正则表达式入门
正则表达式入门
花了一点时间看了一下想看很久的正则
文章目录
- 正则表达式入门
- 正则神器
- 正则表达式是什么鬼东西?
- 正则表达式语法
- 元字符
- 普通字符
- 贪婪模式和非贪婪模式
- 限定字符
- 标准字符
- 中期产品经理需求
- 选择符和分组
- 预查
- 备考周产品经理需求
- 自定义字符集合
- 特殊字符
- 练习
- 电话号码的正则
- 身份证号码的正则
- 电子邮箱的正则
- IP地址的正则
- 后话
正则神器
首先来介绍一个神器,window下面有一款正则神器RegexBuddy
密码:fbs0
常用功能大概有:
- 可以选定特定编程语言的正则表达式(不同语言对正则表达式的支持稍有差异)
- 转换不同语言的正则(比如c#转成python3.4)
- 实时验证正则表达式
- 直接生成特定语言的调用正则代码
- 大量正则表达式实例
- 记住历史正则表达式

天命圈已经画出来了,自己探索一下吧. ALT+F1 可以看所有支持的语言(版本)
正则表达式是什么鬼东西?
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE),又称正规表示式、正規表示法、正規運算式、規則運算式、常規表示法,是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器裡,正則表达式通常被用来检索、替换那些符合某个模式的文本。 --wiki
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。 --某度
正则表达式语法
学习正则其实很简单,无非就是学习元字符和他们的相互关系
元字符
元字符包括五种字符:普通字符,标准字符,特殊字符,限定字符(又叫量词),定位字符(也叫边界字符)
因为特殊字符的用途很广泛,分组间也很独立,所以我会在介绍其它字符的同时一点点地讲讲特殊字符,到最后汇总一下便好了.
普通字符
包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号(包括汉字)
除了直接写之外,还可以用范围输入,比如
[a-z] [A-Z] [0-9]
比方说我们有这样一个正则(默认Regex后面的为正则)
regex=Hello World
就会有这样的匹配效果

根据例子来谈谈正则里面的一些规矩
贪婪模式和非贪婪模式
-
贪婪模式,就是在整个表达式匹配成功的前提下,尽可能多的匹配,也就是所谓的“贪婪”,通俗点讲,就是看到想要的,有多少就捡多少,除非再也没有想要的了。
-
非贪婪模式,就是在整个表达式匹配成功的前提下,尽可能少的匹配,也就是所谓的“非贪婪”,通俗点讲,就是找到一个想要的捡起来就行了,至于还有没有没捡的就不管了。
正则默认是__贪婪模式__ ,那怎么才能进入非贪婪模式呢?
但要是我想皮一下,一个字符我就想让他"贪婪"个3次,或者是就匹配几次以上,又或者是几次到几次,又要怎么实现了?
限定字符
这个时候就要介绍一下限定字符了,这又称特殊字符,又称限定符,又称量词,·······
万变不离其宗,先来看看他有哪些东西:
| 字符 | 含义 |
|---|---|
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次 |
| {n} | 匹配确定的 n 次 |
| {n,} | 至少匹配 n 次 |
| {n,m} | 最少匹配 n 次且最多匹配 m 次 |
以上n,m为非负整数,且n <= m.
这里的*和+都是贪婪模式,只有?是非贪婪模式,整体是否开启贪婪模式可以由编程决定.
- ? 问号表示某个模式出现0次或1次,等同于{0,1}。
- * 星号表示某个模式出现0次或多次,等同于{0,}。
- + 加号表示某个模式出现1次或多次,等同于{1,}。
?的定义要记一下,记一下,记一下.埋个蛋
至于为什么可以叫成量词呢?
标准字符
标准字符其实就是将普通字符分类,所以大多能被等效
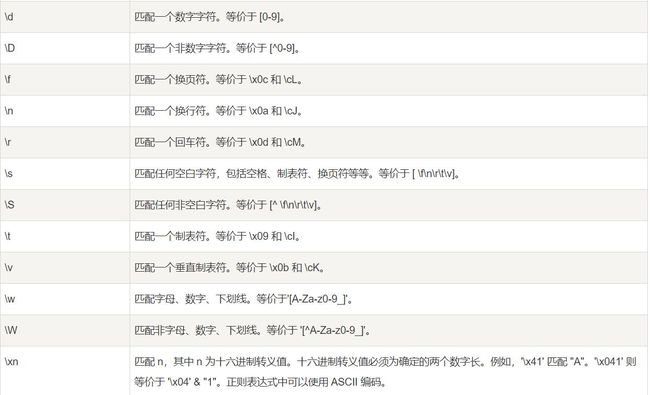
虽然很多,但是目前我们只要记住\d和\w就完事了.
可以看到正则表达式的第一个取反的操作:改成大写
可以看到标准字符里面有很多都是__一个__了吗?这就是量词(限定字符)发挥作用的时候了.
比如说匹配4位数字,我们可以这样写:
方法一:Regex = /d/d/d/d
方法二:Regex = /d{4}
方法三:Regex = /d/d{3}
注意方法三,并不是2乘3匹配6个,因为__量词只对前一个字符起作用__
中期产品经理需求
需求:检验6位中奖用户提交的6注6合彩是否正确 (以随机数个空格隔开)
分析:
- 虽说是6位用户,但是只要检验一个人的就可以了
- 每个数字有6位
- 有随机个空格
- 这里不考虑六合彩的规则
答案:Regex=^\d{6}\s*\d{6}\s*\d{6}\s*\d{6}\s*\d{6}\s*\d{6}

你可能会说:妈耶,你超纲了,’ ^ '是什么鬼?
这个需求很简单
怎么实现我不管
明天上线
还有,检验完之后不提取的吗?
###定位字符
注意!
定位字符是__零宽的__
毕竟他是用来标记,这里是开头,这里是结尾,这里是边界等这些信息的,标记匹配的不是字符而是符合某种条件的位置,所以定位字符是“零宽的”。
| 字符 | 含义 |
|---|---|
| ^ | 匹配开头 |
| $ | 匹配结尾 |
| \b | 匹配一个单词边界 |
\b的单词边界指的是:前面的字符和后面的字符不全是\w
比方说:
Regex = IPHONE\b
分析一下:因为 \b的左边是E,是一个\w字符,\b的单词边界指的是:前面的字符和后面的字符不全是\w,也就是说,只有在\b右边的字符不是\w的时候能被匹配,IPHONE1前面是E,后面是1,都是\w字符,所以不是单词边界.
选择符和分组
这里开始介绍括号了,稍稍有点难度罢了.复制一下别人家的东西:

regex=x|y,匹配字符x或y。( )表示捕获组,( )的作用如下:
-
括号中的表达式可以作为整体被修饰,用来表示匹配括号中表达式的次数,regex=(abc){2,3},可以匹配连续的2个或3个abc
-
括号中的表达式匹配到的内容会存储起来,并获取到括号中表达式匹配到的内容
划重点了,正则表达式所获取到的东西是括号中表达式匹配到的内容,由于正则存在着贪婪模式,所以返回的是一个array/list/group/map······
每一个括号按照左括号的顺序自动编号,也是程序返回的编号.不仅决定了程序返回的编号,同时也可以通过**反向引用(后向引用)**来将获取到的组在匹配一次.但是这对入门就不太友好了,可以参考参考资料.
(?:pattern)表示非捕获组,匹配括号中表达式匹配到的内容,但是不进行存储匹配到的内容。这在使用 “或” 字符?(|)?来组合一个正则的各个部分是很有用的。
例如:匹配字符“story”或者“stories”,regex=stor(?:y|ies)就是一个比 regex=story|stories更简略的表达式。
预查
又叫预搜索,又叫零宽断言,又叫环视,也是零宽的.相当于c语言里面的if()里面的(),也就是逻辑判别.
放个简单版的图:

字多一点的:

备考周产品经理需求
需求:通过一段英文探测男/女朋友爱不爱我 ,爱的话要求返回"want "
分析:
- 产品经理傻了
- 假设英文是"I want XX"
- 如果是"XX=you"的话表明爱
- 如果是"XX=else"的话表明渣男/女
- "XX=jingjing"除外
答案:Regex = want (?=you|jingjing)


自定义字符集合
方括号[ ]表示字符集合,即[ ]表示自定义集合,用[ ]可以匹配方括号里的任意一个字符。没有顺序没有顺序没有顺序
所以你可以这样写:
[1-9a-zA-z]
[A-z1-9a-z]
[a-zA-z1-9]都是同一个意思,识别__任意一个__字母或者数字
在自定义字符里面,只有小尖角"^",中折号"-"和标准字符外,其它特殊符号皆失去特殊意义!
特殊字符
可见参考资料
之前也介绍得7788了,这里就放张常用的图.特殊字符唯一一个和其它字符不一样的一点就是:他很特殊…

练习
电话号码的正则
电话号码由数字和“-”组成
- 如果包含区号,那么区号为三位或四位,首位是0
- 区号用“-”和其他数字分割
- 除了区号,电话号码为7到8位
- 手机号码为11位
- 11位手机号码的前2位为“13”,“14”,“15”,“17”,“18”
身份证号码的正则
- 长度:15位或者18位
- 如果是15位,则都是数字
- 如果是18位,最后一位可能为数字或字母X
电子邮箱的正则
- 邮箱格式:用户名@网址.域名
- 用户名:字母、数字、下划线组成
- 网址:字母、数字
- 域名:2-4位字母组成,1-2个域名
- 不区分大小写
IP地址的正则
IP地址的格式:(1255).(0255).(0255).(0255)
###日期格式的正则
日期格式:yyyy-mm-dd
这些题目摘自第二篇参考资料,可惜的是他的正则大部分是考虑不全面的…会另开一个正则例子来解答这些练习题和再补充一些常用正则
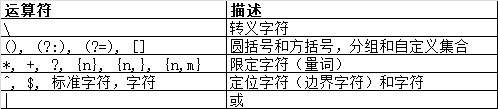
##正则表达式的运算优先级
昨天写的时候忘记写这个了,这里先放张图,后面再来填坑
优先级从高到低.
后话
- 正则表达式是个好东西,但是学会之后应用之前一定要查查自己熟悉的语言对正则表达式的支持到那种程度.不同语言的支持有时候差异还蛮大的
- 正则需要多练,多练,多练.
- 上面写的都是应用级的东西而已,如想仔细了解正则表达式,请看参考资料
如果你想请我吃个南五的话
参考资料:
参考资料有些的例子是错的,又或者是考虑不完全的,大家斟酌看看
正则表达式 - 语法
正则表达式从入门到实战_可能打不开…
【正则表达式系列】贪婪与非贪婪模式
正则基础之——贪婪与非贪婪模式
正则表达式小括号的多义性
正则表达式中括号的多义性
正则表达式及其常用特殊符号和字符
分组与后向引用
正则基础之——反向引用
正则表达式中的反向引用
最常用的详细正则表达式大全
不会的话就