说完模拟登录之后呢,现在讲述对于手机端新浪的爬取过程,此例讲述针对Ajax异步请求内容的爬取,以新浪微博“小黄车”话题下的微博为例
分析过程####
1.爬取入口页面:http://m.weibo.cn/k/%E5%B0%8F%E9%BB%84%E8%BD%A6?from=feed
2.微博信息所在位置查找
当你进入该话题时,通过查看源代码发现里面并没有页面上的微博信息,那么这些信息在哪呢?是怎么载入到页面的呢?打开开发者工具,当你鼠标滑到页面底端时继续滑动会加载出新的页面,这个时候会发现网络中的XHR请求会对应增加一项,并且查看响应会发现里面包含了页面的各种信息。主题微博信息第一页在cards的第五个对象下的cardgroup中,其余页面均在cards的第一个对象下的cardgroup中如下图


发现页面内容所在之后就需要构造类似的请求,以得到包含微博信息的响应json文件。
3.请求规律
那么,又一个问题来了,请求有什么规律呢?请求可在标题头中查看,具体可点击编辑和重发查看具体信息,具体参数可在参数中查看
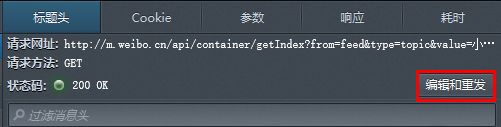

加载新一页之后发现这些请求除了since_id这项参数是不一样的之外,其余都是一样的,也就是说话题下的微博分页是根据since_id来确定的,每当页面滑倒底部时,继续往下滑则会发送新的请求,请求中的since_id标志上一页加载到哪一条微博,现在应该从哪一条微博开始展示。这样就实现了分页,因此,接下来就是找到since_id的内容来源于哪里就可以开始构造请求了,经查看后发现每一个请求的since_id内容都可以在前一项请求中的响应中找到

代码讲解####
1.思路介绍
首先构造请求,第一页是没有since_id参数的,所以除since_id外的请求参数可固定,since_id则通过每一次读取响应内容中的since_id动态替换,然后成功读取响应内容后(响应内容为json)用python内置json库载入后,最后就可以方便提取想要的内容了。
2.源代码
# -- coding: utf-8 --
import urllib
import urllib2
from bs4 import BeautifulSoup
import re
import os
import xlwt
import xlrd
from xlutils.copy import copy
import time
import string
import datetime
import sys
import shutil
import codecs
import traceback
import json
class WeiboContent:
'''
output:
info_list = [(time, user_name, source, user_statuses_count, user_followers_count, user_follow_count,
user_verified, user_verified_type, user_urank, location, content, urls, pic_num, audios, mention)]
'''
def readHtml(self):
try:
info_list = []
user_agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:27.0) Gecko/20100101 Firefox/27.0'
cookies = '"_T_WM=...."' #这里的cookie直接从浏览器中粘过来了,具体可参考上一篇文章
headers = { 'User-Agent' : user_agent , 'cookie': cookies}
page = 1
#构造固定的一些参数
form_data = {
'extparam' : '小黄车',
'from' : 'feed',
'luicode' : '10000011',
'lfid' : '100808b0a0455a95cc4937460d29aa3076aec4',
'containerid' : '100808topic'
}
since_id = ''
#这里是以since_id为循环终止条件,最后一页没有since_id,所以当获取出错时跳出循环
while page:
if page > 1:
form_data['since_id'] = since_id
form_data['containerid'] = containerid
#将form_data的键值对转换为以连接符&划分的字符串
formData = urllib.urlencode(form_data)
url = 'http://m.weibo.cn/api/container/getIndex?'
#构造request请求
request = urllib2.Request(url = url, headers = headers, data = formData)
index_doc = urllib2.urlopen(request).read()
#使用json.loads()将获取的返回内容转换成json格式
index_json = json.loads(index_doc)
try:
since_id = index_json['pageInfo']['since_id']
except:
traceback.print_exc()
print 'end get data,since-id wrong'
break
if page == 1:
card_group = index_json['cards'][5]['card_group']
else:
card_group = index_json['cards'][0]['card_group']
#遍历提取card_group中每一条微博的信息
for card in card_group:
try:
mblog = card['mblog']
#针对时间中的分钟前和今天做标准化时间处理
time = mblog['created_at']
if len(re.findall('分钟前'.decode('utf-8'), time)) == 1:
num = int(time.split('分钟前'.decode('utf-8'))[0])
time = datetime.datetime.now() - datetime.timedelta(minutes = num)
time = time.strftime('%m-%d %H:%m')
if len(re.findall('今天'.decode('utf-8'), time)) == 1:
hour = time.split('今天'.decode('utf-8'))[1]
time = '04-19' + hour #这里写的比较随意,直接给出日期,可利用和时间有关函数动态获取爬取当天的日期
#获取微博内容,如果为长微博需获取全文的链接地址进一步获取微博全部内容
isLongText = mblog['isLongText']
text = mblog['text']
if isLongText:
text_id = mblog['id']
text_href = 'http://m.weibo.cn/statuses/extend?id=%s'%text_id
text_req = urllib2.Request(url = text_href, headers = headers)
text_doc = urllib2.urlopen(text_req).read()
text_json = json.loads(text_doc)
text = text_json['longTextContent']
#提取微博内容的一些特征信息
text_soup = BeautifulSoup(text,"html.parser")
content = text_soup.get_text()
urls = len(re.findall('small_web_default.png', text)) + len(re.findall('small_article_default.png', text))
audios = len(re.findall('small_video_default.png', text))
mention = len(re.findall('', text))
topic = len(re.findall('', text))
source = mblog['source']
reposts_count = mblog['reposts_count']
comments_count = mblog['comments_count']
attitudes_count = mblog['attitudes_count']
#提取用户信息
user = mblog['user']
user_id = user['id']
user_gender = user['gender']
user_statuses_count = user['statuses_count'] #微博数
user_followers_count = user['followers_count'] #粉丝数
user_follow_count = user['follow_count'] #关注数
user_verified = user['verified']
#verified_type:-1普通用户 0名人 1政府 2企业 3媒体 4校园 5网站 6应用 7团体 8待审企业 200会员 220达人 0黄V用户 其他蓝v用户 10是微女郎
user_verified_type = user['verified_type']
user_urank = user['urank'] #微博等级
is_location = len(re.findall('small_location_default.png', text))
if is_location:
location = text_soup.find_all("span", {"class": "surl-text"})[-1].get_text()
else:
location = ''
pic_num = len(mblog['pics']) if mblog.has_key('pics') else 0
info = (time, user_id, source, user_gender, user_statuses_count, user_followers_count, user_follow_count, \
user_verified, user_verified_type, user_urank, location, content, urls, pic_num, \
audios, mention, topic, reposts_count, comments_count, attitudes_count)
info_list.append(info)
except Exception,e:
traceback.print_exc()
print '----'
print page
print 'since---'
print since_id
continue
print 'get page:%d'%page
page += 1
return info_list
except Exception,e:
traceback.print_exc()
return info_list
#存入excel
def save_excel(self):
info_list = self.readHtml()
#print info_list
file = xlwt.Workbook()
sheet1 = file.add_sheet(u'sheet1',cell_overwrite_ok=True)
sheet1.col(0).width=256*22
sheet1.col(11).width=256*100
style = xlwt.easyxf('align: wrap on, vert centre, horiz center')
row0 = ('time', 'user_id', 'source', 'user_gender', 'user_statuses_count', 'user_followers_count', \
'user_follow_count', 'user_verified', 'user_verified_type', 'user_urank',\
'location', 'content', 'urls', 'pic_num', 'audios', 'mention', 'topic', 'reposts_count', 'comments_count', 'attitudes_count')
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i],style)
for i in range(0,len(info_list)):
for j in range(0,len(info_list[i])):
sheet1.write(i+1, j, info_list[i][j], style)
file.save('D:/dataset/USele_topic.xls')
print 'save success'
#*******************************************************************************
# 程序入口 预先调用
#*******************************************************************************
if __name__ == '__main__':
WeiboContent().save_excel()