(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders
计划完成深度学习入门的126篇论文第二十一篇,DeepMind的Alex Graves等领导研究一种新的生成Image模型。
ABSTRACT&INTRODUCTION
摘要
本工作探索了基于PixelCNN结构的条件图像生成新图像密度模型。该模型可以以任何向量为条件,包括描述性标签或标记,或由其他网络创建的潜在嵌入。当以ImageNet数据库中的类标签为条件时,该模型能够生成代表不同动物、对象、景观和结构的不同的、现实的场景。当以卷积网络生成的嵌入为条件,给定一张看不见的人脸的单一图像时,它会生成同一个人的各种新肖像,这些肖像具有不同的面部表情、姿势和光照条件。我们还证明了Conditional PixelCNN 可以作为一个强大的解码器在图像自动编码器。此外,该模型中的Gated卷积层提高了PixelCNN的log-likelihood,匹配了PixelRNN在ImageNet上的最新性能,大大降低了计算成本。
介绍
神经网络在图像建模方面的最新进展[30、26、20、10、9、28、6]使得生成捕捉训练数据高层结构的多种自然图像成为可能。尽管这样无条件的模型本身很吸引人,许多图像建模的实际应用需要的模型先验信息;例如,一个图像模型用于强化学习规划在视觉环境中需要预测未来场景给特定的状态和操作[17]。类似地,图像处理任务,如去噪、去模糊、inpainting、超分辨率和着色,都依赖于在有噪声或不完整数据的条件下生成改进的图像。神经艺术品[18,5]和内容生成代表了条件生成的潜在未来用途。
本文通过对PixelRNN结构[30]卷积变体的改进和改进,探讨了条件图像建模的潜力。除了提供优秀的样本,该网络还具有返回显式概率密度的优势(不同于生成对抗性网络等替代方法[6,3,19]),使其易于应用于压缩[32]和概率规划和探索[2]等领域。该体系结构的基本思想是使用自回归连接对图像逐像素建模,将联合图像分布分解为条件的乘积。本文提出了两种变体:PixelRNN和PixelCNN,前者采用二维LSTM对像素分布进行建模[7,26],后者采用卷积网络对像素分布进行建模。pixelnns通常具有更好的性能,但是PixelCNNs训练速度更快,因为卷积天生就更容易并行化;考虑到在大型图像数据集中存在大量像素,这是一个重要的优势。我们的目标是通过引入Gated PixelCNN(GatedPixelCNN)的一个变种,结合了这两种模型的优点,它匹配了CIFAR和ImageNet上PixelRNN的log-likelihood,同时需要不到一半的训练时间。
我们还介绍了Gated PixelCNN(Conditional PixelCNN)的条件变体,它允许我们对给定潜在向量嵌入的自然图像的复杂条件分布建模。我们展示了一个条件PixelCNN模型可以用来从不同的类生成图像,比如狗,割草机和珊瑚礁,通过简单地调整一个类的一个热编码。类似地,可以使用嵌入来捕获图像的高级信息,从而生成具有类似特性的大量图像。这让我们深入了解了嵌入中编码的不变性,例如,我们可以基于单个图像生成同一个人的不同姿势。同样的框架也可以用来分析和解释深层神经网络中的不同层次和活动。
2 Gated PixelCNN
PixelCNNs(和PixelRNNs)[30]将图像x上的像素联合分布建模为条件分布的乘积,其中![]() 是单个像素:
是单个像素:

像素依赖关系的顺序是光栅扫描顺序:逐行扫描,每行逐像素扫描。因此,每个像素都依赖于上面和左边的所有像素,而不是任何其他像素。图1(左)显示了像素的dependency字段。
![(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders_第1张图片](http://img.e-com-net.com/image/info8/6ee55d1908d649b2b7d30c2acbe68a24.jpg)
NADE[14]和RIDE[26]等其他自回归模型也使用了类似的设置。区别在于条件分布![]() 。在PixelCNN中,每个条件分布都由卷积神经网络建模。为了保证CNN只能使用当前像素上方和左侧像素的信息,卷积的滤波器被屏蔽,如图1(中间)所示。对于每个像素,依次对三个颜色通道(R, G, B)建模,B以(R, G)为条件,G以R为条件。这是通过将网络每一层的feature map分割成三个,并调整掩模张量的中心值来实现的。然后使用softmax对每个颜色通道的256个可能值进行建模。
。在PixelCNN中,每个条件分布都由卷积神经网络建模。为了保证CNN只能使用当前像素上方和左侧像素的信息,卷积的滤波器被屏蔽,如图1(中间)所示。对于每个像素,依次对三个颜色通道(R, G, B)建模,B以(R, G)为条件,G以R为条件。这是通过将网络每一层的feature map分割成三个,并调整掩模张量的中心值来实现的。然后使用softmax对每个颜色通道的256个可能值进行建模。
PixelCNN通常由一堆带掩码的卷积层组成,这些层以N x N x 3张图像作为输入,生成N x N x 3 x 256个预测作为输出。卷积的使用使得所有像素的预测可以在训练过程中并行进行(公式1中的所有条件分布)。在采样过程中,预测是顺序的:每次预测一个像素,它都会被反馈到网络中,以预测下一个像素。这种序列性对于生成高质量的图像至关重要,因为它允许每个像素以高度非线性和多模态的方式依赖于之前的像素。
2.1 Gated Convolutional Layers
PixelRNNs使用空间LSTM层而不是卷积堆栈,此前已经被证明作为生成模型[30]优于PixelCNNs。这种优势的一个可能原因是,LSTM中的循环连接允许网络中的每一层访问之前像素的整个邻域,而pixelCNN可用邻域的区域随着卷积堆栈的深度线性增长。然而,使用足够多的层可以在很大程度上缓解这个缺点。另一个潜在的优势是pixelRNNs包含乘法单元(以LSTM门的形式),这可能有助于它建模更复杂的交互。为了修正这一点,我们用以下门控激活单元替换了原始pixelCNN中掩码卷积之间经过校正的线性单元:
![]()
其中σ是sigmoid非线性k层的数量,是element-wise乘积和卷积算子。我们将得到的模型称为Gated PixelCNN。在以往的工作中,已经探索了带门的前馈神经网络,如highway networks[25]、grid LSTM[13]和neural gpu[12],并普遍证明对性能有益。
2.2 Blind spot in the receptive field
在图1(右上角)中,我们显示了在输入图像上一个33掩蔽滤波器的有效接受域的渐进增长。注意,掩蔽卷积体系结构忽略了输入图像的很大一部分。这个盲点可以覆盖多达四分之一的潜在接受域(例如,当使用3x3过滤器时),这意味着不考虑当前像素右侧的任何内容。
在这项工作中,我们通过组合两个卷积网络堆栈来消除盲点:一个对当前行的条件(水平堆栈)和一个对所有行以上的条件(垂直堆栈)。这种安排如图1(右下角)所示。垂直堆栈没有任何掩蔽,允许接受域以矩形方式增长,没有任何盲点,我们在每一层之后合并两个堆栈的输出。水平堆栈中的每一层都将上一层和垂直堆栈的输出作为输入。如果我们将水平堆栈的输出连接到垂直堆栈,它将能够使用当前像素下方或右侧的像素信息,这将打破条件分布。
![(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders_第2张图片](http://img.e-com-net.com/image/info8/93c1f349cd3e43b7a0bc25be24bef266.jpg)
图2显示了一个Gated PixelCNN的单层块。我们将Wf和Wg结合在一个(屏蔽)卷积中,以提高并行性。在[30]中,我们还使用了水平堆栈中的剩余连接[11]。我们已经尝试在垂直叠加中添加一个剩余连接,但是在最终的模型中忽略了它,因为它并没有改善我们最初的实验结果。注意,图2中的(n x 1)和(n x n)掩码卷积也可以由![]() 卷积实现,然后通过填充和裁剪在像素上移动。
卷积实现,然后通过填充和裁剪在像素上移动。
2.3 Conditional PixelCNN
给出了一种用潜在向量h表示的高阶图像描述,我们试图对符合这种描述的图像的条件分布![]() 进行建模。Conditional PixelCNN对以下分布进行了正式建模:
进行建模。Conditional PixelCNN对以下分布进行了正式建模:
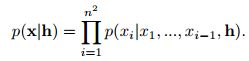
我们通过将依赖于h的项添加到方程2中的非线性项之前来对条件分布建模:
![]()
其中k是层数。如果h是一个指定类的one-hot,这等价于在每一层添加一个类相关偏差。注意,条件作用并不依赖于图像中像素的位置;这是适当的,只要h只包含关于图像中应该是什么而不是在哪里的信息。例如,我们可以指定某个动物或对象应该出现,但是可以在不同的位置和姿势以及不同的背景下出现。我们还开发了一个变量,其中条件作用是位置相关的。这可能是有用的应用程序,我们有特定的位置信息结构映射的图像嵌入在h。h空间表示![]() (图像的宽度和高度,但可能有任意数量的特征图)与deconvolutional神经网络m(),我们获得一个位置依赖偏差如下:
(图像的宽度和高度,但可能有任意数量的特征图)与deconvolutional神经网络m(),我们获得一个位置依赖偏差如下:
![]()
![]() 是一个没有被masked的1x1卷积。
是一个没有被masked的1x1卷积。
2.4 PixelCNN Auto-Encoders
由于条件像素神经网络具有对不同的多模态图像分布![]() 进行建模的能力,因此可以将其作为图像解码器应用于现有的神经结构中,如自动编码器。自动编码器由两部分组成:接收输入图像x并将其映射到(通常)低维表示的h的编码器,以及试图重构原始图像的解码器。
进行建模的能力,因此可以将其作为图像解码器应用于现有的神经结构中,如自动编码器。自动编码器由两部分组成:接收输入图像x并将其映射到(通常)低维表示的h的编码器,以及试图重构原始图像的解码器。
从传统的卷积自编码结构[16]开始,我们用Conditional PixelCNN替换去卷积解码器,训练完整的端到端的网络。由于PixelCNN已被证明是一个强大的无条件生成模型,我们希望这一变化能改善重建。也许更有趣的是,我们还期望它改变表示,编码器将学习从数据提取:从如此多的低水平像素统计数据可以由PixelCNN,编码器可以省略这些从h和精力集中于更高级的抽象信息。
3 Experiments
3.1 Unconditional Modeling with Gated PixelCNN
表1将Gated PixelCNN与CIFAR-10数据集上发布的结果进行了比较。这些体系结构都是为可能的最佳验证分数而优化的,这意味着得到较低4分的模型实际上泛化得更好。Gated PixelCNN的性能比PixelCNN好0.11位/dim,这对生成的样本的视觉质量影响非常显著,接近PixelRNN的性能。
![(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders_第3张图片](http://img.e-com-net.com/image/info8/d1063ef165ee48329796e321bc5703e5.jpg)
在表2中,我们比较了Gated PixelCNN与ImageNet数据集中的其他模型的性能。这里Gated PixelCNN优于PixelRNN;我们认为这是因为模型的拟合不足,较大的模型表现得更好,更简单的PixelCNN模型缩放得更好。我们能够在不到一半的训练时间(使用32个gpu, 60小时)内实现与PixelRNN(行LSTM[30])类似的性能。对于表2中的结果,我们训练了一个更大的模型,有20层(图2),每层有384个隐藏单元,过滤器大小为55。在TensorFlow[1]中,我们使用了32个gpu上的200K同步更新,使用的总批大小为128。
![(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders_第4张图片](http://img.e-com-net.com/image/info8/0bf6b948c7d7466185270cb9ae03d13e.jpg)
3.2 Conditioning on ImageNet Classes
在我们的第二个实验中,我们探索了使用Conditional PixelCNNs对ImageNet图像进行类条件建模。给定第i个类的一个one-hot hi,我们对![]() 进行建模。模型接收的信息量仅为
进行建模。模型接收的信息量仅为![]() 位/像素(对于32x32图像)。尽管如此,我们仍然可以预期,在类标签上调整图像生成可以显著提高log-likelihood结果,但是我们没有观察到很大的差异。另一方面,正如在[27]中所指出的,我们发现生成的样本的视觉质量有了很大的改善。
位/像素(对于32x32图像)。尽管如此,我们仍然可以预期,在类标签上调整图像生成可以显著提高log-likelihood结果,但是我们没有观察到很大的差异。另一方面,正如在[27]中所指出的,我们发现生成的样本的视觉质量有了很大的改善。
![(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders_第5张图片](http://img.e-com-net.com/image/info8/66390cd5f3114ceab391ad7d8438e246.jpg)
在图3中,我们展示了来自8个不同类的单个类条件模型的示例。我们看到生成的类彼此非常不同,并且相应的对象、动物和背景被清晰地生成。此外,单个类的图像非常多样化:例如,模型能够从不同的角度和闪电条件生成相似的场景。令人鼓舞的是,在给定每个动物或对象的大约1000幅图像的情况下,该模型能够泛化并生成新的效果图。
3.3 Conditioning on Portrait Embeddings
在我们的下一个实验中,我们从卷积网络的顶层提取潜在的表示,该网络训练在一个使用人脸检测器从Flickr图像自动裁剪的大型肖像数据库上。照片的质量参差不齐,因为很多照片都是在恶劣的闪电条件下用手机拍摄的。
该网络使用三重损失函数[23]进行训练,该函数确保为特定人的图像x生成的嵌入h比为其他所有人的图像生成的嵌入h更接近于对同一个人的所有其他图像的嵌入。
训练监督网络后,取(image=x, embedded =h)元组,训练Conditional PixelCNN对p(xjh)进行建模。给定一个不在训练集中的人的新图像,我们可以计算h = f(x)并生成同一个人的新图像。
![(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders_第6张图片](http://img.e-com-net.com/image/info8/364c61241af34213bc36a3e89ef67faa.jpg)
模型中的示例如图4所示。我们可以看到嵌入捕获了源图像的许多面部特征,生成模型能够在新的姿势、光照条件等条件下生成具有这些特征的大量新面孔。
![(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders_第7张图片](http://img.e-com-net.com/image/info8/ab4c09bc207542c3a4f12a0bbc0fcf4b.jpg)
最后,我们以图像对嵌入之间的线性插值为条件进行重构实验。结果如图5所示。每行图像在采样时都使用相同的随机种子,从而实现平滑的过渡。最左边和最右边的图像用于生成插值的端点。
3.4 PixelCNN Auto Encoder
本实验探索了将编码器和解码器(PixelCNN)端到端训练成自动编码器的可能性。我们在32x32的ImageNet补丁上训练了PixelCNN自动编码器,并将结果与经过优化MSE训练的卷积自动编码器的结果进行了比较。两个模型都使用了10或100维的瓶颈。
![(22)[NIPS16] PixelCNN:Conditional Image Generation with PixelCNN Decoders_第8张图片](http://img.e-com-net.com/image/info8/756d3c1576a449eba313acec6d0bd18b.jpg)
图6显示了这两个模型的重构。对于PixelCNN,我们采样多个条件重构。这些图像支持我们在第2.4节中的预测,瓶颈表示h中编码的信息在PixelCNN解码器中与更传统的解码器在质量上有所不同。例如,在最下面一行,我们可以看到模型生成了与人不同但看起来相似的室内场景,而不是试图准确地重建输入。
4 Conclusion
这项工作引入了Gated PixelCNN,这是对原始PixelCNN的改进,它能够匹配或优于PixelRNN[30],并且计算效率更高。在我们的新架构中,我们使用两组cnn来处理接受域中的盲点,这限制了原始PixelCNN。此外,我们使用了一个门控机制,提高了性能和收敛速度。我们已经展示了该架构在CIFAR-10上获得了与PixelRNN类似的性能,现在在ImageNet 32x32和64x64数据集上是最先进的。
此外,使用Conditional PixelCNN,我们探索了三种不同设置下的自然图像的条件建模。在类条件生成中,我们证明了单个模型能够生成与不同类相对应的各种逼真的图像。在人体画像上,该模型能够从同一个人在不同姿势和闪电条件下的单一图像生成新的图像。最后,我们证明PixelCNN可以作为一个强大的图像解码器在自动编码器中使用。除了在所有这些数据集中实现最先进的日志似然评分外,从我们的模型生成的样本具有非常高的视觉质量,表明该模型捕获了对象和光照条件的自然变化。
在未来,尝试仅从一个示例图像生成特定动物或对象的新图像可能会很有趣[21,22]。另一个令人兴奋的方向是将Conditional PixelCNNs与变分推理结合起来,创建一个变分自动编码器。在现有的工作中,![]() 通常采用具有对角协方差的高斯模型,而使用PixelCNN可以改进VAEs中的解码器。这项工作的另一个有前途的方向是根据图像标题而不是类标签来建模图像,Mansimov et提出了这一观点。由于作者提出的准直模型往往输出模糊的样本,我们认为类似Conditional PixelCNN的方法可以大大改善这些样本。
通常采用具有对角协方差的高斯模型,而使用PixelCNN可以改进VAEs中的解码器。这项工作的另一个有前途的方向是根据图像标题而不是类标签来建模图像,Mansimov et提出了这一观点。由于作者提出的准直模型往往输出模糊的样本,我们认为类似Conditional PixelCNN的方法可以大大改善这些样本。