[生成对抗网络GAN入门指南](9)ACGAN: Conditional Image Synthesis with Auxiliary Classifier GANs
本篇blog的内容基于原始论文ACGAN:Conditional Image Synthesis with Auxiliary Classifier GANs和《生成对抗网络入门指南》第六章。 完整代码见文章末尾
一、为什么要研究ACGAN?
使用标签的数据集应用于生成对抗网络可以增强现有的生成模型,并形成两种优化思路。
1. cGAN使用了辅助的标签信息来增强原始GAN,对生成器和判别器都使用标签数据进行训练,从而实现模型具备产生特定条件数据的能力。
[生成对抗网络GAN入门指南](7)cGAN: Conditional Generative Adversarial Nets
2. SGAN的结构来利用辅助标签信息(少量标签),利用判别器或者分类器的末端重建标签信息。
[生成对抗网络GAN入门指南](8)SGAN:Semi-Supervised Learning with Generative Adversarial Networks
ACGAN则是结合以上两种思路对GAN进行优化。
二、ACGAN目标函数
-
对于生成器来说有两个输入,一个是标签的分类数据c,另一个是随机数据z,得到生成数据为
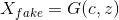 ;
; -
对于判别器分别要判断数据源是否为真实数据的概率分布
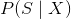 ,以及数据源对于分类标签的概率分布
,以及数据源对于分类标签的概率分布 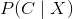
ACGAN的目标函数包含两部分:
第一部分 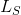 是面向数据真实与否的代价函数
是面向数据真实与否的代价函数
第二部分 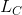 则是数据分类准确性的代价函数。
则是数据分类准确性的代价函数。
ACGAN: Conditional Image Synthesis with Auxiliary Classifier GANs_第1张图片](http://img.e-com-net.com/image/info8/aef7ab289c114c0a81d48c7bf2c2c77f.jpg)
-
在优化过程中希望判别器D能否使得
+ 尽可能最大,而生成器G使得 - 尽可能最大; -
简而言之是希望判别器能够尽可能区分真实数据和生成数据并且能有效对数据进行分类,对生成器来说希望生成数据被尽可能认为是真实数据且数据都能够被有效分类。
三、ACGAN结构
如下图中,我们很清楚地能看到 ACGAN = cGAN+SGAN
ACGAN: Conditional Image Synthesis with Auxiliary Classifier GANs_第2张图片](http://img.e-com-net.com/image/info8/2afda103efcd4330a168b63e42abe568.jpg)
四、代码
1. 导入包及初始化超参数
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply
from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
class ACGAN():
def __init__(self):
# Input shape
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.num_classes = 10
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
losses = ['binary_crossentropy', 'sparse_categorical_crossentropy']
2. 编译生成器和优化器
-
这里设置判别器为不可训练模式,仅优化生成器的参数
-
在生成器和判别器加入标签信息
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=losses,
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# The generator takes noise and the target label as input
# and generates the corresponding digit of that label
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,))
img = self.generator([noise, label])
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated image as input and determines validity
# and the label of that image
valid, target_label = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model([noise, label], [valid, target_label])
self.combined.compile(loss=losses,
optimizer=optimizer)
3. 构造生成器和判别器(均加入标签信息)
①生成器
def build_generator(self):
model = Sequential()
model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
model.add(Reshape((7, 7, 128)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(self.channels, kernel_size=3, padding='same'))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, 100)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)②判别器
def build_discriminator(self):
model = Sequential()
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.summary()
img = Input(shape=self.img_shape)
# Extract feature representation
features = model(img)
# Determine validity and label of the image
validity = Dense(1, activation="sigmoid")(features)
label = Dense(self.num_classes+1, activation="softmax")(features)
return Model(img, [validity, label])
4. 训练
def train(self, epochs, batch_size=128, sample_interval=50):
# Load the dataset
(X_train, y_train), (_, _) = mnist.load_data()
# Configure inputs
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
y_train = y_train.reshape(-1, 1)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# Sample noise as generator input
noise = np.random.normal(0, 1, (batch_size, 100))
# The labels of the digits that the generator tries to create an
# image representation of
sampled_labels = np.random.randint(0, 10, (batch_size, 1))
# Generate a half batch of new images
gen_imgs = self.generator.predict([noise, sampled_labels])
# Image labels. 0-9 if image is valid or 10 if it is generated (fake)
img_labels = y_train[idx]
fake_labels = 10 * np.ones(img_labels.shape)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, [valid, img_labels])
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, fake_labels])
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
# Train the generator
g_loss = self.combined.train_on_batch([noise, sampled_labels], [valid, sampled_labels])
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[3], 100*d_loss[4], g_loss[0]))
# If at save interval => save generated image samples
if epoch % sample_interval == 0:
self.save_model()
self.sample_images(epoch)
5. 可视化及保存模型
def sample_images(self, epoch):
r, c = 10, 10
noise = np.random.normal(0, 1, (r * c, 100))
sampled_labels = np.array([num for _ in range(r) for num in range(c)])
gen_imgs = self.generator.predict([noise, sampled_labels])
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt,:,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
def save_model(self):
def save(model, model_name):
model_path = "saved_model/%s.json" % model_name
weights_path = "saved_model/%s_weights.hdf5" % model_name
options = {"file_arch": model_path,
"file_weight": weights_path}
json_string = model.to_json()
open(options['file_arch'], 'w').write(json_string)
model.save_weights(options['file_weight'])
save(self.generator, "generator")
save(self.discriminator, "discriminator")
6. 运行
if __name__ == '__main__':
acgan = ACGAN()
acgan.train(epochs=14000, batch_size=32, sample_interval=200)
7. 运行结果
ACGAN: Conditional Image Synthesis with Auxiliary Classifier GANs_第3张图片](http://img.e-com-net.com/image/info8/30e4f59301214877bf2a2f94f52ce222.jpg)
ACGAN: Conditional Image Synthesis with Auxiliary Classifier GANs_第4张图片](http://img.e-com-net.com/image/info8/750d377f13b6415898528f694ed80438.jpg)
ACGAN: Conditional Image Synthesis with Auxiliary Classifier GANs_第5张图片](http://img.e-com-net.com/image/info8/ff233a5be2814514a299ab3c48833c5c.jpg)
ACGAN: Conditional Image Synthesis with Auxiliary Classifier GANs_第6张图片](http://img.e-com-net.com/image/info8/f3fbd59227014e6cb32e501805c8264d.jpg)
13999 [D loss: 1.554788, acc.: 48.44%, op_acc: 45.31%] [G loss: 1.450172]
完整代码
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply
from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
class ACGAN():
def __init__(self):
# Input shape
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.num_classes = 10
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
losses = ['binary_crossentropy', 'sparse_categorical_crossentropy']
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=losses,
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# The generator takes noise and the target label as input
# and generates the corresponding digit of that label
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,))
img = self.generator([noise, label])
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated image as input and determines validity
# and the label of that image
valid, target_label = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model([noise, label], [valid, target_label])
self.combined.compile(loss=losses,
optimizer=optimizer)
def build_generator(self):
model = Sequential()
model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
model.add(Reshape((7, 7, 128)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(self.channels, kernel_size=3, padding='same'))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, 100)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)
def build_discriminator(self):
model = Sequential()
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.summary()
img = Input(shape=self.img_shape)
# Extract feature representation
features = model(img)
# Determine validity and label of the image
validity = Dense(1, activation="sigmoid")(features)
label = Dense(self.num_classes+1, activation="softmax")(features)
return Model(img, [validity, label])
def train(self, epochs, batch_size=128, sample_interval=50):
# Load the dataset
(X_train, y_train), (_, _) = mnist.load_data()
# Configure inputs
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
y_train = y_train.reshape(-1, 1)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# Sample noise as generator input
noise = np.random.normal(0, 1, (batch_size, 100))
# The labels of the digits that the generator tries to create an
# image representation of
sampled_labels = np.random.randint(0, 10, (batch_size, 1))
# Generate a half batch of new images
gen_imgs = self.generator.predict([noise, sampled_labels])
# Image labels. 0-9 if image is valid or 10 if it is generated (fake)
img_labels = y_train[idx]
fake_labels = 10 * np.ones(img_labels.shape)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, [valid, img_labels])
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, fake_labels])
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
# Train the generator
g_loss = self.combined.train_on_batch([noise, sampled_labels], [valid, sampled_labels])
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[3], 100*d_loss[4], g_loss[0]))
# If at save interval => save generated image samples
if epoch % sample_interval == 0:
self.save_model()
self.sample_images(epoch)
def sample_images(self, epoch):
r, c = 10, 10
noise = np.random.normal(0, 1, (r * c, 100))
sampled_labels = np.array([num for _ in range(r) for num in range(c)])
gen_imgs = self.generator.predict([noise, sampled_labels])
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt,:,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
def save_model(self):
def save(model, model_name):
model_path = "saved_model/%s.json" % model_name
weights_path = "saved_model/%s_weights.hdf5" % model_name
options = {"file_arch": model_path,
"file_weight": weights_path}
json_string = model.to_json()
open(options['file_arch'], 'w').write(json_string)
model.save_weights(options['file_weight'])
save(self.generator, "generator")
save(self.discriminator, "discriminator")
if __name__ == '__main__':
acgan = ACGAN()
acgan.train(epochs=14000, batch_size=32, sample_interval=200)