Hyperscan发布5.3.0版本
“常通风、勤洗手、戴口罩、少聚集。”

Hyperscan发布5.3.0新版本啦
![]()
Hyperscan 5.3.0 版本已于2020年5月25日在Github (https://github.com/intel/hyperscan) 上发布。这一版本中,我们主要新增对AVX-512 Vector Byte Manipulation Instructions(VBMI)指令集的支持,并对多字符串匹配算法和单双字符匹配算法进行优化,还公开了用于人工测试的正则表达式构造脚本。
![]()
更新内容包括如下几个方面:
A.
性能优化
1. 多字符串匹配算法——Teddy
● 核心:
在当前AVX-512实现基础上增加AVX-512 VBMI支持。
● 算法简介:
Teddy和FDR是Hyperscan内部的两大多字符串匹配算法,其中Teddy用于中等规模字符串集合匹配。
FDR是Hyperscan内部处理超大规模字符串集合的匹配算法,其设计原理和实现细节可以参考我们的NSDI文章:https://www.usenix.org/system/files/nsdi19-wang-xiang.pdf
Teddy也有类似FDR的前后端设计,前端高速匹配定长后缀,后端对前端产生的候选匹配进行最终验证。对于前端设计,Teddy也和FDR一样采用“掩码表+SHIFT-OR”的工作方式。
不过,Teddy前端最大的特点在于——掩码表的设计是基于半字符(4比特位),而不是FDR中的超字符(9~15比特位)或全字符(8比特位)。采用半字符(4比特位)设计,可以利用PSHUFB指令代替LOAD进行批量查表,因为PSHUFB指令能够以控制码的低4位为索引值对16字节输入进行操作,那么每个半字符就起到了4位索引值的作用。
同时,Teddy前端不再使用8字节后缀,而是1~4字节。实际使用中为平衡精度和速度更多使用3字节,这表明Teddy前端掩码表项通常有6个表项,每个表项都对应一个半字符。每个表项的长度是16,因为半字符一共只有16种可能的取值。显然这是一张6*16的二维表,用PSHUFB可以方便查询其中一行。
设想一下,以FDR的思路实现3字节后缀的话,其掩码表对应256个表项,每个表项长度是3,即这是一张256*3的二维表,表项太多,不宜使用PSHUFB指令进行操作。
细细推敲,不难看出Teddy和FDR的前端掩码表有一种“相对转置”的内在关系,只是一个适合用PSHUFB指令查表,另一个则适合普通LOAD。
Hyperscan 5.3.0以前,Teddy同时有SSSE-3、AVX-2和AVX-512指令集的实现。
● VBMI优化点:
AVX-512版本的Teddy有一个重要的局限:当相邻两个半字符匹配的信息经过OR操作合成,得到一个全字符匹配信息时,下一步需要进行“字节移位”操作(即字节级别的移位),以便与相邻位置的全字符匹配信息进行OR操作,这里的字节移位便是问题所在。
下面给出一例。
图1表示初始状态,第1行的内容是输入字符序列,第2/3/4行是三组掩码,红线表示我们需要将沿线方向的数值进行OR操作,方法是先各自移位至对齐,再执行OR。图2是理想状态下的字节移位结果,每组掩码在128比特边界处的移位操作都不存在信息丢失,因此经过OR操作后,得到的结果向量中的128比特边界位置上都是1,表明这些位置不需要后端关心。
(在SHIFT-OR算法中,置1表示不匹配,置0表示匹配,因此结果向量中的0是需要后端关心的。)

图1 初始状态
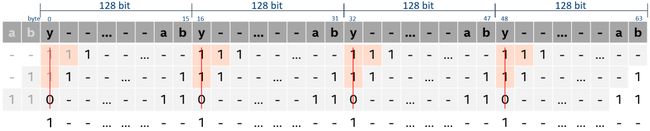
图2 理想的字节移位
AVX-512版本的“字节移位”操作是VPSLLDQ,它虽然可以对512位向量进行字节级别的移位操作,但其执行过程是以每128个比特位为一个操作区间,在操作区间内部进行的是没有信息丢失的字节移位,但当跨越128位操作区间进行字节移位时,则存在信息丢失。
图3展示了VPSLLDQ移位的实际结果,掩码在128比特边界处的字节移位存在信息丢失(由1变成0),这直接导致OR操作的结果向量中出现了0,而这些0本来不该出现,所以它们对后端来说就是false positives。

图3 VPSLLDQ的字节移位
基于此可知,在AVX-512版本Teddy的SHIFT-OR操作结果得到的512位向量中,存在4处位置的信息丢失现象,这4处位置就是和128比特对齐的位置。进一步分析,因为Teddy要匹配3字节后缀,那么字节移位操作需要做2次,这表明每个边界位置所丢失的信息其实是2个字节。
Teddy前端匹配的结果本来就存在固有的false positive,但是在AVX-512实现中,因为指令处理能力的局限,增加了前端结果的信息量丢失,这等价于恶化了前端匹配的精度,会进一步导致Teddy算法后端要处理的false positive大大增加。
其实在当前AVX-512实现中,丢失的精度是通过额外的逻辑进行补偿的,也就是想办法在图3中信息丢失的位置重新填上正确的比特值,缺点是增大了开销,并且也只能补偿1个字节。
总结起来,当前AVX-512版本的Teddy前端的匹配速度已经达到了最快(相较于过去SSSE-3和AVX-2版本),但是精度还比较差,后端压力较大。
在x86平台全新的AVX-512 VBMI指令集中,有新指令VPERMB。如图4,该指令可以对长达64个字节即512比特的范围进行字节级别的混洗操作。可以说该指令是对PSHUFB在512位向量上的正式扩展。
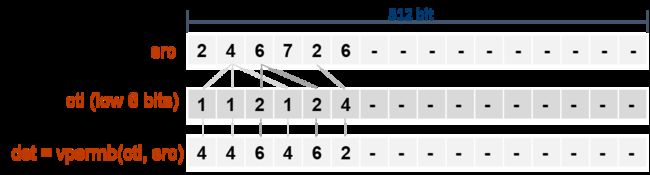
图4 VPERMB指令
VPERMB指令的存在提供了实现“零信息丢失”的字节操作的思路:只要设置合适的控制掩码,其混洗的效果就相当于实现了字节移位。图5给出了移动1个字节的VPERMB实现。当然移动2字节也是类似的。如此可以极大改善使用VPSLLDQ指令进行字节移位带来的精度丢失问题。

图5 VPERMB移位
VPERMB指令解决了在第1/2/3个128比特边界处信息丢失的问题。但是观察图5可知,在第0个128比特边界,也就是最开始位置,仍然无法通过字节移位操作将前一个512向量的结果转移过来。为此仍需要特殊的补偿操作,但相对而言开销就比较微小了。
● 性能提升:
在多字符串匹配微基准测试上,AVX-512 VBMI版本的Teddy相较于AVX-512版本,前端速度相近,提升约1%;后端处理的false positives减少约77%。图6给出了微基准测试下,SSSE-3、AVX-2、AVX-512和AVX-512 VBMI几种版本的Teddy算法的性能对比,同时也加入了传统多字符串匹配算法Aho-Corasick算法的性能结果。

图6 多字符串匹配算法性能对比
在Hyperscan专用的40000个性能测试用例中,在AVX-512基础上的VBMI优化影响约11100个用例,平均吞吐量提升约4.5%,最佳情况下吞吐量提升约5.15倍。
2. 单双字符匹配算法——Vermicelli
● 核心:
在当前SSSE-3实现基础上增加AVX-512支持。
● 算法简介:
Hyperscan内部有一种特殊的加速机制,它考虑的场景是这样的:当要匹配的对象(字符串或者正则表达式)含有某些特殊字符、字符序列或者字符集特征时,是可以考虑采用SIMD指令在早期进行检测它们是否存在的,排除不可能获得匹配的数据块,尽量延缓相对更慢的匹配对象的运行,达到预过滤的效果。
Vermicelli就是对单字符和双字符序列进行匹配的加速算法。通俗点说,它解决的问题是,判断在一段输入中某个字符是否出现或者某两个字符是否依次出现。
Hyperscan 5.3.0以前,Vermicelli只有SSSE-3指令集的实现。
对于单字符的情况,算法先将目标字符广播至128位向量,然后使用PCMPEQB指令与128位输入数据进行对比,得到的结果用PMOVMSKB指令进行压缩,最后使用POPCOUNT查找匹配位置。
对于双字符序列的情况,算法先将2个目标字符分别广播至2个128位向量,然后使用PCMPEQB指令与128位输入数据分别进行对比,然后使用SHIFT-AND方法,得到结果向量,剩余步骤和单字符处理相同。
● AVX-512优化点:
该优化是常规的128位到512位的宽指令集扩展,不涉及新的数据结构设计或者算法修改,主要是在运行期对更长输入数据进行处理。
● 性能提升:
在Hyperscan专用的40000个性能测试用例中,Vermicelli的AVX-512版本相较于SSSE-3版本平均吞吐量提升了约1.8%,最佳情况下吞吐量提升约2.3倍。
B.
测试工具
Fuzz
一个正则表达式随机生成器套件,位于tools/fuzz目录。生成器根据复杂程度分为三种——completocrats.py可以生成某个小规模字符集构成的正则表达式;aristocrats.py可以生成整个ASCII码集构成的正则表达式,这两个脚本对于表达式的语法规则没有显式控制,随机性很强;heuristocrats.py则可以较好模拟具有正则语法形态的表达式构造。使用-h可详细了解脚本功能。
hsbench
拓展了-T参数功能,以前仅可以使用-T CPU,CPU,…形式来指定多核运行,拓展后可以使用-T CPU-CPU形式来指定使用编号连续的多核。
pcap
拓展了tools/hsbench/scripts/pcapCorpus.py脚本对pcap包的分析能力,使其支持VLAN报文。
C.
Bugfix
Github #205
接口hs_compile_lit_multi()在某些编译期或代码检查器中会出错,原因在于处理可能包含‘\0’的输入中使用strlen(),需要规避。
Github #211
接口db_check_platform()对于数据库头存放的目标平台和当前运行平台的相容性判断有误。
Github #217
对于非英文环境,cmake在翻译提取本地CPU架构名称时会失效,可通过优化对CPU架构名称的搜索方法来解决。
Github #228
coverity工具提示util/expressions.cpp中的文件操作存在fdopendir()后跟着closedir()的现象,属于需要规避的未定义行为。
Github #239
gcc-10编译时对src/util/copybyted.h:copy_upto_32_bytes()报-Werror= stringop-overflow错误,实际上代码逻辑可保证内存地址访问的有效性。
NFA中的加速路径分析
在编译期,NFA上的自循环节点需要做逃逸路径查找,以便运行时判断能否快速处理输入,但之前版本实现中,逃逸路径查找不够完整,导致某些情况下存在漏报。
Small-write引擎中的重复匹配
测试发现Small-write引擎中可能会报出重复匹配结果,通过增加重复匹配检测来解决。
hscollider的UTF8支持
过去hscollider对UTF8输入的识别并未考虑表达式的UTF8标识是否有效。
D.
其他
Github #221
在src/hwlm/noodle_engine_avx2.c: scanDoubleFast()中,调整局部变量的类型定义,避免编译器带来多余的类型转化操作后对性能带来的消极影响。
Github #222
在Hyperscan库的头文件中增加版本号的宏定义。

DPDK与SPDK开源社区公众号文章转载声明
推荐阅读
DPDK Virtio Performance
SPDK发布v20.04版本
Barefoot P4加速SDN