基于pHash图像特征的图像聚类—Kmeans算法—Python实现
基于pHash图像特征的图像聚类—Kmeans算法—Python实现
基于图像phash特征通过KMeans聚类算法实现图像聚类,通过熵来进行对结果的评估,顺便用PCA降维特征来可视化聚类结果
(1)环境
Python3.5,数据集cifar10 可以参考http://www.cs.toronto.edu/~kriz/cifar.html
(2)Kmeans
k-means是一种非常常见的聚类算法,在处理聚类任务中经常使用。k-means算法是一种原型聚类算法。何为原型聚类呢?算法首先对原型进行初始化,然后对原型进行迭代更新求解,采用不同的原型表示、不同的求解方式,将产生不同的求解方式。
k-means聚类算法的描述如下:
输入:样本集
过程:
从样本集中随机选择k个样本作为初始向量,即k个初始质心点
repeat
对样本集中的每个数据
对于当前数据
计算当前数据与k个质心之间的距离
将当前数据加入到距离其最近的簇
对于每个簇,计算其均值,即得到新的k个质心点
util 迭代终止条件满足为止(分类结果不再变化)
输出:簇划分
(3)Python实现
数据预处理
"""
数据预处理
"""
datanumber=1000 #图像个数
print('读入图片')
def unpickle(file):
import pickle
with open(file,'rb')as fo:
dict =pickle.load(fo,encoding='bytes')
return dict
path='../cifar-10-batches-py/'#路径可以自己定义
a=unpickle(path+'data_batch_1')
temp=np.zeros((10000,3072))
data_label=np.zeros(50000)
data_array=np.zeros((50000,3072))
for i in range(5):
cur_dict=unpickle(path+'data_batch_'+str(i+1))
for j in range(10000):
data_array[i*10000+j]=cur_dict[b'data'][j][:]
data_label[i*10000+j]=cur_dict[b'labels'][j]
data_array=data_array.reshape(50000,3,32,32).transpose(0,2,3,1).astype('float32')
data_label=data_label.astype('float32')phash图像特征
"""
phash图像特征
"""
def pHash(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建二维列表
h,w=gray.shape[:2]
vis0=np.zeros((h,w),np.float32)
vis0[:h,:w]=gray
#二维DCT变换
vis1=cv2.dct(cv2.dct(vis0))
img_list=vis1.flatten()
# 计算均值
avg=sum(img_list)*1./len(img_list)
avg_list=['0' if i 分类图像phash特征提取
"""
分类图像phash特征提取
"""
true_labels=[]#cifar10真实标签
print('提取phash特征')
feature=[]
for i in range(datanumber):
img=data_array[i,:,:,:].astype('uint8')
true_labels.append(data_label[i].astype('uint8'))
feature.append(pHash(img))
print('特征提取结束')Kmeans实现
"""
Kmeans分类
"""
#计算欧几里得距离
def distance(vecA,vecB):
return np.sqrt(np.sum(np.square(vecA-vecB)))
#取K个随机质心
def randcent(data,k):
return random.sample(data,k)
#KMeans实现
def kmeans(dataset,k):
m=len(dataset)
clustterassment=np.zeros((m,2)).astype('float32')#二维向量,第一维存放类别 第二维存放距离本类别质心距离
centnoids=randcent(dataset,k) #随机取K个质心
clusterchanged=True #用来判断收敛,质心不再变化时,算法停止
time=1
while clusterchanged:
clusterchanged=False
for i in range(m):
minDist=float("inf")
minIndex=-1
for j in range(k):
vec1=np.array(centnoids[j])
vec2=np.array(dataset[i])
distji=distance(vec1,vec2)
if distji原理如图
"""
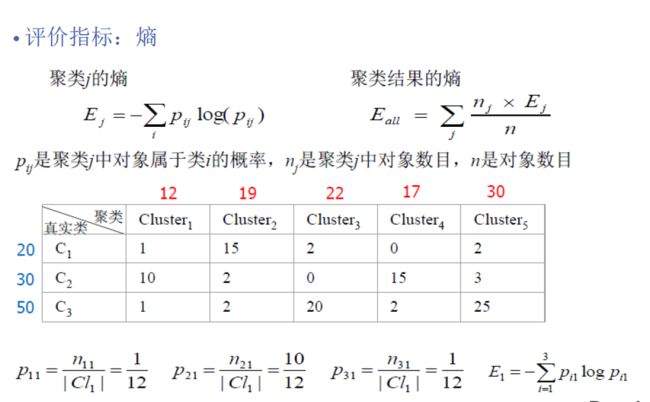
性能评估 熵
"""
#n_clusters=10
#cls=KMeans(n_clusters).fit(feature)
#predict_labels=cls.labels_
predict_labels=kmeans(feature,10)
entropy=np.zeros(10).astype('float32')
Eall=0
cluster=np.zeros((10,10)).astype('float32')#10个真实标签 10个预测标签 组成10*10的矩阵 存放个数
print("分类图像总数 %d"%datanumber)
for i in range(datanumber):
cluster[predict_labels[i],true_labels[i]]+=1
for i in range(10):
Esum=sum(cluster[i,:])#每一类图像总数
print (cluster[i,:])
print("第%d类共%d"%(i,Esum))
#计算熵
for j in range(10):
p1=cluster[i][j]/Esum
if p1!=0:
entropy[i]+=-(p1*log(p1))
Eall+=Esum*entropy[i]
Eall=Eall/datanumber
print('评估矩阵完成,熵为%.5f'%Eall) 图像聚类可视化
"""
图像聚类可视化
"""
#256维特征feature 通过PCA降维 方便画图
from sklearn.decomposition import PCA
pca = PCA(n_components=2) #输出两维
newData = pca.fit_transform(feature) #载入N维
x1=[]
y1=[]
x2=[]
y2=[]
x3=[]
y3=[]
x4=[]
y4=[]
x5=[]
y5=[]
x6=[]
y6=[]
x7=[]
y7=[]
x8=[]
y8=[]
x9=[]
y9=[]
x10=[]
y10=[]
for i in range(datanumber):
if predict_labels[i]==0:
x10.append(newData[i][0])
y10.append(newData[i][1])
elif predict_labels[i]==1:
x1.append(newData[i][0])
y1.append(newData[i][1])
elif predict_labels[i]==2:
x2.append(newData[i][0])
y2.append(newData[i][1])
elif predict_labels[i]==3:
x3.append(newData[i][0])
y3.append(newData[i][1])
elif predict_labels[i]==4:
x4.append(newData[i][0])
y4.append(newData[i][1])
elif predict_labels[i]==5:
x5.append(newData[i][0])
y5.append(newData[i][1])
elif predict_labels[i]==6:
x6.append(newData[i][0])
y6.append(newData[i][1])
elif predict_labels[i]==7:
x7.append(newData[i][0])
y7.append(newData[i][1])
#只取了6个类别给予显示
plt.plot(x1, y1, 'or')
plt.plot(x2, y2, 'og')
plt.plot(x3, y3, 'ob')
plt.plot(x4, y4, 'ok')
plt.plot(x5, y5, 'oy')
plt.plot(x6, y6, 'oc')
plt.show()
结果分析
熵的结果平均稳定在2.几,不是很理想,准确率也是差不多在12%~14%,不理想的原因是图像特征的选取不够好,采用的是phash,以及聚类算法KMeans。自己写的KMeans要比python自带的KMeans速度上慢,数据量在5000以下还好,超过10000到50000之间,基本一次跑完要花10分钟左右。10000的数据量KMeans差不多要迭代60次才能收敛。不过通过PCA降维的可视化效果看上去不错(一种错觉~)如图
10000张图片


50000张图片
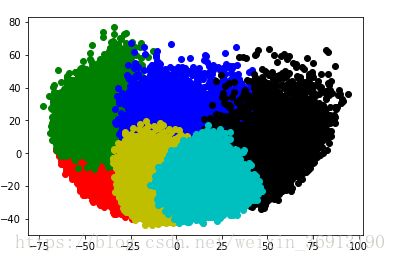

1000张


10000张 50000张 1000张



Python代码完整版
import cv2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from math import log ,sqrt,pow
import math
import random
"""
数据预处理
"""
datanumber=1000 #图像个数
print('读入图片')
def unpickle(file):
import pickle
with open(file,'rb')as fo:
dict =pickle.load(fo,encoding='bytes')
return dict
path='../cifar-10-batches-py/'#路径可以自己定义
a=unpickle(path+'data_batch_1')
temp=np.zeros((10000,3072))
data_label=np.zeros(50000)
data_array=np.zeros((50000,3072))
for i in range(5):
cur_dict=unpickle(path+'data_batch_'+str(i+1))
for j in range(10000):
data_array[i*10000+j]=cur_dict[b'data'][j][:]
data_label[i*10000+j]=cur_dict[b'labels'][j]
data_array=data_array.reshape(50000,3,32,32).transpose(0,2,3,1).astype('float32')
data_label=data_label.astype('float32')
"""
phash图像特征
"""
def pHash(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建二维列表
h,w=gray.shape[:2]
vis0=np.zeros((h,w),np.float32)
vis0[:h,:w]=gray
#二维DCT变换
vis1=cv2.dct(cv2.dct(vis0))
img_list=vis1.flatten()
# 计算均值
avg=sum(img_list)*1./len(img_list)
avg_list=['0' if i