Python爬虫 微信好友分析与自动回复
Python爬虫
项目环境
1.运行平台:Windows
2.Python版本:Python3.6
3.IDE:Sublime Text3
项目知识点
1.python爬虫的基本知识
2.一些可视化工具的使用(pyecharts)
3.python图片工具PIL库的使用
4.自然语言处理工具包结巴分词的使用
5.微信网页api工具itchat的使用
项目的功能
1.统计好友的性别,并在扇形图中表示
2.统计好友的昵称,并做成词云显示
3.统计好友个性签名中的高频词汇,并做成词云显示
4.统计好友的地域分布,并且可视化在地图上展示
5.微信自动回复消息功能(图灵机器人)
功能展示
01统计好友性别

以上就是我的微信好友啦,一共有229人,其中男性占据60%多,女性占据36%左右,其他这类人表示的是未填写性别信息的好友。
代码实现
#统计性别饼状图
def get_pie(item_name,item_name_list,item_num_list):
#计算好友总数
totle = item_num_list[0]+item_num_list[1]+item_num_list[2]
subtitle = "共有:%d个好友"%totle
#构造实例
pie = Pie(item_name,page_title = item_name,title_text_size=30,title_pos='center',\
subtitle = subtitle,subtitle_text_size = 25,width=800,height= 800)
#添加数据
pie.add("", item_name_list, item_num_list,is_label_show=True,center=[50, 45],radius=[0,50],\
legend_pos ='left',legend_orient='vertical',label_text_size=20)
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
pie.render(out_file_name)
02统计好友地域分布
微信好友都集中在广东地区,因为本人在广东生活,在广东上上大学中,所有这里的统计数据就不怎么好。
代码实现
#统计地域分布条形图
def get_bar(item_name,item_name_list,item_num_list):
#构造实例
bar = Bar(item_name,page_title = item_name,title_text_size=30,title_pos='center')
#添加数据
bar.add("", item_name_list, item_num_list,title_pos='center', xaxis_interval=0,xaxis_rotate=27,\
xaxis_label_textsize = 20,yaxis_label_textsize = 20,yaxis_name_pos='end',yaxis_pos = "%50")
bar.show_config()
grid = Grid(width=1300,height= 800)
grid.add(bar,grid_top = "13%",grid_bottom = "23%",grid_left = "15%",grid_right = "15%")
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
grid.render(out_file_name)
03好友地域分布可视化

这里我也有点无奈,基本所有好友都在广东,所有这里的可视化并不怎么明显。如果大家有兴趣,可以试试可视化在一个省区,这样看到是好友分布在各个市区,效果可能好一点。
代码实现
#地图可视化
def get_map(item_name,item_name_list,item_num_list):
#构造实例
_map = Map(item_name,width=1300,height= 800,title_pos='center',title_text_size=30)
#添加数据
_map.add("", item_name_list, item_num_list, maptype='china', is_visualmap=True, visual_text_color='#000')
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
_map.render(out_file_name)
03好友昵称词云
 这里涉及到个人信息,请不要复制图片。这里有个问题,明明是统计好友的昵称,但词云中有些是我的微信好友的备注,不知道什么原因,有空再仔细研究。
这里涉及到个人信息,请不要复制图片。这里有个问题,明明是统计好友的昵称,但词云中有些是我的微信好友的备注,不知道什么原因,有空再仔细研究。
代码实现
#制作词云
def word_cloud(item_name,item_name_list,item_num_list,word_size_range):
#构造实例
wordcloud = WordCloud(width=1400,height= 900)
#添加数据
wordcloud.add("", item_name_list, item_num_list,word_size_range=word_size_range,shape='pentagon')
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
wordcloud.render(out_file_name)
04好友个性签名高频词汇

在这个词云上移动鼠标会显示相应词汇出现的次数,字体越大说明该词汇出现的次数越高。这里有些是表情包吧,直接显示了emoji,据说添加一些东西或者第三方包吧可以把表情包显示出来,可惜我不会,不好意思了。
代码实现
#制作词云
def word_cloud(item_name,item_name_list,item_num_list,word_size_range):
#构造实例
wordcloud = WordCloud(width=1400,height= 900)
#添加数据
wordcloud.add("", item_name_list, item_num_list,word_size_range=word_size_range,shape='pentagon')
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
wordcloud.render(out_file_name)
05合成好友的头像
这里实现的原理就是下载好友的头像,然后按一定比例压缩再合成一张大图,这里使用了PIL工具合成一张大图,上面就是我的好友头像做成的一张大图。
代码
#合成头像
def mergeImage():
print("正在合成头像")
#对用户头像进行压缩
photo_width = 200
photo_height = 200
#图像路径list
photo_path_list = []
#获取当前路径
dirName = os.getcwd()+'/images'
#遍历文件夹获取所有图片的路径
for root, dirs, files in os.walk(dirName):
for file in files:
if "jpg" in file:
photo_path_list.append(os.path.join(root, file))
pic_num = len(photo_path_list)
#每行每列显示图片数量,调整为正方形的大图片
line_max = int(math.sqrt(pic_num))
row_max = int(math.sqrt(pic_num))
if line_max > 20:
line_max = 20
row_max = 20
num = 0
#最大照片数量
pic_max=line_max*row_max
#创建新图片:Image.new(mode,size)
toImage = Image.new('RGBA',(photo_width*line_max,photo_height*row_max))
for i in range(0,row_max):
for j in range(0,line_max):
#获取照片
pic_fole_head = Image.open(photo_path_list[num])
#获取照片的大小
width,height = pic_fole_head.size
#压缩照片大小
tmppic = pic_fole_head.resize((photo_width,photo_height))
#计算图片拼接的坐标
loc = (int(j%row_max*photo_width),int(i%row_max*photo_height))
#在相应位置添加照片
toImage.paste(tmppic,loc)
num= num+1
if num >= len(photo_path_list):
break
if num >= pic_max:
break
#保存合成的照片
print(toImage.size)
toImage.save('./analyse/merged.png')
06微信自动回复消息
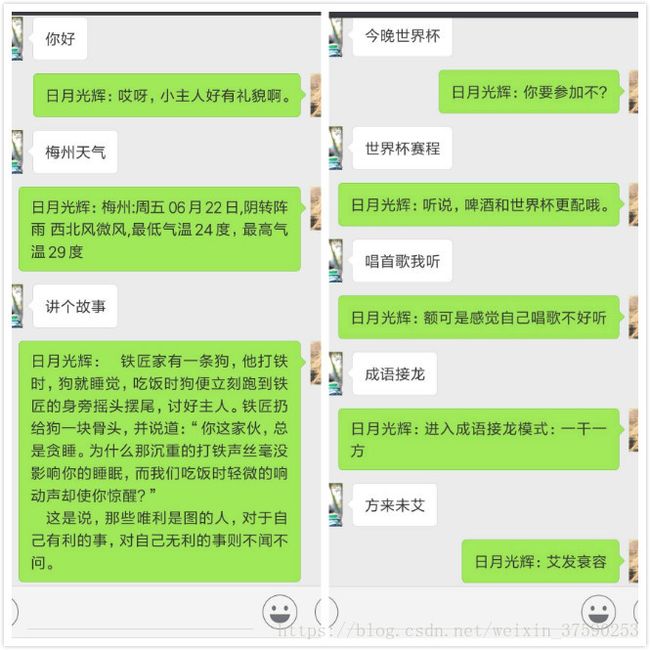 ‘
‘
这里的自动回复调用了图灵机器人,个人可再官网注册一个点击打开链接
API地址:http://www.tuling123.com/openapi/api
APIkey:自己在官网申请一个就可以了
代码实现
#KEY = '8edce3ce905a4c1dbb965e6b35c3834d'
#图灵机器人
def get_response(msg):
apiUrl = 'http://www.tuling123.com/openapi/api'
data = {
'key' : KEY,
'info' : msg,
'userid' : 'wechat-robot',
}
try:
r = requests.post(apiUrl, data=data).json()
return r.get('text')
except:
return
#登陆微信
@itchat.msg_register(itchat.content.TEXT)
def tuling_reply(msg):
defaultReply = 'I received: ' + msg['Text']
reply = "日月光辉:"+get_response(msg['Text'])
return reply or defaultReply总结
该项目是参考实现的,以及查阅官方文档,若有雷同敬请原谅,本人只是用来学习交流。项目中的词云可以生成其他形状的,拿一张背景图就能实现了,具体实现过程请自行查阅相关文档。图灵机器人的回答正确率65%,可以自行导入问题与答案。当然项目中还有一些BUG,有待改进。
完整代码
获取好友信息
import itchat
import json
import requests
sex_dict = {}
sex_dict['0'] = "其他"
sex_dict['1'] = "男"
sex_dict['2'] = "女"
#图灵机器人APIkey
KEY = '8edce3ce905a4c1dbb965e6b35c3834d'
#下载好友头像
def download_images(frined_list):
image_dir = "./images/"
num = 1
for friend in frined_list:
image_name = str(num)+'.jpg'
num+=1
img = itchat.get_head_img(userName=friend["UserName"])
with open(image_dir+image_name, 'wb') as file:
file.write(img)
def save_data(frined_list):
out_file_name = "./data/friends.json"
with open(out_file_name, 'w',encoding='utf-8') as json_file:
json_file.write(json.dumps(frined_list,ensure_ascii=False))
#图灵机器人
def get_response(msg):
apiUrl = 'http://www.tuling123.com/openapi/api'
data = {
'key' : KEY,
'info' : msg,
'userid' : 'wechat-robot',
}
try:
r = requests.post(apiUrl, data=data).json()
return r.get('text')
except:
return
#登陆微信
@itchat.msg_register(itchat.content.TEXT)
def tuling_reply(msg):
defaultReply = 'I received: ' + msg['Text']
reply = "日月光辉:"+get_response(msg['Text'])
return reply or defaultReply
if __name__ == '__main__':
itchat.auto_login()
friends = itchat.get_friends(update=True)[0:]#获取好友信息
friends_list = []
for friend in friends:
item = {}
item['NickName'] = friend['NickName']
item['HeadImgUrl'] = friend['HeadImgUrl']
item['Sex'] = sex_dict[str(friend['Sex'])]
item['Province'] = friend['Province']
item['Signature'] = friend['Signature']
item['UserName'] = friend['UserName']
friends_list.append(item)
#print(item)
save_data(friends_list)
download_images(friends_list)
itchat.run()分析好友数据
#coding=utf-8
import json
from pyecharts import Bar
from pyecharts import Grid
from pyecharts import WordCloud
from pyecharts import Pie
from pyecharts import Map
from collections import Counter
import jieba.analyse
import PIL.Image as Image
import os
import math
import requests
#统计性别饼状图
def get_pie(item_name,item_name_list,item_num_list):
#计算好友总数
totle = item_num_list[0]+item_num_list[1]+item_num_list[2]
subtitle = "共有:%d个好友"%totle
#构造实例
pie = Pie(item_name,page_title = item_name,title_text_size=30,title_pos='center',\
subtitle = subtitle,subtitle_text_size = 25,width=800,height= 800)
#添加数据
pie.add("", item_name_list, item_num_list,is_label_show=True,center=[50, 45],radius=[0,50],\
legend_pos ='left',legend_orient='vertical',label_text_size=20)
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
pie.render(out_file_name)
#统计地域分布条形图
def get_bar(item_name,item_name_list,item_num_list):
#构造实例
bar = Bar(item_name,page_title = item_name,title_text_size=30,title_pos='center')
#添加数据
bar.add("", item_name_list, item_num_list,title_pos='center', xaxis_interval=0,xaxis_rotate=27,\
xaxis_label_textsize = 20,yaxis_label_textsize = 20,yaxis_name_pos='end',yaxis_pos = "%50")
bar.show_config()
grid = Grid(width=1300,height= 800)
grid.add(bar,grid_top = "13%",grid_bottom = "23%",grid_left = "15%",grid_right = "15%")
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
grid.render(out_file_name)
#地图可视化
def get_map(item_name,item_name_list,item_num_list):
#构造实例
_map = Map(item_name,width=1300,height= 800,title_pos='center',title_text_size=30)
#添加数据
_map.add("", item_name_list, item_num_list, maptype='china', is_visualmap=True, visual_text_color='#000')
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
_map.render(out_file_name)
#制作词云
def word_cloud(item_name,item_name_list,item_num_list,word_size_range):
#构造实例
wordcloud = WordCloud(width=1400,height= 900)
#添加数据
wordcloud.add("", item_name_list, item_num_list,word_size_range=word_size_range,shape='pentagon')
#文件输出地址与文件名
out_file_name = './analyse/'+item_name+'.html'
#生成HTML文件
wordcloud.render(out_file_name)
def get_item_list(first_item_name,dict_list):
item_name_list = [] #名称列表
item_num_list = [] #数量列表
i = 0
for item in dict_list:
i+=1
if i >=15:
break
for name,num in item.items():
if name != first_item_name:
item_name_list.append(name)
item_num_list.append(num)
return item_name_list,item_num_list
#提取名称元素和数量元素
def dict2list(_dict):
name_list = []
num_list = []
for key,value in _dict.items():
name_list.append(key)
num_list.append(value)
return name_list,num_list
#提取名称和对应好友的数量
def counter2list(_counter):
name_list = []
num_list = []
for item in _counter:
name_list.append(item[0])
num_list.append(item[1])
return name_list,num_list
def get_tag(text,cnt):
print ('正在分析句子:',text)
#结巴词的使用
tag_list = jieba.analyse.extract_tags(text)
for tag in tag_list:
cnt[tag] += 1
#合成头像
def mergeImage():
print("正在合成头像")
#对用户头像进行压缩
photo_width = 200
photo_height = 200
#图像路径list
photo_path_list = []
#获取当前路径
dirName = os.getcwd()+'/images'
#遍历文件夹获取所有图片的路径
for root, dirs, files in os.walk(dirName):
for file in files:
if "jpg" in file:
photo_path_list.append(os.path.join(root, file))
pic_num = len(photo_path_list)
#每行每列显示图片数量,调整为正方形的大图片
line_max = int(math.sqrt(pic_num))
row_max = int(math.sqrt(pic_num))
if line_max > 20:
line_max = 20
row_max = 20
num = 0
#最大照片数量
pic_max=line_max*row_max
#创建新图片:Image.new(mode,size)
toImage = Image.new('RGBA',(photo_width*line_max,photo_height*row_max))
for i in range(0,row_max):
for j in range(0,line_max):
#获取照片
pic_fole_head = Image.open(photo_path_list[num])
#获取照片的大小
width,height = pic_fole_head.size
#压缩照片大小
tmppic = pic_fole_head.resize((photo_width,photo_height))
#计算图片拼接的坐标
loc = (int(j%row_max*photo_width),int(i%row_max*photo_height))
#在相应位置添加照片
toImage.paste(tmppic,loc)
num= num+1
if num >= len(photo_path_list):
break
if num >= pic_max:
break
#保存合成的照片
print(toImage.size)
toImage.save('./analyse/merged.png')
if __name__ == '__main__':
in_file_name = './data/friends.json'
with open(in_file_name,encoding='utf-8') as f:
friends = json.load(f)
#待统计参数
sex_counter = Counter()#性别
Province_counter = Counter()#省份
NickName_list = [] #昵称
Signature_counter = Counter()#个性签名关键词
for friend in friends:
#统计性别
sex_counter[friend['Sex']]+=1
#省份
if friend['Province'] != "":
Province_counter[friend['Province']]+=1
#昵称
NickName_list.append(friend['NickName'])
#签名关键词提取
get_tag(friend['Signature'],Signature_counter)
#性别
name_list,num_list = dict2list(sex_counter)
get_pie('性别统计',name_list,num_list)
#省份前15
name_list,num_list = counter2list(Province_counter.most_common(15))
get_bar('地区统计',name_list,num_list)
#地图
get_map('微信好友地图可视化',name_list,num_list)
#昵称
#默认每个昵称出现的次数为1
num_list = [1 for i in range(1,len(NickName_list)+1)]
word_cloud('微信好友昵称',NickName_list,num_list,[18,18])
#微信好友签名关键词
name_list,num_list = counter2list(Signature_counter.most_common(200))
word_cloud('微信好友签名关键词',name_list,num_list,[20,100])
#头像合成
mergeImage()