TensorFlow有两种数据格式NHWC和NCHW
TensorFlow有两种数据格式NHWC和NCHW,默认的数据格式是NHWC,可以通过参数data_format指定数据格式。这个参数规定了 input Tensor 和 output Tensor 的排列方式。
1、data_format
设置为 “NHWC” 时,排列顺序为 [batch, height, width, channels]
设置为 “NCHW” 时,排列顺序为 [batch, channels, height, width]

如果我们需要对图像做彩色转灰度计算,NCHW 计算过程如下:
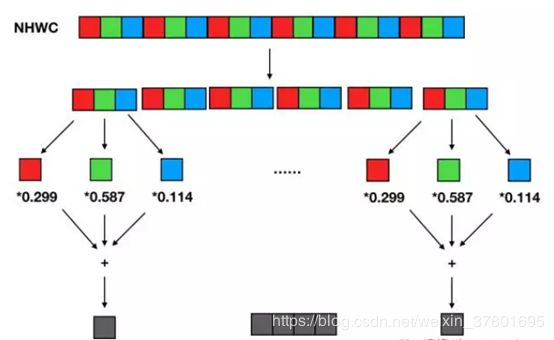
即 R 通道所有像素值乘以 0.299,G 通道所有像素值乘以 0.587,B 通道所有像素值乘以 0.114,最后将三个通道结果相加得到灰度值。
相应地,NHWC 数据格式的彩色转灰度计算过程如下:
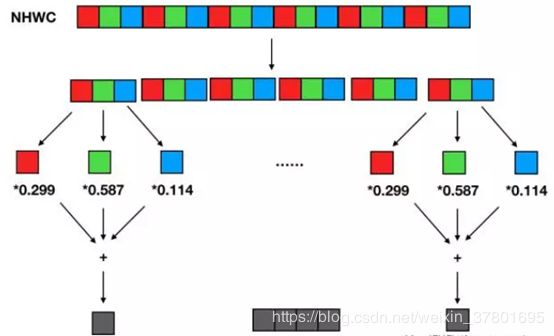
输入数据分成多个(R, G, B) 像素组,每个像素组中 R 通道像素值乘以 0.299,G 通道像素值乘以 0.587,B 通道像素值乘以 0.114 后相加得到一个灰度输出像素。将多组结果拼接起来得到所有灰度输出像素。
以上使用两种数据格式进行 RGB -> 灰度计算的复杂度是相同的,区别在于访存特性。通过两张图对比可以发现,NHWC 的访存局部性更好(每三个输入像素即可得到一个输出像素),NCHW 则必须等所有通道输入准备好才能得到最终输出结果,需要占用较大的临时空间。
在 CNN 中常常见到 1x1 卷积(例如:用于移动和嵌入式视觉应用的 MobileNets),也是每个输入 channel 乘一个权值,然后将所有 channel 结果累加得到一个输出 channel。如果使用 NHWC 数据格式,可以将卷积计算简化为矩阵乘计算,即 1x1 卷积核实现了每个输入像素组到每个输出像素组的线性变换。
TensorFlow 为什么选择 NHWC 格式作为默认格式?因为早期开发都是基于 CPU,使用 NHWC 比 NCHW 稍快一些(不难理解,NHWC 局部性更好,cache 利用率高)。
NCHW 则是 Nvidia cuDNN 默认格式,使用 GPU 加速时用 NCHW 格式速度会更快(也有个别情况例外)。
最佳实践:设计网络时充分考虑两种格式,最好能灵活切换,在 GPU 上训练时使用 NCHW 格式,在 CPU 上做预测时使用 NHWC 格式。
2、两种数据格式相互转换
NHWC –> NCHW:
import tensorflow as tf
x = tf.reshape(tf.range(24), [1, 3, 4, 2])
out = tf.transpose(x, [0, 3, 1, 2])
NCHW –> NHWC:
import tensorflow as tf
x = tf.reshape(tf.range(24), [1, 2, 3, 4])
out = tf.transpose(x, [0, 2, 3, 1])
3、深度学习为什么需要GPU
高带宽
首先,大家必须得明白CPU是基于延迟优化的,而GPU是基于带宽优化的。CPU与GPU就像法拉利与卡车,两者的任务都是从随机位置A提取货物(即数据包),并将这些货物传送到另一个随机位置B,法拉利(CPU)可以快速地从RAM里获取一些货物,而大卡车(GPU)则慢很多,有着更高的延迟。但是,法拉利传送完所有货物需要往返多次
换句话说,CPU更擅长于快速获取少量的内存(537),GPU则更擅长于获取大量的内存(矩阵乘法:(A*B)*C)。另一方面,最好的CPU大约能达到50GB/s的内存带宽,而最好的GPU能达到750GB/s的内存带宽。因此,在内存方面,计算操作越复杂,GPU对CPU的优势就越明显。
然而,延迟的存在仍然会影响着GPU的性能,就像大卡车虽然可以在每次运输中提取大量的货物,但问题是,你必须花上很长的时间来等待下一批货物到达。如果这个问题不能被解决,即使是处理大量的数据,GPU的速度也会变得很慢。
那么,如何解决这个问题呢?
多线程并行
如果让大卡车往返多次来提取货物,一旦卡车已经出发,你将会花上大量的时间来等待下一次的货物装载,毕竟卡车速度很慢。然而,如果你使用一队法拉利或大卡车(即多线程并行)来运输大量的货物(例如像矩阵一样的大块内存),那么你只需要花上一点时间来等待第一次运输,之后就无需等待了,因为卸货的过程长,此时所有卡车都在B区排队卸货,所以你可以直接在B区取到你的货物。
这种方法有效地隐藏了延迟,GPU可以在多线程并行下隐藏延迟的同时提供高带宽,因此,对于大块内存来说,GPU提供了几乎没有缺点的最佳内存带宽。这是为什么GPU比CPU在处理深度学习上更快速的第二个理由。顺带一提,你会慢慢明白为什么多线程对CPU没有意义:一队法拉利在任何情况下都没有实际的好处。
GPU的好处还不只这些。将内存从RAM提取到本地存储(L1 cache and registers),这只是第一步。而第二步虽然对性能影响较小,但却是为GPU锦上添花。
所有被执行的计算都在寄存器中发生,寄存器直接连接着执行单元(一个核心CPU和一连串的GPU处理器)。通常情况下,我们想让高速L1缓存和靠近执行引擎的寄存器尽可能的小,以提高访问速度。而增加它们到执行引擎之间的距离会显著降低内存的访问速度,距离越大,反过来内存访问效率就会越慢(就好比即使你知道你想买的东西在大商店里的具体位置,而在小商店里找到它也往往比在大商店里容易)。因此,在寄存器文件大小和计算精度受限的情况下,我们希望这个距离尽可能的小。
GPU有许多处理单元(流处理器,或者SM),且每个处理单元中都有一组寄存器,这样,GPU就有着大量体积小、处理速度快的寄存器,这也是GPU的优点。由此,GPU的寄存器总量比CPU所拥有的30倍还多,处理速度也快了一倍,相当于14M的寄存器能够达到 80TB/s的速度。
相比之下,CPU 的L1 缓存只能达到大约5TB/s,这是相当慢的,并且还需要占用1MB的大小;而GPU寄存器通常只需要占用大概64-128KB的大小,就能达到10-20TB/s的速度。当然,这个数字的比较有一点小小的缺陷,因为CPU寄存器和GPU寄存器在运行方式上有一点不同(有一点像苹果和橙子),但在这里,大小的差异比速度的差异更重要,而且大小是确实存在差异的。
可调整的L1缓存和寄存器
另一方面,GPU寄存器的充分利用似乎很难实现,因为它作为最小的计算单元,需要进行微调来满足高性能。关于这个问题,NVIDIA已经开发出了很好的编译工具,它可以准确地指出你使用了多少寄存器,让你更容易调整GPU代码,合理安排寄存器和L1 缓存的数量以获得快速的性能,这就使得GPU比其他诸如Xeon Phis一类的架构有优势,在Xeon Phis中,这种寄存器利用模式难以实现也难以调试,从而使得Xeon Phis在运行上难以获得最佳效果。
最终,这意味着你可以在GPU的L1 缓存和寄存器中存储大量数据来反复计算卷积和矩阵乘法。如果你有一个100MB的矩阵,你可以把它拆分为适合你缓存和寄存器的多个小矩阵,然后用10-80TB/s的速度做三个矩阵块的乘法,处理速度非常快。这也是GPU比CPU快且更适合于深度学习的第三个原因。
请记住,性能的瓶颈往往是较慢的内存。
本文综合以下三篇文章
https://blog.csdn.net/JNingWei/article/details/78156011
https://mp.weixin.qq.com/s/I4Q1Bv7yecqYXUra49o7tw
https://www.sohu.com/a/196892449_804770