2019独角兽企业重金招聘Python工程师标准>>> 
一、环境准备
1.CDH环境
| Hadoop | 2.6.0+cdh5.11.1+2400 |
| Zookeeper | 3.4.5+cdh5.11.1+111 |
| Hive | 1.1.0+cdh5.11.1+1041 |
| HBase | 1.2.0+cdh5.11.1+319 |
| Kylin | apache-kylin-2.4.0-bin-cdh57 |
2.hive环境:
FactTable:feedback (hrid关联字段)
LookupTable: dim_staff (hrid关联字段)
二、建立project
1.添加project
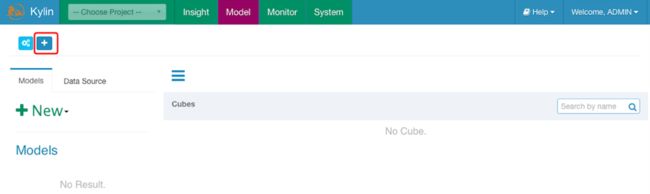
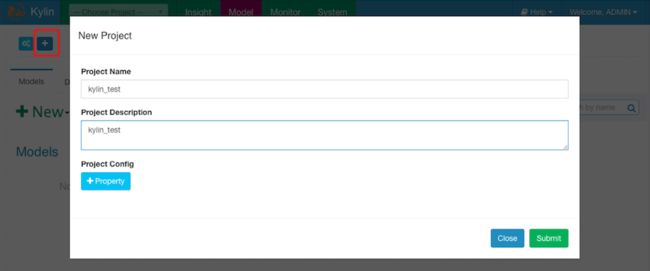
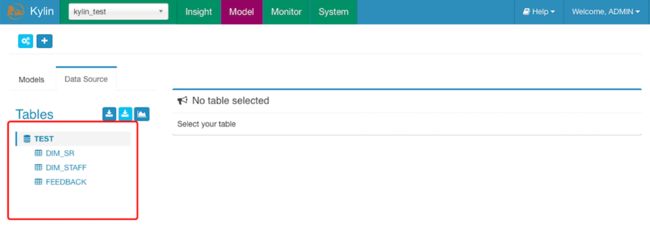
2.添加hive表
虽然 Kylin 能访问 Hive 元数据,但不会让用户查询所有的 hive 表,可以使用 “Sync” 方法从 Hive 中同步需要用到的表


三、构建model
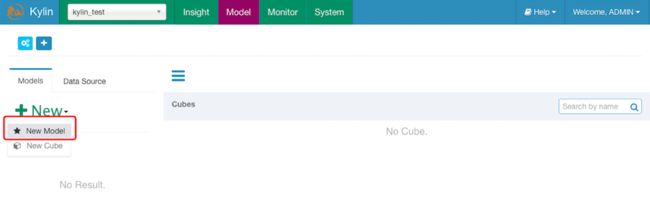
1.Model Info
定义Model名称及描述信息

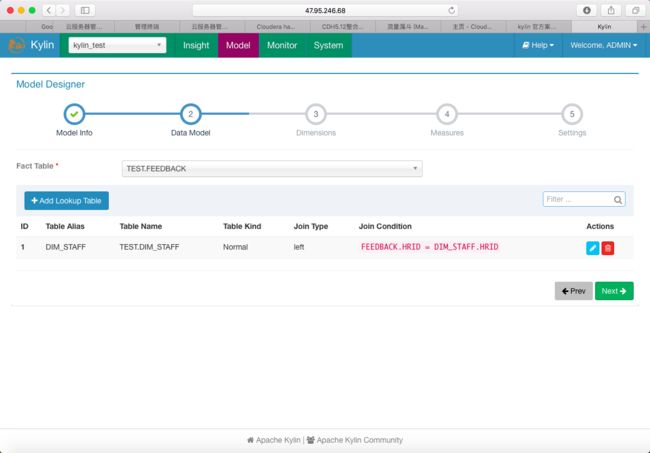
2.Data Model
定义FactTable以及LookUpTable,并定义关联类型(左连接、内连接)、关联条件

3.Dimensions
对每个表选择相应的列作为维度列

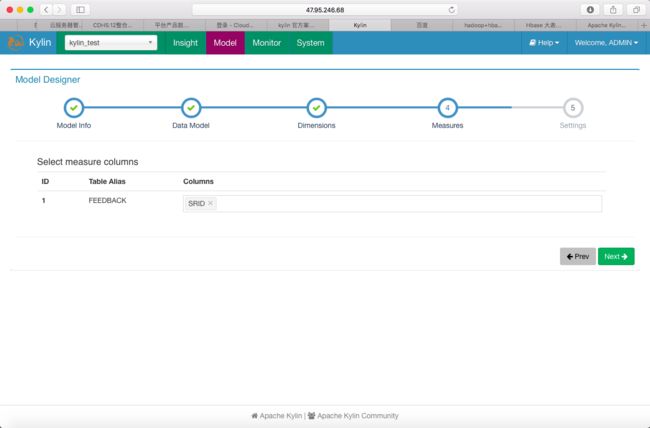
4.Measures
选择相应列作为度量列(只能选择FactTable的列)
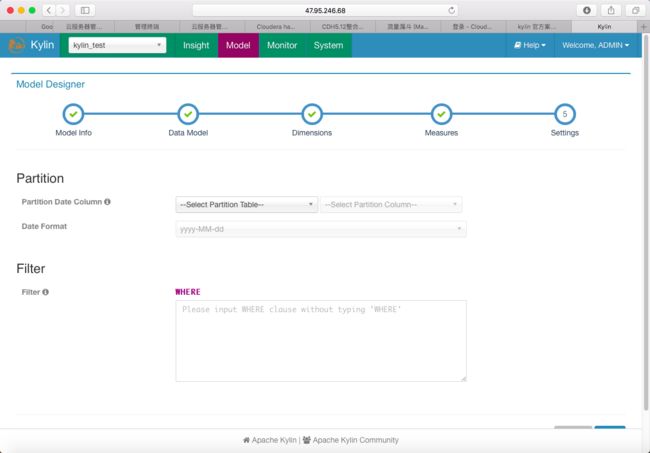
5.Settings
partition及filter定义
如果事实表数据每日递增,则选择相应的日期列以及日期格式,这里不做定义
如果抽取数据时候想做一些筛选,则输入筛选条件,这里不做定义
四、构建cube

1.Cube Info
选择相应的Model,并定义CUBE名称、通知邮箱、描述信息

2.Dimensions
勾选相应列作为维度列,LookUpTable可选择normal或derived(一般列、衍生列)
normal纬度作为普通独立的纬度,而derived 维度不会计算入cube,将由事实表的外键推算出

3.Measures
勾选相应列作为度量,kylin提供8种度量:SUM、MAX、MIN、COUNT、COUNT_DISTINCT TOP_N、EXTENDED_COLUMN、PERCENTILE
DISTINCT_COUNT有两个实现:
1)近似实现 HyperLogLog,选择可接受的错误率,低错误率需要更多存储;
2)精确实现 bitmap
TopN 度量在每个维度结合时预计算,需要两个参数:
1)一是被用来作为 Top 记录的度量列,Kylin 将计算它的 SUM 值并做倒序排列,如sum(price)
2)二是 literal ID,代表最 Top 的记录,如seller_id
EXTENDED_COLUMN
Extended_Column 作为度量比作为维度更节省空间。一列和零一列可以生成新的列
PERCENTILE
Percentile 代表了百分比。值越大,错误就越少。100为最合适的值

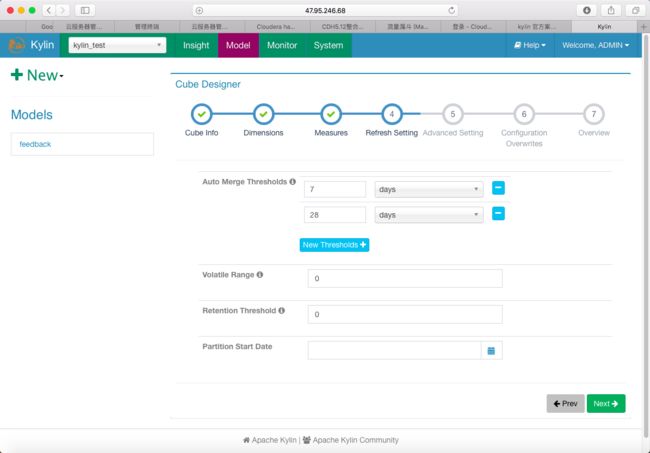
4.Refresh Setting
定义刷新操作相关值,这里不做更改
Auto Merge Thresholds:
自动合并小的 segments 到中等甚至更大的 segment。如果不想自动合并,删除默认2个选项
Volatile Range:
默认为0,会自动合并所有可能的cube segments,或者用 ‘Auto Merge’ 将不会合并最新的 [Volatile Range] 天的 cube segments
Retention Threshold:
默认为0,只会保存 cube 过去几天的 segment,旧的 segment 将会自动从头部删除
Partition Start Date:
cube 的开始日期
5.Advanced Setting
高级设定关系到立方体是否足够优化,可根据实际情况将维度列定义为强制维度、层级维度、联合维度
- Mandatory维度指的是总会存在于group by或where中的维度
- Hierarchy是一组有层级关系的维度,如国家、省份、城市
- Joint是将多个维度组合成一个维度

6.Configuration Overwrites
Kylin 允许在 Cube 级别覆盖部分 kylin.properties 中的配置,这里不做添加

7.Overview
立方体信息设置完毕,预览基本信息

五、构建立方体
1.build
在Models页面,选择action下拉栏中的build选项开始build,接下来转到Monitor页面监控job执行情况

2.查看
build完成之后立方体已处于READY状态,意味着它已经准备好进行SQL查询。点击CUBE名可展开更多信息,包括hbase存储信息等
六、查询及性能
1.查询测试
Insight页面可以看到CUBE涉及表,可使用SQL进行快速查询。同时Kylin提供了诸如列排序、Export结果集、可视化图表等功能

此处展示了计算用时以及被成功访问的CUBE

2.性能对比
对比HiveOnMR、HiveOnSpark、Kylin三种解决方案的运行性能,预计算的kylin遥遥领先。
| select | Hive-MR | Hive-Spark | Kylin |
| productlineid,orderfromid,hrid,srtypeid,count(*) | 20.157 | 6.152 | 0.11 |
| productlineid,orderfromid,hrid,srtypeid,count(distinct srid) | 28.123 | 8.485 | 0.2 |
3.维度优化对比
由于实验中有三个维度之间有很强的相关性,三维度的维度基数分别为79、187、185,但是三维度count(distinct)的值只有311,因此将此三个维度设置为Joint维度,与不设Joint的CUBE做对比测试。结过证明联合维度使得膨胀率显著下降,可以节约更多的集群空间。
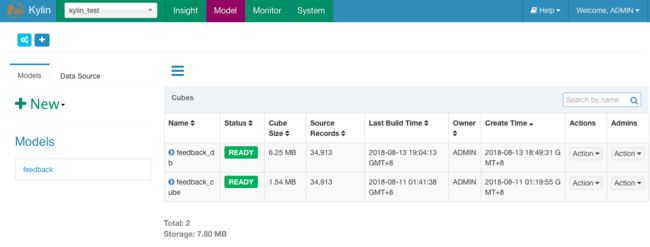
| 维度数 | Mandatory | Hierarchy | Joint | 初始大小 | cube大小 | 膨胀率 | |
| CUBE-A | 6 | 0 | 0 | 0 | 1.36MB | 6.25MB | 459.85% |
| CUBE-B | 6 | 0 | 0 | 3 | 1.36MB | 1.54MB | 113.62% |