联邦学习框架FATE使用案例记录
联邦学习框架FATE使用案例记录
- 1 横向联邦学习案例
- 实验设置
- 文件说明
- 实验步骤
- 2 纵向联邦学习案例
- 实验设置
- 实验步骤
- 实验结果
- 结果分析
- 小结
- 3 使用感受
本文记录了FATE框架中横向和纵向联邦学习的案例使用,并与笔者近期使用过的谷歌TFF(TensorFlow-Federated)框架对比,阐述使用感受。
1 横向联邦学习案例
在本节中,以逻辑回归为例记录横向联邦学习案例使用。
实验设置
数据集:信用数据,位置FATE/examples/data/default_credit_homo_guest/host.csv
算法:logistics regression
文件说明
1.上传数据json文件
upload_my_homolr_guest.json,upload_my_homolr_host.json
其中file字段用于指定数据存储位置;
head字段指明数据是否包含头;
partition字段指定数据划分数;
work_mode字段表示工作模式(单节点/集群);
namespace和table_name由用户指定,需要与运行时配置文件中相应字段对应。
2.组件
test_my_homolr_train_dsl.json
这里使用了DataIO、HomoLR和Evaluation三个组件,需要注意各个组件之间的输入输出数据关系;
要使用其他组件,可以参考官方文档中的说明。
3.运行时配置文件
test_my_homolr_train_conf.json
initiator设置了联邦发起者的角色和id;
job_parameters定义了工作模式(单机/集群);
role_parameters设置了各角色的具体信息,包括训练数据、数据输入输出格式等;
需要注意的是,此处训练数据的name和namespace需要与上传数据json文件中的响应属性对应;
最后,algorithm_parameters部分设置了本次训练使用的算法及对应参数、加密方法和交叉验证相关设置。
实验步骤
进入实验环境
进入框架所在文件夹:cd ${your_fate}
进入docker环境:docker exec -it fate_python bash
1.上传训练数据
python fate_flow/fate_flow_client.py -f upload
-c ${your_upload_json_path}/upload_my_homolr_guest.json
-c ${your_upload_json_path}/upload_my_homolr_host.json
【注】注意是先上传guest数据,后上传host数据
2.提交训练任务
python fate_flow/fate_flow_client.py -f submit_job
-d ${your_dsl_path}/test_my_homolr_train_dsl.json
-c ${your_runtime_conf_path}/test_my_homolr_train_conf.json
3.查看结果
点击提示url可以查看相关结果:
http://localhost:8080/index.html#/dashboard?job_id=20190929055530316952233&role=guest&party_id=10000
2 纵向联邦学习案例
在本节中,以secureboost为例记录纵向联邦学习案例使用。
实验设置
数据集:纵向切割的breast数据集,位置FATE/examples/data/breast_a/b.csv
算法:secureboost
实验步骤
实验步骤同样分为三步,上传数据、提交任务和查看结果,此处对结果进行展示:
实验结果
1.训练中
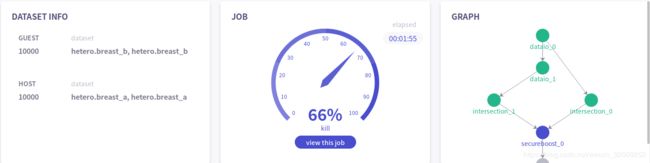
2.查看结果
点击view this job查看所有结果,同时可以通过切换job查看guest端和host端的数据和模型输出,此处只做部分展示: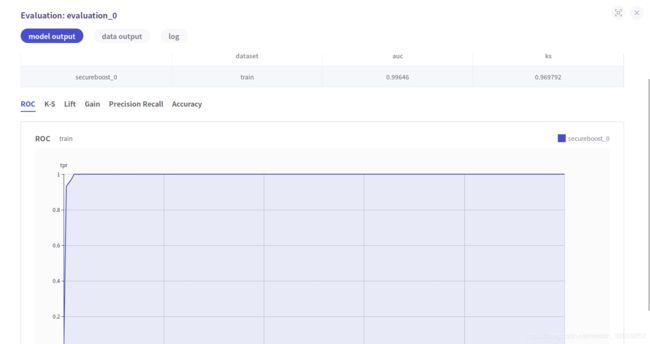
【注】此处结果为fate更新前的展示,目前fate已经更新到1.1版本,界面有所改变,如果点击view this job无效,可以尝试使用谷歌浏览器查看结果
结果分析
模型输出的各项指标都很好,结果非常令人满意,通过阅读过SecureBoost论文了解到这个算法是无损的,所以达到了如此高的指标;secureboost是由xgboost改进而来的,所以训练速度也很快。
小结
读者可以根据需求修改以上列举的文件进行不同训练。笔者记录以上案例时使用的是fate的早期版本,横向联邦学习支持的模块很少,目前fate框架已经支持深度学习,读者可以尝试使用。
3 使用感受
本节笔者将对比FATE框架和TFF框架的使用感受。
1.环境部署
fate框架需要较多软件,安装操作比较琐碎,安装过程中可能出一些小问题,但对软件版本对应要求不是很高,环境部署可以参考这里和官方GitHub。
TFF框架官方没有中文文档,安装过程中也会出各种各样的错误,支持conda安装;如果使用gpu,需要严格按照版本对应安装,笔者在此吃了不少苦头。
2.应用场景
fate框架支持横向、纵向联邦学习;而TFF仅支持横向联邦。
fate目前已经支持多种算法,TFF同样支持各种算法和深度学习。
3.上手难度
fate如果只是修改部分json文件,还可以接受,但是如果需要大片重置,在linux系统下不是很方便;但fate源码中已搭建好大部分组件结构,基本不需要编写代码,用户可以0基础训练并查看结果。
TFF编译器可以配置到IDE中,编写代码比较方便;但TFF有其federated core等编程范式和API,有一定上手难度,使用时需要编写大量代码。
4.可视化
fate在可视化部分做的比较好,轻松点击便可查看结果。
TFF需要自行编写代码从tf.Session中取出中间和最终结果。
5.调试
fate代码涉及多种语言,且代码封装性较高,笔者由于对python了解甚少,未曾尝试修改fate中的python代码,更未尝试debug。
TFF笔者使用较少,不过TFF计算时使用静态图并tf.Session保存中间结果,调试也比较困难。
6.GPU支持
据笔者目前了解fate暂时不支持GPU计算,在这一方面TFF更有优势。
7.使用场景
fate支持多方部署,同时可以由多方发起联邦计算,可以用于实验测试和真实环境部署。
TFF虽然是谷歌已经用于实际训练终端Gboard的框架,但据笔者至目前的使用并未发现开放给用户的多方联邦接口,仅适用于实验测试。