深度学习之文本相似度Paper总结
Tree-based CNN encoders
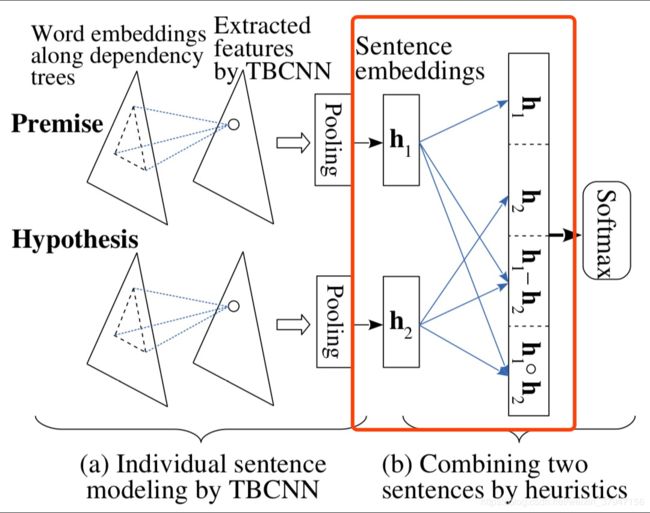
注意这里红框内的拼接部分,除了对 pp 和 hh 做简单的拼接之外,还做了 p−hp−h,p⋅hp⋅h 的操作,作者给出的解释是:
The latter two are certain measures of “similarity” or “closeness.”
于是最后拼接起来的向量为 m=[p;h;p−h;p⋅h]m=[p;h;p−h;p⋅h]。注意一下这个拼接方式,因为后续的很多模型最后都是用这种拼接方法的类似方法来做的,足以见得这种方法的有效性。
Structured Self Attention
A Structured Self-Attentive Sentence Embedding 是发表在 ICLR2017 上的一篇文章,其本质上是对输入序列做 self-attention 操作,与普通 self-attention 不同的是,这篇文章的做法是将得到的 attention 权重扩展到了 rr 维,这样就得到了一个二维的句向量表示 (r×n)(r×n)。其实也就是将原本的 (1×n)(1×n) 的 attention 权重映射到了 rr 个不同的子空间上。
至于为什么要这么做,作者给出了解释:普通的 self-attention 会使得模型关注句子的一个特定的部分,也就是跟目标更加相关的单词或者短语的地方,希望通过突出这个部分来更好地表示这个句子的意思。然而,在很多情况下,尤其是遇到一个长句子的时候,句子中通常会有多个比较重要的部分,这时候你再只关注其中一块的话就有点不够用了,所以需要多个子空间才能够完整地表示整个句子的意思。
模型图如下所示:
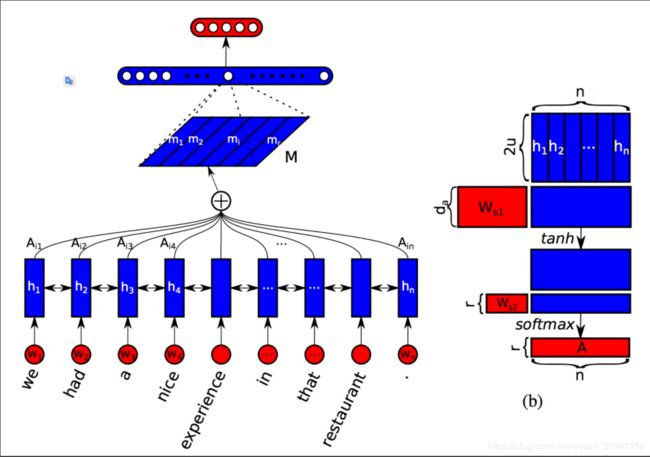

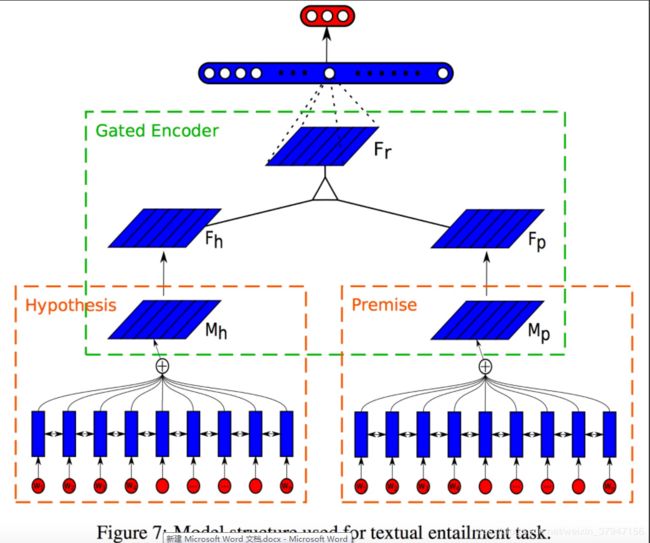
本文将这种 sentence embedding 的方法用在了 NLI 任务上来检验效果,模型图如下所示:
Decomposable Attention 代码
这篇文章全名是 A Decomposable Attention Model for Natural Language Inference,是 Google 那帮大佬发表在 EMNLP2016 的一篇文章。
简评:
这篇论文的核心就是alignment,即词与词的对应关系,文中的alignment用在了两个地方,一个attend部分,是用来计算两个句子之间的attention关系,另一个是compare部分,对两个句子之间的词进行比较,每次的处理都是以词为单位的,最后用前馈神经网络去做预测。很明显可以看到,这篇文章提到的模型并没有使用到词在句子中的时序关系,更多的是强调两句话的词之间的对应关系(alignment),正如文中Introduction提到的一个例子,
文章开头先给出了个例子:
- Bob is in his room, but because of the thunder and lightning outside, he cannot sleep.
- Bob is awake.
- It is sunny outside.
第一句是前提,后面是假说。第二句话中的Bob与第一句话中的Bob对应上,awake与cannot sleep对应上,从而来判断说第一句跟第二句的entailment关系。
再看第三句话,这里的sunny与thunder,lightning对应上,从而判断它们是contradiction的关系。本文利用这种直觉从而建立了基于alignment思想的模型。在SNLI任务上也取得了很好的效果,除此之外,本文还有一个亮点就是大大减少了模型的参数,有兴趣的可以查看论文的第四章。
出于这种思想,Google 这帮大佬们认为,其实我们直接把原问题分解开,看成一个个单词间的对齐问题不就完事儿了?大道至简。
主要方法:
每个训练数据由三个部分组成,,模型的输入为,,分别代表前提和假说,表示a和b之间的关系标签,C为输出类别的个数,因此y是个C维的0,1向量。训练目标就是根据输入的a和b正确预测出他们的关系标签y。
本文的模型主要分成三个部分:Attend,Compare,Aggregate。如下图所示:
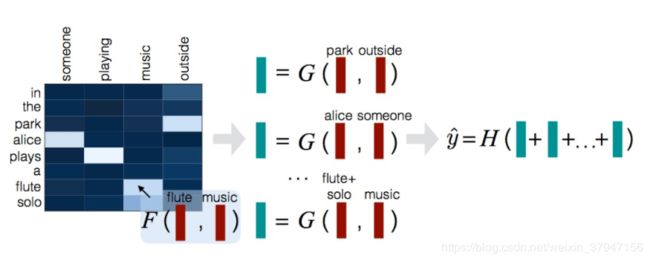
1.Attend
首先对a和b中的每个词计算它们之间的attention weights,计算公式如下:
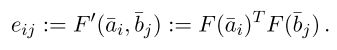
这里F是一个激活函数为RELU的前馈神经网络。
然后用这个attention weights分别对a和b进行归一化以及加权,
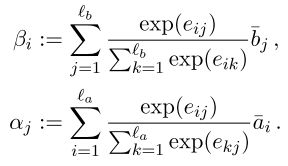
2.Compare
该模块的功能主要是对加权后的一个句子与另一个原始句子进行比较,
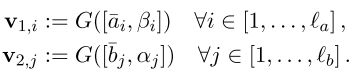
这里[.,.]表示向量拼接,G()依旧是一个前馈神经网络。
3.Aggregate
现在我们得到了两个比较向量的集合,,,先分别对两个向量集合进行求和,
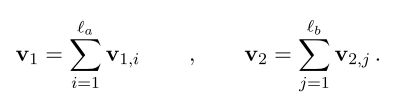
然后将求和的结果输入前馈神经网络做最后的分类。
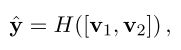
训练用多分类的交叉熵作为损失函数,
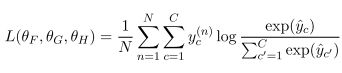
4.Intra-Sentence Attention(optional)
除了上述的基础模型之外,可以在每个句子中使用句子内的attention方式来加强输入词语的语义信息,
![]()
这里的依然是一个前馈神经网络,利用得到的权值f重新对词进行加权,即得到self-aligned(自对应)的短语,
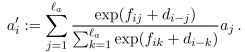
这里的表示当前词i与句子中的其他词j之间的距离偏差,距离大于10的词共享一个距离偏差(distance-sensitive bias),这样每一个时刻的输入就变为原始输入跟self-attention后的值的拼接所得到的向量,
,

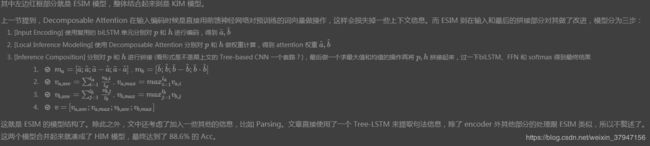
ESIM
ESIM 模型算是 NLI 领域未来几年一个很难绕过的超强 baseline 了,单模型的效果可以达到 88.0% 的 Acc,简直吊打一帮人。
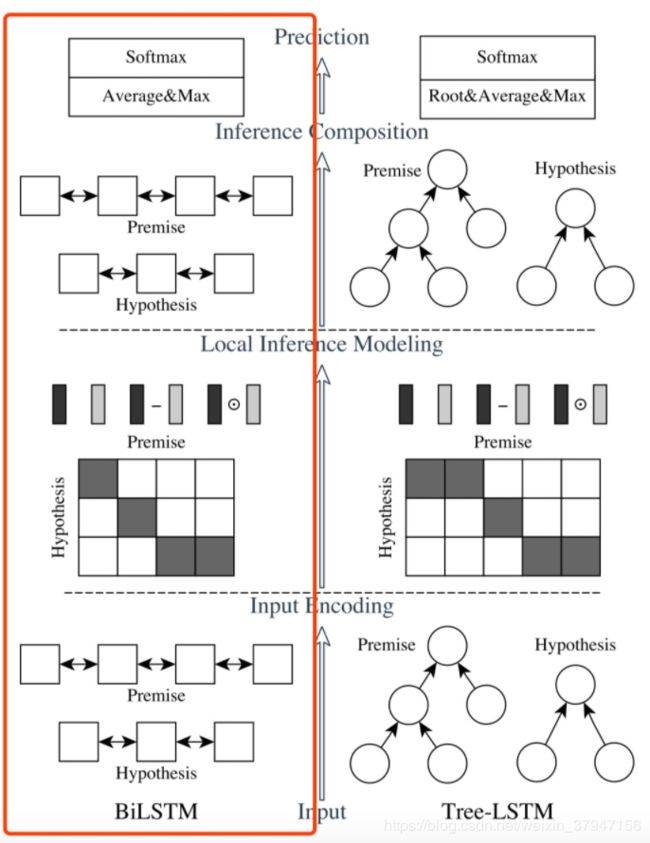
ESIM 模型出自 Qian Chen 等人发表在 ACL2017 上的 Enhanced LSTM for Natural Language Inference。也算是对 Decomposable Attention 的一个改进,然后它还加入了句法信息,组成了 HIM 模型,这种思想也为 NLI 后续的研究提供了一个思路。模型图如下所示,它的主要组成为:输入编码,局部推理建模和推理组合。图1中垂直方向描绘了三个主要组件,水平方向,左侧代表连续语言推断模型,名为ESIM,右侧代表在树LSTM中包含语法分析信息的网络。
这里用![]() 和
和![]() 分别表示两个句子,其中
分别表示两个句子,其中![]() 表示句子a的长度,
表示句子a的长度,![]() 表示句子b的长度,这里在原文中a又称为前提,b为假设。
表示句子b的长度,这里在原文中a又称为前提,b为假设。
1.输入编码
采用BiLSTM(双向LSTM)构建输入编码,使用该模型对输入的两个句子分别编码,表示如下(1)(2)所示:
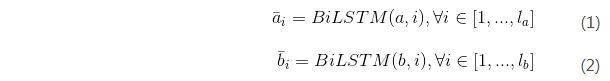
我们将输入序列在时间由BiLSTM生成的隐藏(输出)状态写为![]() 。这同样适用于。
。这同样适用于。
2.局部推理建模
这里使用点积的方式计算和之间的attention权重,公式如(3)所示,论文作者提到attention权重他们也尝试了其他更加复杂的方法,但是并没有取得更好的效果。

计算两个句子之间的交互表示:
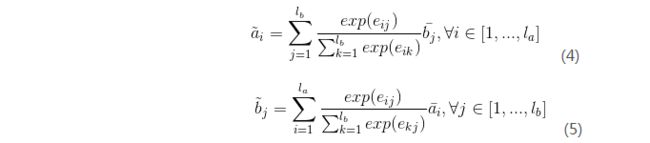
其中![]() 的加权求和。
的加权求和。
通过计算元组![]() 的差和元素乘积来增强局部推理信息。增强后的局部推理信息如下:
的差和元素乘积来增强局部推理信息。增强后的局部推理信息如下:
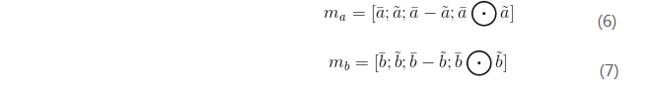
3.推理组成
使用BiLSTM来提取![]() 的局部推理信息,对于BiLSTM提取到的信息,作者认为求和对序列长度比较敏感,不太健壮,因此他们采用了:最大池化和平均池化的方案,并将池化后的结果连接为固定长度的向量。如下:
的局部推理信息,对于BiLSTM提取到的信息,作者认为求和对序列长度比较敏感,不太健壮,因此他们采用了:最大池化和平均池化的方案,并将池化后的结果连接为固定长度的向量。如下:

然后将放入一个全连接层分类器中进行分类。
BiMPM
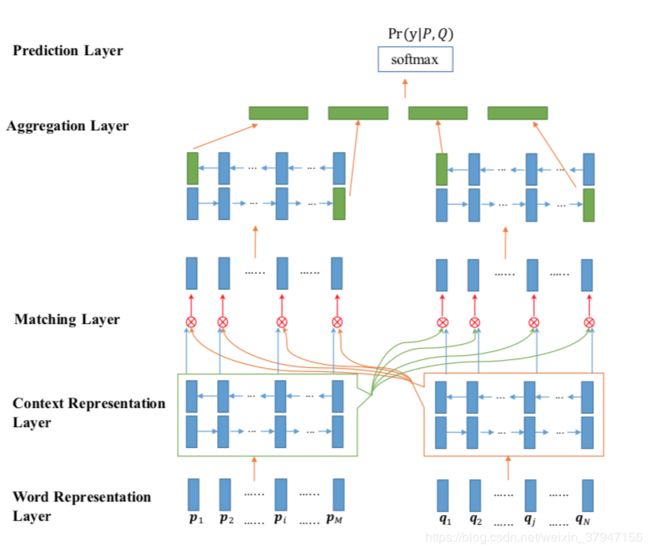
本文介绍论文《Bilateral Multi-Perspective Matching for Natural Language Sentences》的相关工作,之前的论文更多的是设计一个角度的matching function用于精确的捕获question和answer之间的相似度,本文作者则觉得每个matching function都能捕获不同角度的相似度,如果把各个角度计算得到的相似度融合即可获得一个合理的matching result,最后作者通过实验在各个数据集上对该思想进行了验证。
Word Representation Layer
本文用word和character表示input representation。通过将每个word的character通过LSTM模型计算representation。
Context Representation Layer
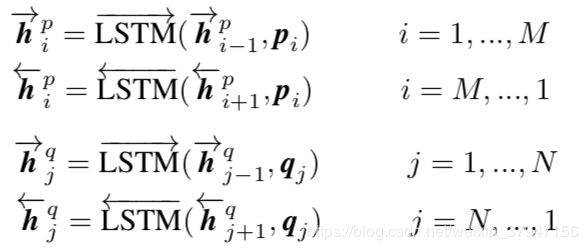
将question和answer embedding向量通过时序模型LSTM,用于获得每个时间状态的特征表示。后续matching layer需要对每个时间状态的特征进行处理。
Matching Layer
![]()
作者通过cosine函数计算两个向量之间的相似度。注意稍有不同在于上式通过一个可学习参数来统计不同维度的相似度。
下面介绍四种不同的matching function
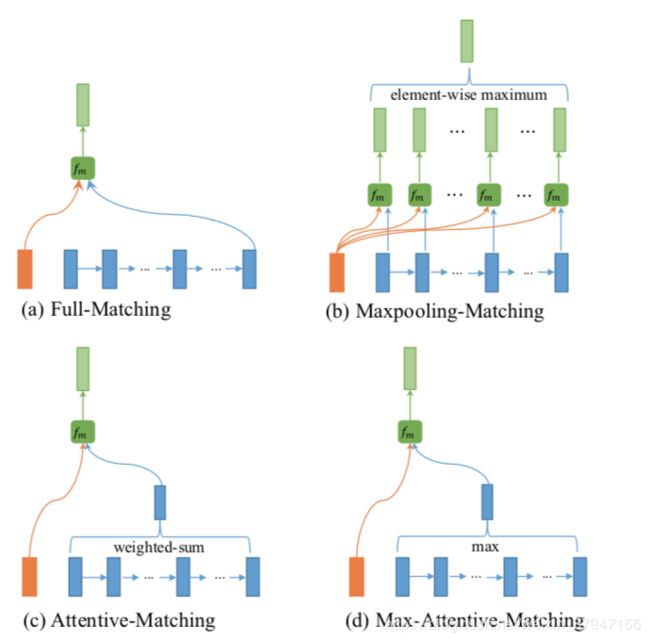
1、首先介绍full-matching,时序模型最后一个时刻的状态输出保持了整个序列的信息,通过该状态对另一个时序模型状态计算相似度。
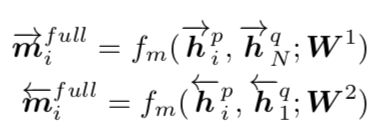
2、下面介绍maxpooling-matching,通过一个时序模型的所有状态输出对另一个时序模型的所有状态输出进行计算,然后抽取每个词相对于另一个文本中最大相似度的词对应的相似度。
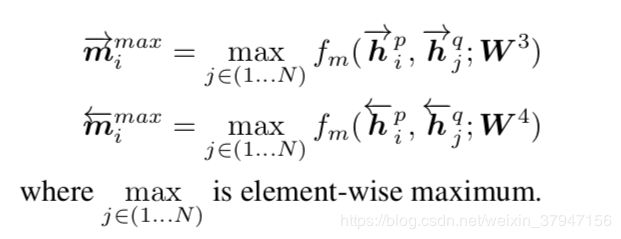
3、接下来介绍attentive-matching,一个很自然的想法就是通过attentive的方式对match-function进行表示。首先计算question和answer之间的相似矩阵,然后通过相似矩阵对answer进行加权作为question align向量,最后通过该向量和question计算attentive-matching相似度。

4、最后介绍Max-Attentive-Matching。首先计算相似度向量,然后计算最大相似度值对应的位置(每行的最大值为当前word对应另一个文本中相似度最大的word)。
Aggregation Layer
在获得了question和answer各自多个角度的representation之后,本文通过一个共享参数的LSTM模型对上述特征进行融合,分别抽取前向和后向最后一个状态的输出。
Prediction Layer
最后通过一个2层的feedforward函数对融合特征进行投影,用于获得classification的特征。
CAFE
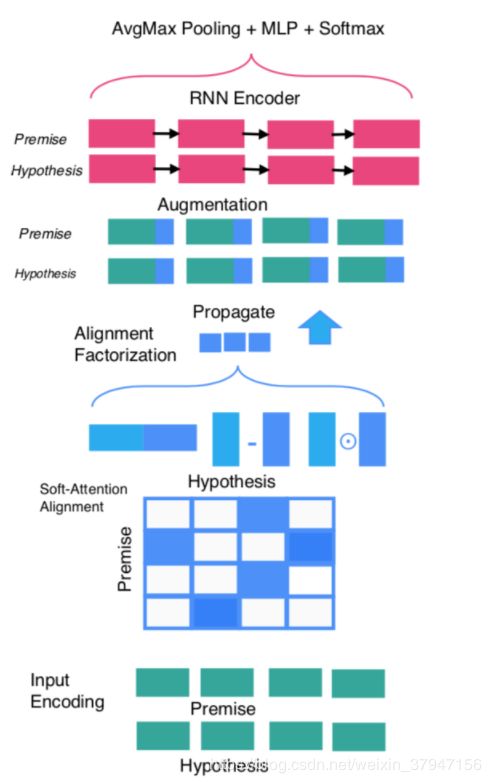
本文介绍论文《Compare, Compress and Propagate: Enhancing Neural Architectures with Alignment Factorization for Natural Language Inference》的相关工作,分别以co-attention和self-attention两个方向进行feature augment,然后在compare层引入factorization layer分别处理compare函数输出向量,最后通过一个时序模型对feature进行编码。
Input Encoding Layer
与上文类似,本文同样采用了word embedding、character embedding和pos,然后进行concatenate输入highway network进行投影。
Soft-Attention Alignment Layer
然后是计算alignment representation。本文从两个角度分别计算alignment representation,然后进行concatenate作为最终的alignment representation。
Inter-Attention Alignment Layer
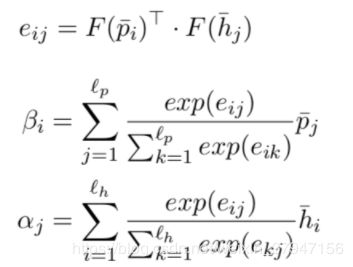
首先介绍inter-attention alignment layer,在之前的论文中,该attention已经被大量的应用。该attention主要计算两个文本词之间权重特征,通过另一个文本词向量加权来表示当前文本。
Intra-Attention Alignment Layer
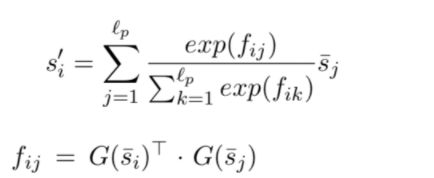
intra-attention又叫self-attention,计算词与当前句子的相似度,捕获了序列、全局的特征信息。
Alignment Factorization Layer
从之前的论文分析,feature compare常用的方式为subtract、multiply、concatenate。本文仍然采用这三种方式,但是会对compare函数处理之后的结果进行因子分解运算。
Factorization Operation
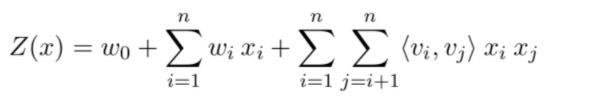
我们知道对于低秩矩阵,因子分解运算能够自动交叉二维特征。本文采用因子分解运算针对compare函数的结果抽取更高级的特征。

算法最后通过一个2层的highway network进行特征投影,然后经过一层线性层抽取用于classification的representation。
DIIN
Introduction
Natural Language Inference任务介绍
NLI又叫做recognizing textual entailment. 是用来确定两句话是不是蕴含关系.
第一句话作为premise, 第二句话作为hypothesis, 则两句话的三种关系定义如下:
- entailment(如果premise为真, 则hypothesis也必须为真)
- contradiction(如果premise为真, 则hypothesis必须为假)
- neutral(既不是entailment, 也不是contradiction)
Model
Interactive Inference Network(IIN)
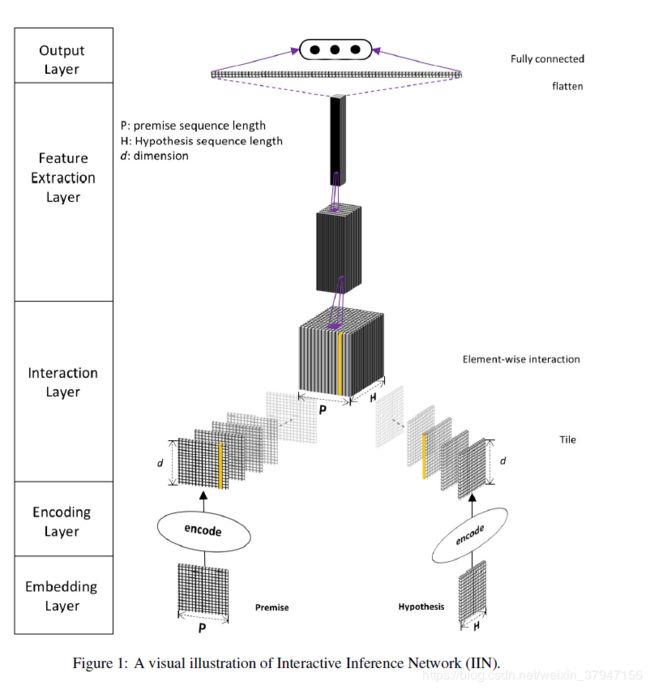
先介绍下基础的IIN
模型主要包括五部分, 每部分都可以用不同的方式实现.
1、Embedding Layer: 将词或者短语转换为向量表示, 并构造句子的矩阵表示.
可以直接使用预训练的词向量, 比如word2vec, glove等等.
为了提高效果, 还可以利用词性标注, 命名实体识别等方法获取更多词汇和句法信息.
2、Encoding Layer: 对Embedding Layer的输出进行编码, 这部分可以选择不同的编码器, 比如BiLSTM, self-attention等等. 不同的编码器可以结合使用来获得更好的句表示.
3、Interaction Layer: 生成premise和hypothesis之间的interaction tensor.
Interaction有多种不同的建模方式, 比如计算余弦距离, 点积等等.
4、Feature Extraction Layer: 解析从Interaction layer获取的语义特征. 这部分作者使用的2-D的CNN
5、Output Layer
Densely Interactive Inference Network(DIIN)
进入正题, 介绍DIIN. DIIN的基础结构和IIN是一样的.
Embedding Layer
Embedding部分, 作者使用了word embedding, character feature和syntactical features进行拼接.
word embedding直接用的预训练的GloVe, 注意, 作者在训练时会对词向量进行更新.
character feature是通过一维的卷积来实现的, 卷积后进行max-pooling. 作者指出, character feature有助于解决OOV问题. CNN在premise和hypothesis之间共享权重.
Syntactical feature包含词性标注的one-hot向量和 binary exact match feature.
Encoding Layer
将上层得到的premise表示P和hypothesis表示H先通过一个两层的highway network得到Pˆ 和Hˆ 作为新的表示.
然后, 通过self-attention layer获取词序和上下文信息. self-attention过程如下: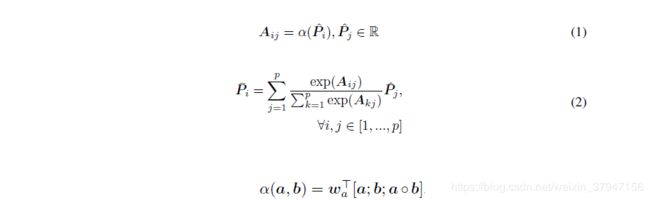
之后,将Pˆ和Pˉ拼接并送入fuse date.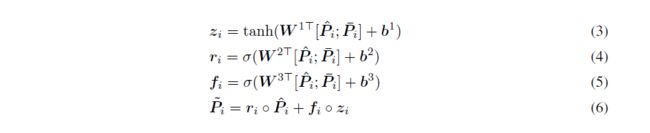
用同样的方法得到H˜
Interaction Layer
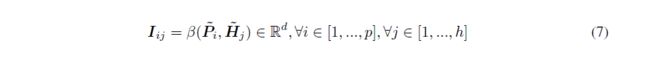


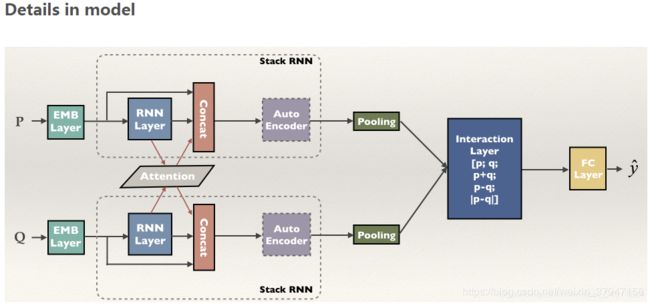
DRCN
Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
这篇论文的创新点在于:
1、采用了固定的glove embedding和可变的glove embedding拼接并提升了模型效果。
2、采用stack层级结构的LSTM,在层级结构上加入了DenseNet的思想,将上一层的参数拼接到下一层,一定程度上在长距离的模型中保留了前面的特征信息。
3、由于不断的拼接导致参数增多,用autoencoder进行降维,并起到了正则化效果,提升了模型准确率。



Conclusion
这篇文章主要集中在句子匹配任务上
- 借鉴ResNet和DenseNet,运用到stack RNN中;
- 将注意力权值作为一个特征并在h, x的中间,做法很新颖;
- 利用AutoEncoder来压缩向量,减少参数迅速增加的压力。
CSRAN
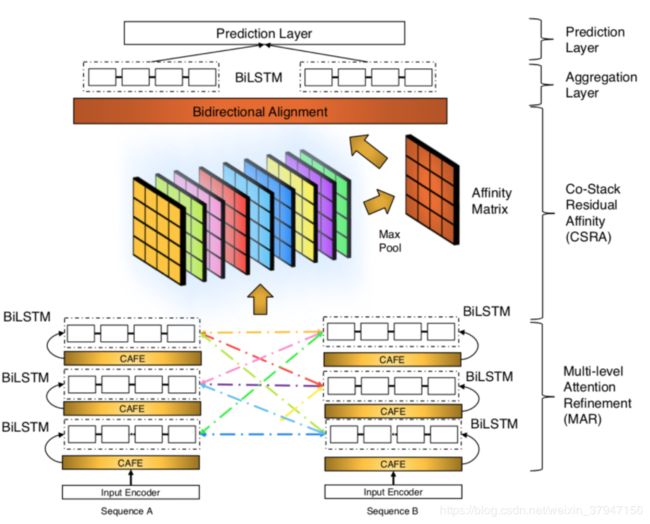
本文介绍论文《Co-Stack Residual Affinity Networks with Multi-level Attention Refinement for Matching Text Sequences》的相关工作,本文是CAFE算法的扩展版,CAFE算法只计算了one-layer,而本文作者则计算了multi-layer。事实上简单的stacked layer并不会带来太大效果的提升,甚至可能导致效果变差,为了训练深层次的网络,常用的三种网络结构为highway net、residual net、dense net。本文参考三种网络的设计方式,设计了一个网络更深的CAFE。但是本人在复现论文效果的时候发现参考论文的方式,一直达不到论文的效果,因此对论文中的模型结构稍作修改,将stacked-LSTM去掉,然后直接用highway做多层的CAFE投影,发现效果还不错。
Input Encoder
首先将word representation和character representation进行拼接,然后经过2层的highway network进行特征非线性投影。
Multi-level Attention Refinement
这里就比较简单了,直接讲上面讲到的CAFE作为block,参考类似于residual network的方式,输出为input + 6。6为CAFE中抽取的特征:inter-attention有3维,intra-attention有3维。


参考文献
- Natural Language Inference by Tree-Based Convolution and Heuristic Matching
- A Structured Self-Attentive Sentence Embedding
- A Decomposable Attention Model for Natural Language Inference
- Enhanced LSTM for Natural Language Inference
- Neural Natural Language Inference Models Enhanced with External Knowledge
- Discourse Marker Augmented Network with Reinforcement Learning for Natural Language Inference
- https://hsiaoyetgun.github.io/2018/08/06/Natural-Language-Inference-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/#KIM-amp-DMAN