口号为 80,FTP 服务的端口号为 21,所以我们的程序要尽量在 1024~65536 之间分配端口号。
端口号需要用 htons() 函数转换,后面会讲解为什么。
3) sin_addr 是 struct in_addr 结构体类型的变量,下面会详细讲解。
4) sin_zero[8] 是多余的8个字节,没有用,一般使用 memset() 函数填充为 0。上面的代码中,先用 memset() 将结构体的全部字节填充为 0,再给前3个成员赋值,剩下的 sin_zero 自然就是 0 了。
in_addr 结构体
sockaddr_in 的第3个成员是 in_addr 类型的结构体,该结构体只包含一个成员,如下所示:
- struct in_addr{
- in_addr_t s_addr; //32位的IP地址
- };
in_addr_t 在头文件
- unsigned long ip = inet_addr("127.0.0.1");
- printf("%ld\n", ip);
运行结果:
16777343

图解 sockaddr_in 结构体
为什么要搞这么复杂,结构体中嵌套结构体,而不用 sockaddr_in 的一个成员变量来指明IP地址呢?socket() 函数的第一个参数已经指明了地址类型,为什么在 sockaddr_in 结构体中还要再说明一次呢,这不是啰嗦吗?
这些繁琐的细节确实给初学者带来了一定的障碍,我想,这或许是历史原因吧,后面的接口总要兼容前面的代码。各位读者一定要有耐心,暂时不理解没有关系,根据教程中的代码“照猫画虎”即可,时间久了自然会接受。
为什么使用 sockaddr_in 而不使用 sockaddr
bind() 第二个参数的类型为 sockaddr,而代码中却使用 sockaddr_in,然后再强制转换为 sockaddr,这是为什么呢?
sockaddr 结构体的定义如下:
- struct sockaddr{
- sa_family_t sin_family; //地址族(Address Family),也就是地址类型
- char sa_data[14]; //IP地址和端口号
- };
下图是 sockaddr 与 sockaddr_in 的对比(括号中的数字表示所占用的字节数):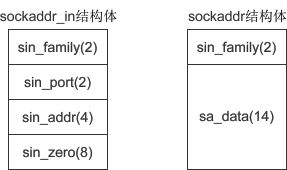
sockaddr 和 sockaddr_in 的长度相同,都是16字节,只是将IP地址和端口号合并到一起,用一个成员 sa_data 表示。要想给 sa_data 赋值,必须同时指明IP地址和端口号,例如”127.0.0.1:80“,遗憾的是,没有相关函数将这个字符串转换成需要的形式,也就很难给 sockaddr 类型的变量赋值,所以使用 sockaddr_in 来代替。这两个结构体的长度相同,强制转换类型时不会丢失字节,也没有多余的字节。
可以认为,sockaddr 是一种通用的结构体,可以用来保存多种类型的IP地址和端口号,而 sockaddr_in 是专门用来保存 IPv4 地址的结构体。另外还有 sockaddr_in6,用来保存 IPv6 地址,它的定义如下:
纯文本复制
- struct sockaddr_in6 {
- sa_family_t sin6_family; //(2)地址类型,取值为AF_INET6
- in_port_t sin6_port; //(2)16位端口号
- uint32_t sin6_flowinfo; //(4)IPv6流信息
- struct in6_addr sin6_addr; //(4)具体的IPv6地址
- uint32_t sin6_scope_id; //(4)接口范围ID
- };
正是由于通用结构体 sockaddr 使用不便,才针对不同的地址类型定义了不同的结构体。
connect() 函数
connect() 函数用来建立连接,它的原型为:
int connect(int sock, struct sockaddr *serv_addr, socklen_t addrlen); //Linux int connect(SOCKET sock, const struct sockaddr *serv_addr, int addrlen); //Windows
各个参数的说明和 bind() 相同,不再赘述。
对于服务器端程序,使用 bind() 绑定套接字后,还需要使用 listen() 函数让套接字进入被动监听状态,再调用 accept() 函数,就可以随时响应客户端的请求了。
listen() 函数
通过 listen() 函数可以让套接字进入被动监听状态,它的原型为:
- int listen(int sock, int backlog); //Linux
- int listen(SOCKET sock, int backlog); //Windows
sock 为需要进入监听状态的套接字,backlog 为请求队列的最大长度。
所谓被动监听,是指当没有客户端请求时,套接字处于“睡眠”状态,只有当接收到客户端请求时,套接字才会被“唤醒”来响应请求。
请求队列
当套接字正在处理客户端请求时,如果有新的请求进来,套接字是没法处理的,只能把它放进缓冲区,待当前请求处理完毕后,再从缓冲区中读取出来处理。如果不断有新的请求进来,它们就按照先后顺序在缓冲区中排队,直到缓冲区满。这个缓冲区,就称为请求队列(Request Queue)。
缓冲区的长度(能存放多少个客户端请求)可以通过 listen() 函数的 backlog 参数指定,但究竟为多少并没有什么标准,可以根据你的需求来定,并发量小的话可以是10或者20。
如果将 backlog 的值设置为 SOMAXCONN,就由系统来决定请求队列长度,这个值一般比较大,可能是几百,或者更多。
当请求队列满时,就不再接收新的请求,对于 Linux,客户端会收到 ECONNREFUSED 错误,对于 Windows,客户端会收到 WSAECONNREFUSED 错误。
注意:listen() 只是让套接字处于监听状态,并没有接收请求。接收请求需要使用 accept() 函数。
accept() 函数
当套接字处于监听状态时,可以通过 accept() 函数来接收客户端请求。它的原型为:
纯文本复制
- int accept(int sock, struct sockaddr *addr, socklen_t *addrlen); //Linux
- SOCKET accept(SOCKET sock, struct sockaddr *addr, int *addrlen); //Windows
它的参数与 listen() 和 connect() 是相同的:sock 为服务器端套接字,addr 为 sockaddr_in 结构体变量,addrlen 为参数 addr 的长度,可由 sizeof() 求得。
accept() 返回一个新的套接字来和客户端通信,addr 保存了客户端的IP地址和端口号,而 sock 是服务器端的套接字,大家注意区分。后面和客户端通信时,要使用这个新生成的套接字,而不是原来服务器端的套接字。
最后需要说明的是:listen() 只是让套接字进入监听状态,并没有真正接收客户端请求,listen() 后面的代码会继续执行,直到遇到 accept()。accept() 会阻塞程序执行(后面代码不能被执行),直到有新的请求到来。
在 Linux 和 Windows 平台下,使用不同的函数发送和接收 socket 数据,下面我们分别讲解。
Linux下数据的接收和发送
Linux 不区分套接字文件和普通文件,使用 write() 可以向套接字中写入数据,使用 read() 可以从套接字中读取数据。
前面我们说过,两台计算机之间的通信相当于两个套接字之间的通信,在服务器端用 write() 向套接字写入数据,客户端就能收到,然后再使用 read() 从套接字中读取出来,就完成了一次通信。
write() 的原型为:
ssize_t write(int fd, const void *buf, size_t nbytes);
fd 为要写入的文件的描述符,buf 为要写入的数据的缓冲区地址,nbytes 为要写入的数据的字节数。
size_t 是通过 typedef 声明的 unsigned int 类型;ssize_t 在 "size_t" 前面加了一个"s",代表 signed,即 ssize_t 是通过 typedef 声明的 signed int 类型。
write() 函数会将缓冲区 buf 中的 nbytes 个字节写入文件 fd,成功则返回写入的字节数,失败则返回 -1。
read() 的原型为:
ssize_t read(int fd, void *buf, size_t nbytes);
fd 为要读取的文件的描述符,buf 为要接收数据的缓冲区地址,nbytes 为要读取的数据的字节数。
read() 函数会从 fd 文件中读取 nbytes 个字节并保存到缓冲区 buf,成功则返回读取到的字节数(但遇到文件结尾则返回0),失败则返回 -1。
Windows下数据的接收和发送
Windows 和 Linux 不同,Windows 区分普通文件和套接字,并定义了专门的接收和发送的函数。
从服务器端发送数据使用 send() 函数,它的原型为:
int send(SOCKET sock, const char *buf, int len, int flags);
sock 为要发送数据的套接字,buf 为要发送的数据的缓冲区地址,len 为要发送的数据的字节数,flags 为发送数据时的选项。
返回值和前三个参数不再赘述,最后的 flags 参数一般设置为 0 或 NULL,初学者不必深究。
在客户端接收数据使用 recv() 函数,它的原型为:
int recv(SOCKET sock, char *buf, int len, int flags);