编程题刷题笔记(包括leetcode和各种公司笔试题)
7/6:
做的查找中的word_ladder,没做出来。
学到了的知识点:
unordered_set:
定义为unordered_set
在集合中查找为dict.find(cur_front),找没找到用if (dict.find(cur_front) != dict.end())
queue:
定义为queue
插入为Q.push(start)
弹出为Q.pop()
判断是否为空为Q.empty()
查看长度为Q.size()
取值为Q.front()
在一个单词中替换单个字母为:
for (int i = 0; i < size; i++){
char ch = cur_front[i]; //对队列头字符串每一个字符进行替换
for (int j = 0; j < 26; j++){
cur_front[i] = 'a' + j;//替换字符
if (cur_front == end)return res+1;//找到答案,退出
if (dict.find(cur_front) != dict.end()){
Q.push(cur_front);//变换在字典中找到了
dict.erase(cur_front);//从字典中删除
}
}
cur_front[i] = ch;//还原队列头字符串,因为有可能在字典中可以找到多个“近邻字符串”
}7/8:
做的数组中的
| best-time-to-buy-and-sell-stock |
理解出现了问题,还是挺容易的
7/10:
做的数组中的
| best-time-to-buy-and-sell-stock2 |
一次过,没问题
还做了字符串中的add-binary
基本也是一遍过
学到的知识点如下:
栈的定义:stack< char > s;
相关操作:
s.empty(); //如果栈为空则返回true, 否则返回false;
s.size(); //返回栈中元素的个数
s.top(); //返回栈顶元素, 但不删除该元素
s.pop(); //弹出栈顶元素, 但不返回其值
s.push(); //将元素压入栈顶给字符串赋值的一种方法:string s4(10, 'a');
substr的用法:res = res.substr(1) //取res除了第一个字符的字符串
char和int交融:
char a= 'a';
int b ;
b=a;
count>>n; 结果是97
| best-time-to-buy-and-sell-stock |
| best-time-to-buy-and-sell-stock |
7-20:
鸽了10天。。很难受。。做了一道
| palindrome-number |
没做出来感觉是个数学问题,脑子没转过弯来
7-26:
第一次做了图这一类的问题。前两天才学完图相关的东西
题目是:clone-gragh
- BFS:广度优先便利需要借助队列queue
- map:一种类似于python中dict的容器
-
定义是这样的
mapmymap; 第一个是key 后一个是value
-
迭代器是这样的(包含初始化)
map::iterator iter = mymap.begin() -
插入数据是这样的
mymap.insert(make_pair(front, newNode));这里front是key,newNode是value
-
查找map中是否有这样一个key是这样的
if (mymap.find(front->neighbors[i]) == mymap.end())此举是判断find括号中的那东西是不是在map中
-
找到map中某个key或者value的内容是这样的
iter->first->neighbors[i] iter->second->neighbors.push_back(mymap[ori]);iter是map的迭代器,指向map中的某一对key和value,first是这个key,second是指这个value
-
- 在图中创建一个新的节点结构(其实也就是创建一个新对象的方法)
UndirectedGraphNode * newNode = new UndirectedGraphNode(front->label);new
7-29:
做了回溯中的
| permutation-sequence |
- 将int型转换成str型可以直接变:
vectorinit; for (int i = 1; i <= n; i++) { init.push_back(to_string(i)); } -
vector中删除一个元素是这样的
left.erase(left.begin() + 6);这里是删除left中第7个元素
8-1:
今天我真牛逼,打完球11点还在寝室做了一道题学了点知识。阔以
做的哈希里的two-sum
- 用了unordered_map,其查找较快
- 其定义和初始化如下
unordered_mapresult; for(int i=0; i 有点像python中的dict
-
有像python中的str一样的find函数的用法,如下
hashtable.find(diff) != hashtable.end()
- 其定义和初始化如下
8-3:
做了一道没什么意义的题,integer-to-roman
8-4:
做了
| populating-next-right-pointers-in-each-node |
挺简单的一道树的题被我想复杂了,鸭儿哟
8-6:
做了Maximum Subarray
没想到最简单的O(n)的解法,难受啊。
链接:https://www.nowcoder.com/questionTerminal/32139c198be041feb3bb2ea8bc4dbb01
来源:牛客网
public class Solution {
public int maxSubArray(int[] A) {
if(A.length == 0) return 0;
int sum = 0, max = A[0];
for(int i = 0; i < A.length; i++) {
sum += A[i];
if(max < sum) max = sum;
if(sum < 0) sum = 0;
}
return max;
}
}记录一下
8-7:
做了same-tree。。也没什么,就是没像别人一样用递归导致写的很累,但是锻炼了思维把大概就是
8-8:
做了
| unique-binary-search-trees |
又是一道类似于脑经急转弯的问题,没搞赢没搞赢
8-9:
做了rotate-image:
会做,因为做俄罗斯方块那个游戏的时候用到过
- 函数的引用传递时,函数的形参要加&,调用时实参不用加&直接用就行
void swap( int &front,int &back ){ int tmp = front; front = back; back = tmp; return; } swap(matrix[i][j],matrix[n-1-i][j]); -
返回值为void的函数甚至不用形式上最后写一个return
void swap( int &front,int &back ){ int tmp = front; front = back; back = tmp; }
8-12
鸽了两天,莫得办法,找了两天的课题,没心情做题。。今天做了balanced-binary-tree,就是花式递归,做出来了
做了两道题,还做了binaru-tree-inorder-traversal
就是二叉树的中序遍历,要求不用递归做,结果没想出来,做法很巧妙,我还是贴出来吧
链接:https://www.nowcoder.com/questionTerminal/1b25a41f25f241228abd7eb9b768ab9b
来源:牛客网
class Solution {
public:
vector inorderTraversal(TreeNode *root) {
vector result;
if(!root)
return result;
stack s;
TreeNode *p=root;
while(!s.empty() || p!=NULL)
{
while(p)
{
s.push(p);
p=p->left;
}
if(!s.empty())
{
p = s.top();
s.pop();
result.push_back(p->val);
p = p->right;
}
}
return result;
}
}; 8-14:
做了search-a-2d-matrix。。挺容易的一遍做出来了,不知道这道题是在搞毛
- const
const int m = matrix.size();用来修饰变量,表示m不能被再次赋值
8-17:
-
做了牛客网的专项练习,正确率60%,记录一下知识点
-
C,多进程
-
字符串"Hello"会被输出几次?
int main() { printf("Hello"); fork(); printf("Hello"); }答案是4
-
解析:
-
fork函数被声明在unistd.h头文件中
-
1.fork()函数会把它所在语句以后的语句复制到一个子进程里,单独执行。
2.如果printf函数最后没有"\n",则输出缓冲区不会被立即清空,而fork函数会把输出缓冲区里的内容也都复制到子进程里。
所以,父进程和子进程各输出2个Hello,共4个。
如果第一个printf("Hello");写成printf("Hello\n");,则只会输出3个Hello,父进程2个,子进程1个。
-
-
还有一个不错的学习例子
int main () { pid_t fpid; //fpid表示fork函数返回的值 int count=0; fpid=fork(); //以下的语句父进程和子进程都会执行,主要用pid来区分 if (fpid < 0) printf("error in fork!"); else if (fpid == 0) { printf("i am the child process, my process id is %d/n",getpid()); printf("我是爹的儿子/n");//对某些人来说中文看着更直白。 count++; } else { printf("i am the parent process, my process id is %d/n",getpid()); printf("我是孩子他爹/n"); count++; } printf("统计结果是: %d/n",count); return 0; } //输出为 i am the parent process, my process id is 3323 我是孩子他爹 统计结果是: 1 i am the child process, my process id is 3324 我是爹的儿子 统计结果是: 1
-
-
-
还做了一道leetcode题sort-colors,一道排序题把
-
我用的两层嵌套循环做出来的,别人一次循环就做出来了,得学一学,语法方面没什么要记录的
-
-
下午没事干又写了一道merge-two-sorted-lists,思路西河写的代码和答案几乎一模一样但是就是不行,原来是这个问题
-
定义一个链表结点时,得用New新建一个对象
//我的做法 ListNode *l3; //会有报错如下 //运行超时:您的程序未能在规定时间内运行结束,请检查是否循环有错或算法复杂度过大。 //case通过率为0.00% //答案的做法是 ListNode *l3 = new ListNode(0);
-
8-20:
- 做了动态规划的gray-code
- 今晚太累了,明天再写把
- 发现动态规划一个重要的做法就是找规律,找到规律就好写程序了,没啥高级的
- 学到了左移右移运算符
res.push_back(last[i] << 1); res.push_back( (last[i] << 1) + 1 ); //注意<<运算符的优先级很低,所以这里要加圆括号注意这里的圆括号是必须的
-
学到了把十进制输出成二进制的方法
#include#include using namespace std; int main(){ int x=178; //中的参数是指定输出多少位 cout<
8-25
- 做了single-number-ii:没做出来
- 这道题贼难,大概使用位的异或的方法来解决,答案都还看不太懂,我先做完single-number再来做这道题把
- 这就很尴尬了,突然发现single-numer我原来做过,但是是用的很复杂的递归方法,然后刚刚用了刚学到的异或方法写出来了
- 思路真的是太难了,我放弃,还是记录一下知识点把
//异或是 ^ ones ^= t;
-
还做了trapping-rain-water:又没做出来
-
其实题目好理解,思路也很容易有
-
就是我的方法太复杂了,最后都没信心了
-
8-26
- 做了remove-duplicates-from-sorted-array
- 挺容易的,没啥
- 做了jump-game
- 没啥,也挺容易的,今天这两道题感觉是用来找自信的
8-27
- 打球回来做道题修养身心
- 做了path-sum:
- 挺蠢得,用递归的话简直so easy
- 准备用迭代再来做一做
- 迭代看答案做出来了,主要是我不会一个用法,总结如下:
- pair包含两个数值,与容器一样,pair也是一种模板类型。但是又与之前介绍的容器不同,在创建pair对象时,必须提供两个类型名,两个对应的类型名的类型不必相同
//题目中是这么用的 stack -
可以使用pair的构造函数也可以使用make_pair来生成我们需要的pair
-
两个值可以分别用pair的两个公有函数first和second访问
- pair包含两个数值,与容器一样,pair也是一种模板类型。但是又与之前介绍的容器不同,在创建pair对象时,必须提供两个类型名,两个对应的类型名的类型不必相同
9-2
- 终于又开始做题了,做了set-matrix-zeros
- 要求是得是O(1)的空间复杂度
- 没做出来
- 又做了binary-tree-level-order-traversal
- 一遍过,毫无压力
9-6
- 今天这个不太一样,今天这个是做美团的笔试的心得
- 答案在此http://discuss.acmcoder.com/topic/5b911e94cc8bcd19007103dd
- 学到了的知识点
- map的用法
n, k, t = map(int,raw_input().split()) #输入三个数字可以这么写 - 9-8
- 做了头条的第二次笔试,做着玩的
- 5道题,在两小时内就做出了3道
- 学到的知识
- 判断一个字典里有没有某个key不仅可以用has_key还可以直接用in
like_pos_dict = {} for index,each_like in enumerate(like_list): if each_like in like_pos_dict: like_pos_dict[each_like].append(index) else: like_pos_dict[each_like] = [index] - 要注意动态规划的使用
- 二分查找中间隐藏的考点
- 一篇讲得好的文章https://www.cnblogs.com/luoxn28/p/5767571.html
- 其中需要记住的有
if __name__ == '__main__': print '请先输入升序数组' input_list = map(int,raw_input().split()) print '输入查找的目标值' target = int(raw_input()) left = 0 right = len(input_list)-1 while left<=right:#这个永远都要有=,可以用[1,3,5]中找3和5来证明 mid = (left+right)/2 if input_list[mid]<=target: left = mid +1 else: right = mid -1 if input_list[right]==target: print '要查找的元素的下标值是',right else: print '莫得啊',-1
- 判断一个字典里有没有某个key不仅可以用has_key还可以直接用in
- 9-9
- 做了头条的第三次笔试,正经的考试
- 做的一般般,前两道都是80%,第三道40%
- 牛客网上别人的程序
- 9-12
- 下午做了神策数据的笔试题,选择题上耗费的时间太多了,导致编程题很简单却没有做完,准确的说一道都没做出来,很难受,记录一波:
- 抛硬币连续出现两次正面朝上就停止,问总共抛的次数的期望
- 链接:https://www.nowcoder.com/questionTerminal/bfa0b0796e1847c8b36f96ad1614d4d0
来源:牛客网
假设期望次数是E,我们开始扔,有如下几种情况:
• 扔到的是反面,那么就要重新仍,所以是0.5*(1 + E)
• 扔到的是正面,再扔一次又反面了,则是0.25*(2 + E)
• 扔到两次,都是正面,结束,则是0.25*2
所以递归来看E = 0.5*(1 + E) + 0.25*(2 + E) + 0.25*2,解得E = 6
- 链接:https://www.nowcoder.com/questionTerminal/bfa0b0796e1847c8b36f96ad1614d4d0
- 排序思路合集
- 排序的稳定性:就是如果两个元素要是值相等的话,经过排序后他们的先后顺序不变还是和原来的序列里一样,那这个排序就是稳定的
- 简单算法:
- 冒泡排序:
def bubble_sort(array): for i in range(len(array)-1): for j in range(len(array) - i -1): if array[j] > array[j+1]: array[j], array[j+1] = array[j+1], array[j] return array #改进版 def bubble_sort(array): for i in range(len(array)-1): current_status = False for j in range(len(array) - i -1): if array[j] > array[j+1]: array[j], array[j+1] = array[j+1], array[j] current_status = True if not current_status: break-
就是不断地比较相邻的两个元素,若反序则交换位置,上面的这段程序就是不断地把最大的沉到最后面。改进版就是若这一趟顺序没变化则说明已经排好了。
-
平均复杂度为O(n^2)
-
最好的情况就是一开始就是有序的复杂度为O(n)
-
-
-
简单选择排序
def select_sort(array): for i in range(len(array)-1): min = i for j in range(i+1, len(array)): if array[j] < array[min]: min = j array[i], array[min] = array[min], array[i] return array-
就是在余下的这段序列中找到找到最小的放到前面来
-
复杂度为O(n^2)
-
无论怎么样比较次数都是一样多
-
交换次数最好的就是一开始就有序就是0次,最惨的时候就是n-1次
-
-
直接插入排序
def insert_sort(array): # 循环的是第二个到最后(待摸的牌) for i in range(1, len(array)): # 待插入的数(摸上来的牌) min = array[i] # 已排好序的最右边一个元素(手里的牌的最右边) j = i - 1 # 一只和排好的牌比较,排好的牌的牌的索引必须大于等于0 # 比较过程中,如果手里最右边的比摸上来的大, while j >= 0 and array[j] > min: # 那么手里的牌往右边移动一位,就是把j付给j+1 array[j+1] = array[j] # 换完以后在和下一张比较 j -= 1 # 找到了手里的牌比摸上来的牌小或等于的时候,就把摸上来的放到它右边 array[j+1] = min return array-
将一个元素插入到已经排序好的序列中
-
复杂度为O(n^2)
-
最好的情况下就是不需要进行这里的这个while循环所以复杂度就是O(n)
-
- 冒泡排序:
- 改进算法:
- 希尔排序:
def shell_sort(li): """希尔排序""" gap = len(li) // 2 while gap > 0: for i in range(gap, len(li)): while i >= gap and li[i] < li[i-gap]: li[i],li[i-gap] = li[i-gap],li[i] //这里其实就是插入排序 i -= gap gap //= 2 return li- 不是那么的高级,但是比前面的那些简单算法好了一些,改进版的插入排序
- 就是有一个增量用来跳跃着比较,若比较的两个元素反序则交换。然后不断的减小这个增量一直到1
- 复杂度为O(n^3/2)
- 不懂的话这有个图解说的不错的https://www.cnblogs.com/chengxiao/p/6104371.html
- 不稳定的排序
- 堆排序:
def sift(array, left, right): """调整""" i = left # 当前调整的小堆的父节点 j = 2*i + 1 # i的左孩子 tmp = array[i] # 当前调整的堆的根节点 while j <= right: # 如果孩子还在堆的边界内 if j < right and array[j] < array[j+1]: # 如果i有右孩子,且右孩子比左孩子大 j = j + 1 # 大孩子就是右孩子 if tmp < array[j]: # 比较根节点和大孩子,如果根节点比大孩子小 array[i] = array[j] # 大孩子上位 i = j # 新调整的小堆的父节点 j = 2*i + 1 # 新调整的小堆中I的左孩子 else: # 否则就是父节点比大孩子大,则终止循环 break array[i] = tmp # 最后i的位置由于是之前大孩子上位了,是空的,而这个位置是根节点的正确位置。 def heap_sort(array): n = len(array) # 建堆,从最后一个有孩子的父亲开始,直到根节点 n//2-1 -- 0 for i in range(n//2 - 1, -1, -1): # 每次调整i到结尾 sift(array, i, n-1) print array # 挨个出数 for i in range(n-1, -1, -1): # 把根节点和调整的堆的最后一个元素交换 array[0], array[i] = array[i], array[0] # 再调整,从0到i-1 sift(array, 0, i-1) return array- 改进版的简单选择排序
- 就是一开始就根据要排序的list建立一个大顶堆(其实就是根据大顶堆的规则改正list中元素的顺序),然后这个大顶堆其实就基本是有序的了(从前到后基本实现了从大到小),然后再把大顶堆的最上面那个最大的放到最后,这就相当于简单选择排序了嘛,然后现在这个堆就不再是堆了,因为最上面的那个元素不是最大的,这就调整一下就好了(这里就利用到了堆的优点,调整起来很快)。
- 复杂度为O(nlogn),但是比快排慢
- 堆排序是不稳定的:
比如:3 27 36 27,
如果堆顶3先输出,则,第三层的27(最后一个27)跑到堆顶,然后堆稳定,继续输出堆顶,是刚才那个27,这样说明后面的27先于第二个位置的27输出,不稳定。(这是个小顶堆的例子)
- 归并排序
# 一次归并 def merge(array, low, mid, high): """ 两段需要归并的序列从左往右遍历,逐一比较,小的就放到 tmp里去,再取,再比,再放。 """ tmp = [] i = low j = mid +1 while i <= mid and j <= high: if array[i] <= array[j]: tmp.append(array[i]) i += 1 else: tmp.append(array[j]) j += 1 while i <= mid: tmp.append(array[i]) i += 1 while j <= high: tmp.append(array[j]) j += 1 array[low:high+1] = tmp def merge_sort(array, low, high): if low < high: mid = (low + high) // 2 merge_sort(array, low, mid) merge_sort(array, mid+1, high) merge(array, low, mid, high) return array def merge_sort_easy(array): return merge_sort(array, 0, len(array) - 1) #自己后面写的一个非递归的归并排序 def MergeSort2(L): k=1 while(k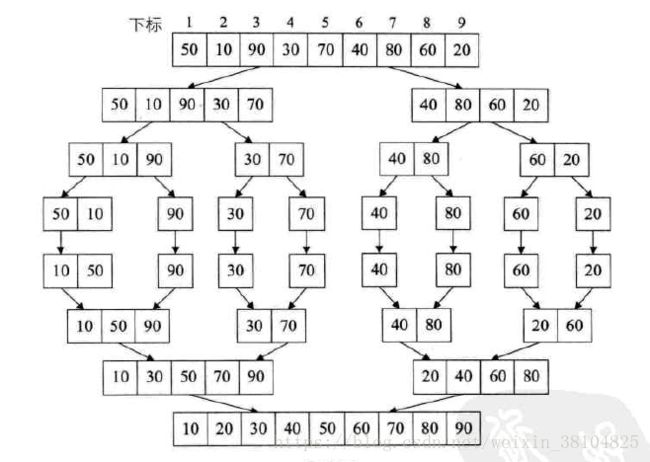
- 一图胜千言
- 时间复杂度:O(nlogn)
- 稳定排序
- 时间复杂度的公式是T[n] = 2T[n/2] + O(n)
- 这里因为把列表分成两部分排序,所以排序上花的时间是2T[n/2],然后再把排好序的两个列表融合需要扫描一遍,所以是O(n)
- 而总共需要拆分的次数是lg(n)
- 快速排序
def quick_sort(array, left, right): if left < right: mid = partition(array, left, right) quick_sort(array, left, mid-1) quick_sort(array, mid+1, right) return array def partition(array, left, right): tmp = array[left] while left < right: while left < right and array[right] >= tmp: right -= 1 array[left] = array[right] while left < right and array[left] <= tmp: left += 1 array[right] = array[left] array[left] = tmp return left def quick_sort_easy(array): return quick_sort(array, 0, len(array)-1)- 升级版冒泡排序
- 就是在一个序列中随便找一个元素(比如第一个),然后以这个元素为基准找到它所在的位置,这样这个元素就排好序了,它左边的都比它小,右边的都比它大。然后再左右两个子序列这样递归
- 时间复杂度:O(nlogn)
- 最惨的情况就是正序或者逆序,复杂度为O(N^2)
- 希尔排序:
- 抛硬币连续出现两次正面朝上就停止,问总共抛的次数的期望
- 晚上做了迅雷的笔试,运维工程师,发现做运维挺没意思的,考的题目几乎全都是linux的使用啊网络相关的,不喜欢,花了半个小时随便做了做
- 下午做了神策数据的笔试题,选择题上耗费的时间太多了,导致编程题很简单却没有做完,准确的说一道都没做出来,很难受,记录一波:
- 9-13
- 做了几道牛客网的专项练习,总结如下
- scanf。%c是读入一个字符。在用"%c"输入时,空格和“转义字符”均作为有效字符。
char ch1,ch2,ch3; scanf("%1c%2c%3c",&ch1,&ch2,&ch3); //输入为 1□22□333 //输出为’1’、’ ’、’2’ /* 当格式控制符是%nc,空格和转义字符均作为有效字符被输入,将把n个字 符中的第一个字符赋值给相应的字符变量,其余字符被舍弃。所以ch1的值为’1’,ch2将是 □2的第一个空格符’ ‘,ch3为2□3的第一个字符’2’ */ scanf("%c%c%c",&c1,&c2,&c3); //输入为 a□b□c↙ //输出为 a→c1,□→c2,b→c3 (其余被丢弃) -
一些基本概念
-
承载信息量的基本信号单位是:码元
-
波特率又称码元率,是指每秒传输码元的数目,单位波特(Band)
-
码元: 在数字通信中常常用时间间隔相同的符号来表示一个二进制数字,这样的时间间隔内的信号称为(二进制)码元。 这是百度百科的解释
-
通俗点说,可以把一个码元看做一个存放一定信息量的包,如果只存放1bit,那么波特率等于比特率,但是一般不止存放1bit
如一串二进制信息为101010101 当一个码元携带的信息量为1bit时,那么就有9个码元,其波特率相当于比特率,如果每三个一组101,010,101,这时就可以使用8种振幅来表示某个码元,这里相当于一个码元就包含了3bit,这里码元的离散取值数目就是8。 -
比特率为每秒传输的比特(bit)数
-
由此可得波特率和比特率的关系 :
若码元的离散取值数目是L,波特率是B,数据率(比特率)为C,则
C = B log₂L.(当L=2时,C=B)
-
-
名词解释
-
DDN是“Digital Data Network”,数字数据网
-
ISDN 是“Integrated Services Digital Network”,综合业务数字网
-
-
图
-
简单路径和环是相对的
-
拓扑排序就是对于一个有向的不存在环路的图提取出它的按照箭头排序的结果,所以拓扑序列可能不止一条
-
-
若磁盘转速为7200转/分,平均寻道时间为8ms,每个磁道包含1000个扇区,则访问一个扇区的平均存取时间大约是:12.2ms
-
存取时间=寻道时间+延迟时间+传输时间。存取一个扇区的平均延迟时间为旋转半周的时间,即为(60/7200)/2=4.17ms,传输时间为(60/7200)/1000=0.01ms,因此访问一个扇区的平均存取时间为4.17+0.01+8=12.18ms,保留一位小数则为12.2ms。
-
上面这个延迟时间就是磁盘转到那个半径的时间,所以这里算的是半圈的时间
-
传输时间就比较扯了,可以忽略不计,因为它就是访问这个扇区的时间,肯定小啊
-
寻道时间是沿着半径方向的时间吧
-
-
进程间的通信方式
-
管道
-
它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端。
-
它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)。
-
它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
-
-
消息队列
-
是消息的链接表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
-
-
信号量
-
信号量(semaphore)与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
-
-
共享存储
-
指两个或多个进程共享一个给定的存储区。
-
-
Socket
-
套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
-
-
Streams
-
-
进行数据库提交操作时使用事务(Transaction)是为了?
保证数据一致性-
通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠
-
事务:事务提供了一种机制,可用来将一系列数据库更改归入一个逻辑操作。事务是单个的工作单元。如果某个事务成功,则在该事务中进行的所有数据更改均会提交,成为数据库中的永久组成部分。如果事务遇到错误且必须取消或回滚,则所有数据更改均被清除。
-
-
Linux什么情况下会发生page fault
-
计算机的物理内存(看看你的内存条)有限,一般现在都是几个GB的容量了,BTW,我的笔记本有8GB,:-)。但应用程序的需求是无限的,操作系统为了解决这个矛盾,使用了虚拟内存的设计。简单的描述就是,给应用程序一个与物理内存无关的虚拟地址空间,并提供一套映射机制,将虚拟地址映射到物理内存。当然应用程序是不知道有这个映射机制存在的,他唯一需要做的就是尽情的使用自己的虚拟地址空间。操作系统提供的映射机制是运行时动态进行虚拟地址和物理地址之间的映射的,当一个虚拟地址没有对应的物理内存时候,映射机制就分配物理内存,构建映射表,满足应用程序的需求,这个过程就叫page fault。
-
虚拟内存:
-
需要注意的是:虚拟内存不只是“用磁盘空间来扩展物理内存”的意思——这只是扩充内存级别以使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,它的作用也可以通过覆盖或者把处于不活动状态的程序以及它们的数据全部交换到磁盘上等方式来实现。对虚拟内存的定义是基于对地址空间的重定义的,即把地址空间定义为“连续的虚拟内存地址”,以借此“欺骗”程序,使它们以为自己正在使用一大块的“连续”地址。
-
需要注意的是:虚拟内存不只是“用磁盘空间来扩展物理内存”的意思——这只是扩充内存级别以使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,它的作用也可以通过覆盖或者把处于不活动状态的程序以及它们的数据全部交换到磁盘上等方式来实现。对虚拟内存的定义是基于对地址空间的重定义的,即把地址空间定义为“连续的虚拟内存地址”,以借此“欺骗”程序,使它们以为自己正在使用一大块的“连续”地址。
-
-
-
下面操作系统不是网络操作系统的是:
-
A:Netware B:Windows 2000 Server C:DOS D:Linux 选DOS
-
网络操作系统(network operation system –NOS)主要是指运行在各种服务器上、能够控制和管理网络资源的特殊的操作系统,它在计算机操作系统下工作,使计算机操作系统增加了网络操作所需要的能力。 目前主要的网络操作系统有UNIX、linux、windows以及Netware系统等。
-
DOS是Disk Operation System的简称,意为磁盘操作系统,它是一种面向磁盘的系统软件,是连接用户与计算机之间的桥梁。它的主要任务是:管理计算机各种设备、控制程序的运行、处理各种命令。DiskOperatingSystem。DOS没有网络管理功能,所以不是网络操作系统
-
-
以下哪种介质访问控制机制不能完全避免冲突:
-
A 令牌环 B TDMA C FDDI D CSMA/CD 结果是D
-
定义:介质访问控制方式,也就是信道访问控制方法,可以简单的把它理解为如何控制网络节点何时发送数据、如何传输数据以及怎样在介质上接收数据。简单地说就是局域网中控制多台电脑用同一根双绞线通信时协调的控制方式。
-
CSMA/CD:载波监昕多点接入/碰撞检测(Carrier Sense Multiple Access wi伽Collision Detection)
-
“多点接入”就是说明这是总线型网络,许多计算机以多点接入的方式连接在一根总线上。协议的实质是“载波监昕”和“碰撞检测”。
-
“载波监昕”就是“发送前先监昕”,即每一个站在发送数据之前先要检测一下总线上是否有其他站在发送数据,如果有,则暂时不要发送数据,要等待信道变为空闲时再发送。其实总线上并没有什么“载波”,“载波监昕”就是用电子技术检测总线上有没有其他计算机发送的数据信号。
-
“碰撞检测”就是“边发送边监昕”,即适配器边发送数据边检测信道上的信号电压的变化情况,以便判断自己在发送数据时其他站是否也在发送数据。当几个站同时在总线上发送数据时,总线上的信号电压变化幅度将会增大(互相叠加)。当适配器检测到的信号电压变化幅度超过一定的门限值时,就认为总线上至少有两个站同时在发送数据,表明产生了碰撞。所谓“碰撞”就是发生了冲突。因此“碰撞检测”也称为“冲突检测”。这时,总线上传输的信号产生了严重的失真,无法从中恢复出有用的信息来。因此,每→个正在发送数据的站,一旦发现总线上出现了碰撞,适配器就要立即停止发送,免得继续浪费网络资源,然后等待一段随机时间后再次发送。
-
既然每一个站在发送数据之前已经监听到信道为“空闲飞那么为什么还会出现数据在
总线上的碰撞呢?这是因为电磁波在总线上总是以有限的速率传播的。因此当某个站监听到
总线是空闲时,总线并非一定是空闲的。 -
显然,在使用CSMA/CD 协议时,一个站不可能同时进行发送和接收。因此使用
CSMA/CD 协议的以太网不可能进行全双工通信而只能进行双向交替通信(半双工通信)。
-
-
TDMA
-
时分复用TDM(Time Division Multiplexing):
-
时分复用则是将时间划分为一段段等长的时分复用帧( TDM 帧)。每一个时分复用的用户在每二个TDM 帧中占用固定序号的时隙。每一个用户所占用的时隙是周期性地出现(其周期就是TDM 帧的长度)。因此TDM 信号也称为等时(isochronous)信号。可以看出,时分复用的所有用户是在不同的时间占用同样的频带宽度
-
-
时分多址(time division multiple access,TDMA)
-
把时间分割成互不重叠的时段(帧),再将帧分割成互不重叠的时隙(信道)与用户具有一一对应关系,依据时隙区分来自不同地址的用户信号,从而完成的多址连接。
-
通俗解释:一条马路有很多车要在上面开,一次只能开一辆,把时间分割成互不重叠的时段(帧),再将帧分割成互不重叠的时隙(信道)与用户具有一一对应关系,依据时隙区分来自不同地址的用户信号,从而完成的多址连接。
-
-
-
FDDI
-
光纤分布式数据接口 Fiber Distributed Data Interface,缩写FDDI)
-
除了上述的高速以太网外,也还有一些其他类型的高速局域网。例如,在1988 年问世的光纤分布式数据接口FDDI (Fiber Distributed Data Interface)是一个使用光纤作为传输媒体的令牌环形网。
- FDDI建立在小令牌帧的基础上,当所有站都空闲时,小令牌帧沿环运行。当某一站有数据要发送,必须等待有令牌通过是才可发送。一旦识别出有用的令牌,该站便将其吸收,随后可发送一帧或多帧。这时环上没有令牌环,便在环上插入一新的令牌,不必像802.5令牌那样,只有收到自己发送的帧后才能释放令牌。因此,任一时刻环上可能会有来自多个站的帧运行
-
-
- 令牌环
- 令牌环网是IBM公司于70年代发展的,现在这种网络比较少见。在老式的令牌环网中,数据传输速度为4Mbps或16Mbps,新型的快速令牌环网速度可 达100Mbps。Token Ring(令牌环)是一种 LAN 协议
- 原理:令牌环Token Ring协议是环型网中最普遍采用的介质访问控制,它在环中加入一特殊的MAC控制帧,即令牌帧,用于控制结点有序访问介质。其工作过程如下:
- 令牌环Token Ring协议是环型网中最普遍采用的介质访问控制,它在环中加入一特殊的MAC控制帧,即令牌帧,用于控制结点有序访问介质。其工作过程如下:
- 如果结点A有数据要发送,它必须等待空闲令牌到达本站,当获得空闲令牌后,它将令牌标志位由“闲”置为“忙”,并构造成数据帧进行传输。
- 数据帧在环上做广播传输,其他结点可依次接收到数据帧,但只有目的地址相匹配的结点才复制。
- 数据帧遍历环后,回到结点A,由A回收数据帧,并将令牌状态改为空闲,然后将空闲令牌传送到下一结点。
- 每个结点都有一个令牌持有计时器THT (Token Holding Timer),当发送结点数据帧后,THT开始计时。当数据帧在环上循环一周返回到发送结点后,如果THT未超时,该结点可继续发送数据;如果THT超 时,该结点即使有数据要传送,也必须向下游结点发送令牌帧,要传送的数据必须等到再次获得令牌帧才能发送。THT反映了网络负载状况,网络负载越重,各个 结点在THT内所发送的数据帧越少。通过THT可以控制各个结点占有介质的时间长度,并且各个结点可以通过THT测算出需要等待多长时间才能获得令牌帧访 问介质。
-
- 处于挂起就绪状态(即静止就绪状态)的进程,可转换为( )
- 就绪状态(即活动就绪状态)
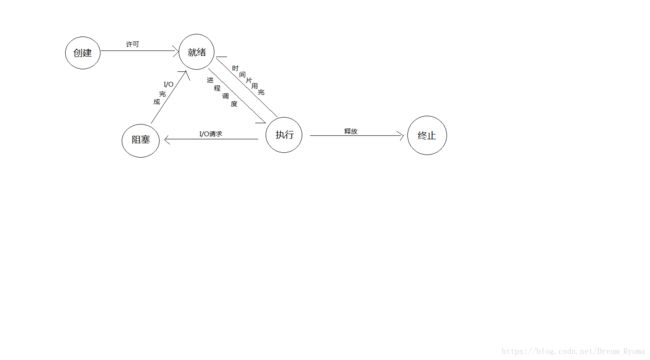
- 进程的三种基本状态。进程执行时的间断性决定了进程在创建后到执行完这个生命周期中具有多种状态。运行中的进程具有以下三种基本状态:
- 就绪状态。当进程已分配到除CPU以外的所有必要资源后,只要再获得CPU,便可立即执行,进程这时的状态称为就绪状态。在一个系统中处于就绪状态的进程可能有多个,通常将它们排成一个队列,称为就绪队列。
- 执行状态。进程已经获得CPU,其程序正在执行。在单处理机系统中,只有一个进程处于执行状态;在多处理机系统中,则有多个进程处于执行状态。
- 阻塞状态。正在执行的进程由于发生某事件而暂时无法继续执行时,便放弃处理器而处于暂停状态,亦即进程的执行受到阻塞,把这种暂停状态称为阻塞状态,也称为等待状态。致使进程阻塞的典型事件有请求I/O,申请缓冲空间等,通常将这种处于阻塞状态的进程也排成一个队列。有的系统也则根据阻塞原因的不同而把处于阻塞状态的进程排成多个队列。
- 不少操作系统中进程只有以上三种状态,但在另一些系统中,又增加了一些新状态,最重要的是挂起状态。引入挂起状态的原因有:
- 中断用户的请求。当中断用户在自己的程序运行期间发现有可疑问题时,希望暂时使自己的程序静止下来。即,使正在执行的进程暂停执行;若此时用户进程正处于就绪状态而未执行,则该进程暂不接受调度,以便用户研究其执行情况或对程序进行修改。我们把这种静止状态成为挂起状态。
- 父进程请求。有时父进程希望挂起自己的某个子进程,以便考察和修改该子进程,或者协调各子进程间的活动。
- 负荷调节的需要。当实时系统中的工作负荷较重,已可能影响到对实时任务的控制时,可由系统把一些不重要的进程挂起,以保证系统能正常运行。
- 操作系统的需要。操作系统有时希望挂起某些进程,以便检查运行中的资源使用情况或进行记账。
- 在引入挂起状态后,又将增加从挂起状态(静止状态)到非挂起状态(活动状态)的双向转换,也就增加了系统复杂度和开销。
- 活动就绪--->静止就绪。当进程处于未被挂起的就绪状态时,称此为活动就绪状态。当用挂起原语将该进程挂起后,该进程便转变为静止就绪状态,处于就绪状态的进程不再被调度执行。
- 活动阻塞--->静止阻塞。当进程处于未被挂起的阻塞状态时,称它是处于活动阻塞状态。当用挂起原语将它挂起后,进程便转变为静止阻塞状态。处于该状态的进程在其所期待的事件出现后,将从静止阻塞变为静止就绪。
- 静止就绪--->活动就绪。处于静止阻塞状态的进程,若用激活原语激活后,该进程将转变为活动就绪状态。
- 静止阻塞--->活动阻塞。处于静止阻塞状态的进程,若用激活原语激活后,该进程将转变为活动阻塞状态。
- 在使用双绞线连接下面设备时,需要使用交叉线连接的场合是
- 两台计算机通过网卡直接连接
-
双绞线连接方式:
直通线用于连接不同类设备:电脑---交换机, 交换机----路由器
交叉线用于连接相同类设备:电脑----电脑 , 交换机----交换机
反转线用于电脑直接连接路由器:. 电脑----路由器
-
直通线:两头都是A类或B类
-
交叉线:一头A类一头B类
-
反转线:一头A类另一头把A类线的线序反过来
-
一般来说,网线传输数据的时候,是两个线发送,另外两根用来接收。比如,我们按照线序1,2,3,4,5,6,7,8(白橙,橙,白绿,蓝,白蓝,绿,白棕,棕)排序。1,2用来发送数据;3,6用来接收数据。
具体就是1发3收,2发6收。我们知道,计算机上的网线接口里面也有八条线对应着网线的八条线,而且每台计算机的网线接口里面的线序都是一样的,这样才能实现统一化,不可能为不同的计算机设计不同的线序,也没有必要这样做。当相同设备传输信号时,若用直通线,那么发送数据的计算机的1号线对应接收数据的计算机的1号线,而我们知道发送数据的计算机的1号线应该对应的是接收数据的计算机的3号线,所以如果不进行交叉的话,将导致对方无法接收数据。二交叉性则能解决这个问题(1与3互换,2与6互换),所以必须用交叉线。
- scanf。%c是读入一个字符。在用"%c"输入时,空格和“转义字符”均作为有效字符。
- 做了几道牛客网的专项练习,总结如下
-
9-15
-
数据库索引
-
马踏棋盘问题
-
一个网站在登陆后几天内不需要再登陆的原理
-
-
9-16
-
允许远程主机访问本机8080端口的防火墙策略是
-
B树和B+树
-
mapreduce
-
tencent的二进制哈夫曼编码有多少位
-
尾递归能不能解决递归调用导致的栈溢出的问题
-
C++虚函数、private变量、protected变量在继承时子类的一些特性
-
磁头调度中,电梯调度SCAN算法
-
形象的电梯调度算法。先按照一个方向(比如从外向内扫描),扫描的过程中依次访问要求服务的序列。当扫描到最里层的一个服务序列时反向扫描,这里要注意,假设最里层为0号磁道,最里面的一个要求服务的序列是5号,访问完5号之后,就反向了,不需要再往里扫。结合电梯过程更好理解,在电梯往下接人的时候,明知道最下面一层是没有人的,它是不会再往下走的。 --------------------- 本文来自 Jaster_wisdom 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/jaster_wisdom/article/details/52345674?utm_source=copy
-
-
OSI模型中,网络层将数据封装成____后发送到链路层,哪一层提供了流量控制功能,链路层的服务访问点是?
-
包
-
数据链路层、网络层和传输层均需采用流量控制
-
服务访问点,简称SAP,实际就是逻辑接口,是一个层次系统的上下层之间进行通信的接口,N层的SAP就是N+1层可以访问N层服务的地方。
物理层的服务访问点就是网卡接口,数据链路层的服务访问点是MAC地址,网络层的服务访问点是IP地址,传输层的服务访问点是端口号,应用层提供的服务访问点是用户界面
-
-
修改一个目录及其目录下的所有文件为所有人可读可写为
-
关于操作系统的置换算法,正确的是
-
A LRU是选择最长时间为访问的进行淘汰
-
B OPT页面置换算法选择的被淘汰页面是以后永远不使用的,或者在最长时间内不再被访问的页面
-
C LRU可能出现relay异常
-
D FIFO优先淘汰最早进入内存的页面
-
最近最少使用算法(LRU)选择最后一次访问时间距离当前时间最长的置换掉
-
最佳页面置换算法(OPT)思想:置换以后不再需要的或者最远才会需要的页面 所谓一种衡量标准
-
先进先出算法(FIFO)
-
-
-
C++中vector初始化的方式
-
一下关于C++多态的说法中错误的是:
-
A 程序运行时,可以通过子类指针来调用父类虚函数的实现来实现多态
-
B 多态指不同的对象接收相同的信息时可以产生不同的动作
-
C 程序编译时的多态体现在函数和运算符的重载
-
D 程序运行时的多态通过继承和虚函数来实现
-
-
TCP具体了解一下
-
关于程序的链接错误的
-
sql的left join 和inner join
-
-
9-18
-
今天去bigo的现场面试了做的是web方向的卷子,考点除了编程题都集中在操作系统、计算机网络、数据库上
-
选择题做的还行,没有把握的基本都是TCP协议具体的一些东西
-
编程题两道,第一道很稳,第二道要自己实现某个目录下的子目录和子文件的显示,我只会用python的os模块而且具体的函数还忘了
import os def traverse(f): fs = os.listdir(f) for f1 in fs: tmp_path = os.path.join(f, f1) if not os.path.isdir(tmp_path): print('文件: %s' % tmp_path) else: print('文件夹:%s' % tmp_path) traverse(tmp_path) path = 'D:/data/share_from_windows/jieba_learn/jieba/' traverse(path) -
大题4道
-
如何理解TCP协议的wait还是啥的,反正是TCP协议的一些具体的东西
-
不会
-
-
如何理解操作系统中的时间片概念
-
幸亏老夫吊,这几天看操作系统的视频刚学到
-
-
说一下HTTPS的加密过程
-
具体的我不会,就写了其在SSL协议上,SSL负责加密
-
-
说说如何负载均衡
-
真不会
-
-
-
-
晚上做了滴滴的笔试
-
选择题做的还行,需要继续学习的如下
-
联合索引
-
逻辑地址与物理地址的转换
-
聚簇索引和非聚簇索引
-
前序遍历、中序遍历、后序遍历这三个已知两个求第三个问题
-
判断一个IP是不是一个网段的有效IP
-
TCP具体
-
子网掩码的计算
-
软连接硬链接的一些具体的
-
死锁
-
浮点数的一些概念:阶段、尾数
-
线程对信号的处理是不是共享的
-
一条线段分成3段能够形成三角形的概率
-
HTTP具体。。永久重定向
-
-
编程题就比较尴尬了,0.7/2
-
第一题是关于编辑距离的,这个我会,但是编辑距离的实现自己写还是比较难
-
第二题是我的一个痛点,一直以来有缺陷的地方,用递归实现排列组合。程序一直都有问题,这个涉及到了很多东西,比如list的传递。
-
-
-
-
9-21
-
晚上做了小米的笔试,怕是凉凉,因为面试回来没时间写了
-
设计模式
-
协程
-
队列与栈的相互实现
-
快排可以不用递归,快排的最优时间复杂度
-
-
-
9-22
-
做了BOOS直聘的笔试,选择题还行,编程题1.5/3,怕是凉凉
-
X86体系结构下三种地址的转换
-
在一个建立了TCP连接的SOCKET上用recv,返回为0,代表什么意思
-
语法分析器可以用于
-
哈夫曼树
-
-
-
9-25
-
做了作业帮的笔试
-
基数排序
-
sal修改表的结构
-
-
-
9-27
-
做了度小满金融的笔试,贼难,刷经验了就当,反正也只花了一个小时
-
IPV6地址类型
-
森林转化为二叉树
-
平均查找长度
-
二叉排序树ASL
-
成组调度方式、自调用方式、处理器时间损耗
-
从已知的MAC地址得出IP地址的协议
-
回溯法解0/1背包问题
-
红黑树、B+树
-
红黑树的五条规则
- 节点不是红色就是黑色
- 根节点是黑色
- 每个叶子节点都是黑色的空节点(NIL节点)
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
- 真挺复杂的,我觉得主要是得理解来源和思想就行了,具体的各种case酒真的算了。这里是漫画图解红黑树
- 对比:
- AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而的英文旋转非常耗时的,由此我们可以知道AVL树适合用于插入与删除次数比较少,但查找多的情况
- 由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。
- 也是某大神写的关于我近期困惑的所有树的对比
-
-
-
-
动态分区分配算法
-
做了iHandy的笔试,做挺好的,收到了面试通知了
-
字长、存储容量、寻址范围
-
HTTP 301 400 200 304
-
硬实时系统合适的调度算法
-
同步、互斥关系
-
查找二叉树
-
排序算法最坏的时间复杂度
-
-
-
9-28
-
做了FACE++的笔试 有很多C/C++的题,应该是崩了
-
从DDR内存、千兆网络、SSD硬盘上读取4K数据,时间从大到小的排序
-
计数排序、桶排序
-
-
晚上自觉的做了一套题练了一下
-
用户表users中含有100万条数据,其中号码字段phone为字符型,并创建了唯一索引,且电话号码全部由数字组成,要统计号码头为158的电话号码的数量,下面写法执行速度最慢的是___
-
select count(*) from users where phone>= ‘158’ and phone< ‘158A’ -
select count(*) from users where phone like ‘158%’ -
select count(*) from users where substr(phone,1,3) = ‘158’ -
都一样快 - 答案是第三个,因为在查询基础上使用函数速度更慢(其实不知道为什么)
- 还有A这个点需要挖一下
-
- 1024! 末尾有多少个0?->253
- 末尾0的个数取决于乘法中因子2和5的个数。显然乘法中因子2的个数大于5的个数,所以我们只需统计因子5的个数。
是5的倍数的数有: 1024 / 5 = 204个
是25的倍数的数有:1024 / 25 = 40个
是125的倍数的数有:1024 / 125 = 8个
是625的倍数的数有:1024 / 625 = 1个
所以1024! 中总共有204+40+8+1=253个因子5。
也就是说1024! 末尾有253个0。
- 末尾0的个数取决于乘法中因子2和5的个数。显然乘法中因子2的个数大于5的个数,所以我们只需统计因子5的个数。
- 从n个数中找出最小的k个数(n >> k),最优平均时间复杂度是?->O(nlogk)
-
1.先直接排序,再取排序后数据的前k个数。排序算法用最快的堆排序,复杂度也会达到O(N*logN)。当k接近于N时,可以用这种算法。
2.先排序前k个数,对于后面N-k个数,依次进行插入。时间复杂度为O(k*n)。当k很小时,可以用这种算法。
3.对前k个数,建立最大堆,对于后面N-k个数,依次和最大堆的最大数比较,如果小于最大数,则替换最大数,并重新建立最大堆。时间复杂度为O(N*logk)。当k和N都很大时,这种算法比前两种算法要快很多。
-
-
-
-
10-10
-
做了两个笔试,记录一下
-
B+树和红黑树的插入的时间复杂度
-
HTTP/2相关
-
UNIX系统中的目录结构
-
-
-
10-12
-
系统抖动
-
磁盘的读写单位(块、簇的定义)
-
文本加密的方法
-