Apache Flume (完整篇)
作者:jiangzz 电话:15652034180 微信:jiangzz_wx 微信公众账号:jiangzz_wy
概述
Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。Flume构建在日志流之上一个简单灵活的架构。它具有可靠的可靠性机制和许多故障转移和恢复机制,具有强大的容错性。使用Flume这套架构实现对日志流数据的实时在线分析。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。本次课程使用的是apache-flume-1.9.0-bin.tar.gz
架构
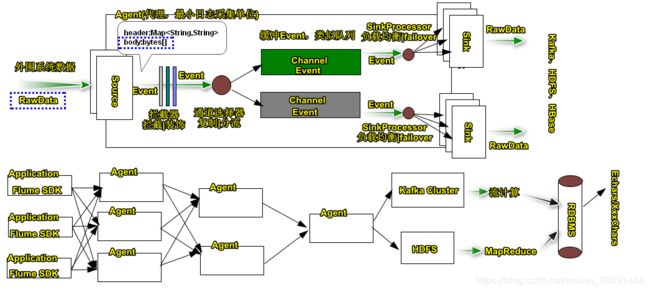
概念介绍:Agent,Source/Sink/Event/拦截器/SinkProcessor
安装
- 安装JDK 1.8+ 配置环境变量
- 安装Flume
[root@CentOSA ~]# tar -zxf apache-flume-1.9.0-bin.tar.gz -C /usr/
[root@CentOSA ~]# cd /usr/apache-flume-1.9.0-bin/
[root@CentOSA apache-flume-1.9.0-bin]# ./bin/flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
Agent配置
# 声明组件信息
.sources =
.sinks =
.channels =
# 组件配置
.sources.. =
.channels.. =
.sinks.. =
# 链接组件
.sources..channels = ...
.sinks..channel =
、、表示组件的名字,系统有哪些可以使用的组件需要查阅文档http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
快速入门
[root@CentOSA apache-flume-1.9.0-bin]# vi conf/demo01.properties
[root@CentOSA ~]# yum install -y telnet #必须安装该插件,否则
r1组件无法运行
# 声明组件信息
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 组件配置
a1.sources.r1.type = netcat
a1.sources.r1.bind = CentOSA
a1.sources.r1.port = 44444
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 链接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动组件
[root@CentOSA apache-flume-1.9.0-bin]# ./bin/flume-ng agent --conf conf/ --conf-file conf/demo01.properties --name a1 -Dflume.root.logger=INFO,console
测试
[root@CentOSA ~]# telnet CentOSA 44444
Trying 192.168.40.129...
Connected to CentOSA.
Escape character is '^]'.
hello world
OK
ni hao
OK
常规组件罗列
Source(采集外围数据)
Avro Source :使用AVRO协议远程收集数据。
Thrift Source:使用Thrift协议远程收集数据。
Exec Source:可以讲控制台输出数据采集到Agent。
Spooling Directory Source:采集指定目录下的静态数据。
Taildir Source:动态采集文本日志文件中新产生的行数据。
Kafka Source:采集来自Kafka消息队列中的数据。
Sink(写出数据):
Avro Sink:使用AVRO协议将数据写出给Avro Source|Avro服务器。
Thrift Sink:使用Thrift协议将数据写出给Thrift Source|Thrift 服务器。
HDFS Sink:将采集的数据直接写入HDFS中。
File Roll Sink:将采集的数据直接写入本地文件中。
Kafka Sink:将采集的数据直接写入Kafka中。
Channel(缓冲数据):
Memory Channel:使用内存缓存Event
JDBC Channel:使用Derby嵌入式数据库文件缓存Event
Kafka Channel:使用Kafka缓存Event
File Channel:使用本地文件系统缓存Event
常见组间配置案例
Spooling Directory Source|File Roll Sink|JDBC Channel
[root@CentOS apache-flume-1.9.0-bin]# vi conf/demo02.properties
[root@CentOSA ~]# mkdir /root/{spooldir,file_roll}
# 声明组件信息
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 组件配置
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/spooldir
a1.sources.r1.deletePolicy = never
a1.sources.r1.fileSuffix = .DONE
a1.sources.r1.includePattern = ^.*\\.log$
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /root/file_roll
a1.sinks.k1.sink.rollInterval = 0
a1.channels.c1.type = jdbc
# 链接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[root@CentOSA apache-flume-1.9.0-bin]# ./bin/flume-ng agent --conf conf/ --conf-file conf/demo02.properties --name a1
Taildir Source|HDFS Sink|File Channel
[root@CentOSA apache-flume-1.9.0-bin]# vi conf/demo03.properties
[root@CentOSA ~]# mkdir /root/{tail_dir1,tail_dir2}
# 声明组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source属性
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /root/tail_dir1/.*log.*
a1.sources.r1.filegroups.f2 = /root/tail_dir2/.*log.*
# 配置sink属性
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/logs/%Y-%m-%d/
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType = DataStream
a1.channels.c1.type = file
# 将source|Sink连接channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
运行主机环境变量必须配置HADOOP_HOME,
[root@CentOSA apache-flume-1.9.0-bin]# ./bin/flume-ng agent --conf conf/ --conf-file conf/demo03.properties --name a1
AVRO Source |Memory Channel|Logger Sink
[root@CentOS apache-flume-1.9.0-bin]# vi conf/demo04.properties
# 声明组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source属性
a1.sources.r1.type = avro
a1.sources.r1.bind = CentOS
a1.sources.r1.port = 44444
# 配置sink属性
a1.sinks.k1.type = logger
# 配置channel属性
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source连接channel
a1.sources.r1.channels = c1
# 将sink连接channel
a1.sinks.k1.channel = c1
AVRO Source |Memory Channel|Kafka Sink
[root@CentOS apache-flume-1.9.0-bin]# vi conf/demo05.properties
# 声明组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source属性
a1.sources.r1.type = avro
a1.sources.r1.bind = CentOSA
a1.sources.r1.port = 44444
# 配置sink属性
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = CentOSA:9092,CentOSB:9092,CentOSC:9092
a1.sinks.k1.kafka.topic = topicflume
# 配置channel属性
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source连接channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[root@CentOSA apache-flume-1.9.0-bin]# ./bin/flume-ng agent --conf conf/ --conf-file conf/demo05.properties --name a1
使用系统提供的avro-client命令发送日志给Avro Source
[root@CentOSA apache-flume-1.9.0-bin]# ./bin/flume-ng avro-client --host CentOSA --port 44444 --filename /root/install.log
API 集成
<dependency>
<groupId>org.apache.flumegroupId>
<artifactId>flume-ng-sdkartifactId>
<version>1.9.0version>
dependency>
单机
RpcClient client= RpcClientFactory.getDefaultInstance("192.168.40.129",44444);
Event event= EventBuilder.withBody("1 zhangsan true 28".getBytes());
client.append(event);
client.close();
集群-负载均衡
Properties props = new Properties();
props.setProperty(RpcClientConfigurationConstants.CONFIG_CLIENT_TYPE, "avro");
props.put("client.type", "default_loadbalance");
props.put("hosts", "h1 h2 h3");
String host1 = "192.168.40.129:44444";
String host2 = "192.168.40.129:44444";
String host3 = "192.168.40.129:44444";
props.put("hosts.h1", host1);
props.put("hosts.h2", host2);
props.put("hosts.h3", host3);
props.put("host-selector", "random"); // round_robin
RpcClient client= RpcClientFactory.getInstance(props);
Event event= EventBuilder.withBody("1 zhangsan true 28".getBytes());
client.append(event);
client.close();
参考:http://flume.apache.org/releases/content/1.9.0/FlumeDeveloperGuide.html#client-sdk
Flume和日志框架集成
<dependency>
<groupId>org.apache.flumegroupId>
<artifactId>flume-ng-sdkartifactId>
<version>1.9.0version>
dependency>
<dependency>
<groupId>org.apache.flume.flume-ng-clientsgroupId>
<artifactId>flume-ng-log4jappenderartifactId>
<version>1.9.0version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.5version>
dependency>
参考:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#log4j-appender
单机
log4j.rootLogger=debug,FLUME
log4j.appender.FLUME=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.FLUME.Hostname = 192.168.40.129
log4j.appender.FLUME.Port = 44444
log4j.appender.FLUME.UnsafeMode = true
log4j.appender.FLUME.layout=org.apache.log4j.PatternLayout
log4j.appender.FLUME.layout.ConversionPattern=%p %d{yyyy-MM-dd HH:mm:ss} %c %m%n
负载均衡配置
log4j.rootLogger=debug,FLUME
log4j.appender.FLUME= org.apache.flume.clients.log4jappender.LoadBalancingLog4jAppender
log4j.appender.FLUME.Hosts = 192.168.40.129:44444,...
log4j.appender.FLUME.Selector = ROUND_ROBIN
log4j.appender.FLUME.UnsafeMode = true
log4j.appender.FLUME.layout=org.apache.log4j.PatternLayout
log4j.appender.FLUME.layout.ConversionPattern=%p %d{yyyy-MM-dd HH:mm:ss} % c %m%n
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class TestLog4j {
private static Log log= LogFactory.getLog(TestLog4j.class);
public static void main(String[] args) {
log.debug("你好!_debug");
log.info("你好!_info");
log.warn("你好!_warn");
log.error("你好!_error");
}
}
其他组件
- 拦截器:Timestamp Interceptor、Host Interceptor、Static Interceptor、Remove Header Interceptor、UUID Interceptor、Search and Replace Interceptor、Regex Filtering Interceptor、Regex Filtering Interceptor、Regex Extractor Interceptor
- 通道选择器:Replicating Channel Selector、Multiplexing Channel Selector
Avro Source | Memeory Channel |File_ROLL Sink
# 声明组件
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 配置source属性
a1.sources.r1.type = avro
a1.sources.r1.bind = CentOSA
a1.sources.r1.port = 44444
# 配置拦截器
a1.sources.r1.interceptors = i1 i2
# 正则过滤拦截器
a1.sources.r1.interceptors.i1.type = regex_filter
a1.sources.r1.interceptors.i1.regex = ^\\W*(INFO|ERROR)\\W+.*UserService.*$
# 正则抽取拦截器
a1.sources.r1.interceptors.i2.type = regex_extractor
a1.sources.r1.interceptors.i2.regex = ^\\W*(INFO|ERROR)\\W+.*$
a1.sources.r1.interceptors.i2.serializers = s1
a1.sources.r1.interceptors.i2.serializers.s1.name = type
# 配置sink属性
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /root/file_roll_info
a1.sinks.k1.sink.rollInterval = 0
a1.sinks.k2.type = file_roll
a1.sinks.k2.sink.directory = /root/file_roll_error
a1.sinks.k2.sink.rollInterval = 0
# 配置channel属性
a1.channels.c1.type = memory
a1.channels.c2.type = memory
# 将source连接channel
a1.sources.r1.channels = c1 c2
# 配置多路通道选择器
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = type
a1.sources.r1.selector.mapping.ERROR = c2
a1.sources.r1.selector.mapping.INFO = c1
a1.sources.r1.selector.default = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
- SinkProcessor:当一个Channel对接多个Sink输出的时候,这些Sink会被归为一个组SinkGroup,组内的Sinks可以工作在 故障转移、负载均衡。
# 声明组件
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
# 将看 k1 k2 归纳一个组
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
# 配置source属性
a1.sources.r1.type = avro
a1.sources.r1.bind = CentOSA
a1.sources.r1.port = 44444
# 配置拦截器
a1.sources.r1.interceptors = i1
# 正则过滤拦截器
a1.sources.r1.interceptors.i1.type = regex_filter
a1.sources.r1.interceptors.i1.regex = ^\\W*(INFO|ERROR)\\W+.*UserService.*$
# 配置sink属性
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /root/file_roll_1
a1.sinks.k1.sink.rollInterval = 0
a1.sinks.k1.sink.batchSize = 1
a1.sinks.k2.type = file_roll
a1.sinks.k2.sink.directory = /root/file_roll_2
a1.sinks.k2.sink.rollInterval = 0
a1.sinks.k2.sink.batchSize = 1
# 配置channel属性
a1.channels.c1.type = memory
a1.channels.c1.transactionCapacity = 1
# 将source连接channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
为了验证测试,大家需要暂时的将transactionCapacity批处理大小设置为1同时将sink的BatchSize设置为1即可。
异动数据监测
INFO 192.168.0.1 XXXXX xxxxxx xxxxxxx xxxxx
INFO 192.168.0.2 XXXXX xxxxxx xxxxxxx xxxxx
INFO 192.168.0.3 XXXXX xxxxxx xxxxxxx xxxxx
INFO 192.168.0.1 XXXXX xxxxxx xxxxxxx xxxxx
INFO 192.168.0.5 XXXXX xxxxxx xxxxxxx xxxxx
INFO 192.168.0.3 XXXXX xxxxxx xxxxxxx xxxxx
INFO 192.168.1.6 XXXXX xxxxxx xxxxxxx xxxxx
INFO 192.168.2.6 XXXXX xxxxxx xxxxxxx xxxxx
INFO 101.168.2.6 XXXXX xxxxxx xxxxxxx xxxxx
如果系统在一分钟内访问操作100次,就将该IP主机设置到BlackList中
access_topic分区数 3 副本因子 3 -存储用户访问消息shuffle_ip_topic分区数 3 副本因子 3 - 存储IP信息,确保相同IP在同一个分区
public static String parseIP(String line){
//INFO 192.168.0.1 XXXXX xxxxxx xxxxxxx xxxxx
String regex="^\\W*INFO\\W+(\\d{3}\\.\\d{3}\\.\\d{1,3}\\.\\d{1,3})\\W+.*$";
Matcher matcher = Pattern.compile(regex).matcher(line);
if(matcher.matches()) {
return matcher.group(1);
}
return null;
}
public static Boolean isMatch(String line){
String regex="^\\W*INFO\\W+(\\d{3}\\.\\d{3}\\.\\d{1,3}\\.\\d{1,3})\\W+.*$";
return Pattern.compile(regex).matcher(line).matches();
}
Properties props=new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application-3");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "CentOSA:9092,CentOSB:9092,CentOSC:9092");
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG,StreamsConfig.AT_LEAST_ONCE);
props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,10);
props.put(StreamsConfig.STATE_DIR_CONFIG,"C:/kafka-strems-states");
KStreamBuilder builder=new KStreamBuilder();
builder.stream(
Serdes.String(), Serdes.String(),
"access_topic"
).filter((k,v)-> isMatch(v))
.selectKey((k,v) -> parseIP(v))
.mapValues((v) -> 1)
.through(Serdes.String(),Serdes.Integer(),"shuffle_ip_topic")
.groupByKey(Serdes.String(),Serdes.Integer())
.reduce((v1,v2)-> v1+v2, TimeWindows.of(10000).advanceBy(1000))
.toStream()
.filter((k,v)-> v > 10)//表示监控阈值10秒内操作10次属于违规
.foreach((k,v)->{
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Window window = k.window();
System.out.println(k.key()+" -> "+v+"\t"+sdf.format(window.start())+"~"+sdf.format(window.end()));
});
KafkaStreams kafkaStreams=new KafkaStreams(builder,props);
//设置异常处理
kafkaStreams.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.err.println(t.getName()+" "+t.getId()+" err:"+e.getMessage());
kafkaStreams.close();
}
});
//启动流计算
kafkaStreams.start();
更多精彩内容关注
