Flask使用MySQL指南
一、首先进入开场白(场景),几个概念和基础知识:
1、SQLAlchemy,alchemy 单词译为 炼金术、魔力,即表示 SQLAlchemy是个有魔力的东西。
官网:http://www.sqlalchemy.org,百度搜索SQLAlchemy,它的标签是“The Database Toolkit for Python”,译为 Python的数据库工具包。
SQLAlchemy不是数据库,是操作数据库的工具包、是对数据库进行操作的一种框架,简化了数据库管理的操作。也是一个强大的关系型数据库框架。
进入官网第一段话:
The Python SQL Toolkit and Object Relational Mapper
SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that gives application developers the full power and flexibility of SQL.
It provides a full suite of well known enterprise-level persistence patterns, designed for efficient and high-performing database access, adapted into a simple and Pythonic domain language.
译作:SQLAlchemy是Python的SQL工具包和对象关系映射器
1.为应用程序开发者提供SQL的全部操作、灵活性。
2.提供一整套众所周知的企业级持久性模式,专为高效、高性能的数据库访问而设计,适用于简单的、Pythonic领域语言。(Pythonic:机具Python特色的Python代码)
SQLAlchemy设计哲学:
SQL数据库的行为 不像对象集合,而对尺寸、性能开始更重要;对象集合表现得不像表、行,而对抽象更关注。SQLAlchemy的目标是旨在满足这两个原则。即同时关注尺寸、性能 和抽象性。
SQLAlchemy认为数据库是一个关系代数引擎,不只是一组表。行不仅可从表中选择、还可从连接和其他选择语言中选择,任何这些单位可组成一个更大的结构。SQLAlchemy的表达式语言从核心构建此概念。
SQLAlchemy最著名的是它的对象关系映射器(ORM),它是一种提供数据映射器模式的可选模式,其中类可以以开放式、多种方式映射到数据库—-允许对象模型、数据库模式从一开始就干净地解耦。
SQLAlchemy针对这些问题的解决方式完全不同于大多数其他基于面向所谓的面向对齐的方法的SQL/ORM工具;而不是将SQL和对象关系的细节隐藏在自动化墙的后面,所有进程都在一系列可组合的透明工具中完全公开。该库负责自动化冗余任务,同时开发者仍然控制数据库的组织方式、SQL的构建方式。
SQLAlchemy的主要目标是改变你对数据库、SQL的看法!
SQLAlchemy关键特征:
1.No ORM required 译作:不需要ORM? 好像不妥。
SQLAlchemy由两个不同组件构成:Core、ORM。
ORM是一个基于Core构建的可选包。许多应用程序严格按照Core构建,使用SQL表达式系统地为数据库交互提供简洁而精确的控制。
Core本身是一个全功能的SQL抽象工具包,提供对各种DBAPI实现和行为的平滑抽象层、以及允许通过生成式Python表达式表示SQL语言的SQL表达式语言。既可以发出DDL语句也可以反思现有模式的模式来表示系统,以及允许将Python类型映射到数据库类型的类型系统,使系统更加完善。
ORM是一个基于Core构建的可选包。许多应用程序严格按照Core构建,使用SQL表达式系统地为数据库交互提供简洁而精确的控制。
2.成熟、高性能构建
3.认可DBA
4.Non-Opinionated非自以为是
5.Unit Of Work
6.基于功能的查询结构
7.模块化、可扩展
8.独立的映射、类设计
9.相关对象和集合的急切加载和缓存
10.复合(多列)主键
11.自引用对象映射
12.继承映射
13.原生SQL语句映射
14.数据的预处理和后处理
15.支持Python2.5和3.x,还支持Jython/Pypy
16.SQLAlchemy包括用于SQLite,Postgresql,MySQL,Oracle,MS-SQL,Firebird,Sybase等的语言,其中大多数支持多个DBAPI。
SQLAlchemy官方文档
2.Flask-SQLAlchemy 也是一种数据库框架,是一个Flask扩展,它包装了SQLAlchemy,支持多种数据库后台。无须关心SQL处理细节,操作数据库,一个基本关系 对应一个类,而一个实体 对应类的实例对象,通过调用方法操作数据库。
是一个专门为Flask应用增加SQLAlchemy支持的扩展。
中文文档这里写链接内容
所以 SQLAlchemy、Flask-SQLAlchemy两者的关系是:
1)SQLAlchemy是Python的数据库工具包,是一个强大的关系数据库框架,提供高级的ORM、底层访问数据库的本地SQL功能; 2)Flask-SQLAlchemy是Flask为支持SQLAlchemy而设计的一个扩展(插件),简化了Flask应用程序对SQLAlchemy的使用。
即flask-sqlalchemy在sqlalchemy基础上,提供一些常用工具,并预设一些默认值,帮助更轻松地完成常见任务。
flask-sqlalchemy将它的执行上下文绑定在了flask的app的context上。但sqlalchemy本身提供scoped_session,在实际操作中,建议将db的实现、app的context脱离开,注册一下@app.teardown_appcontext,并增加session.remove()语句。
3.ORM Object Relational Mapper 译作 对象关系映射。即将面向对象的方法映射到数据库中的关系对象中。 是一种为了解决 面向对象与关系数据库存在的互不匹配的现象 的技术。
ORM通过使用 描述对象和数据库之间映射的元数据,将程序中的对象 自动持久化到关系数据库中。
如何实现持久化?
采用映射元数据来描述对象关系的映射,使得ORM中间件可在任何一个应用的业务逻辑层、数据库层之间充当桥梁。
倘若一个程序不使用ORM,则会增加不少对数据访问层的代码,用于从数据库中保存、删除、读取对象信息等。ORM解决的是[对象-关系]的映射。域模型、关系模型 分别建立在概念模型的基础上。
域模型 domain model,是融合了行为、数据的域的对象模型。域模型是面向对象的。构成域模型的基本元素 是域对象(domain object 是对真实世界实体的软件抽象)。
关系模型 是面向关系的。
一般情况下:一个持久化类 对应 一个表
类的每个实例 对应 表中一个记录
类的每个属性 对应 表的每个字段
ORM技术特点:
1.提升开发效率。ORM可自动对实体对象 与数据库中的表进行字段和属性的映射。这就不需要一个专用的、庞大的数据访问层。
2.ORM提供了对数据库的映射,不用SQL直接编码,就能够像操作对象一样从数据库获取数据。
ORM主要作用:将数据库领域的东西 映射到面向对象领域,因为开发者更熟悉。开发者更多的是以对象的方式去思考,更熟悉的是user has many topics,而不是row、column、foreign key。
4.操作数据库的几种方式: 1).在数据库命令行直接写SQL语句。即底层操作数据库 2).在Python中可用数据库驱动(以python3.x为例,如pymysql)来操作数据库,驱动对底层繁琐命令进行了封装 3).在Flask中使用SQLAlchemy数据库框架 对数据库驱动进一步封装,进一步简化命令。
5.在Flask中,数据库管理 的步骤:
1)、配置数据库;
3)、数据库的基本操作(命令行中操作): 创建表、插入行、修改行、删除行、查询行
5)、集成Python shell;
6)、flask-migrate实现数据库迁移。
二、具体步骤
1.安装flask-sqlalchemy、pymysql模块:pip install flask-sqlalchemy pymysql 上述安装命令会自动一并安装SQLALchemy模块。
角色:
flask-sqlalchemy—–Flask应用程序中,专门用于管理数据库的。 pymysql—–Python操作MySQL的模块。它包含一个纯Python MySQL客户端库。
2.测试连接数据库
2.1使用Flask-SQLAlchemy管理数据库
三种最受欢迎的数据库引擎url格式:
| 数据库引擎 | URL |
|---|---|
| MySQL | mysql://usename:password@hostname/database |
| SQLite | sqlite:///c:/absolute/path/to/database |
| PostgerSQL | postgresql://username:password@hostname/database |
上述url中,hostname指托管MySQL服务的服务器,如本地(localhost)、或远程服务器。数据库服务器可托管多个数据库,故database指出要使用的数据库名。数据库需身份验证,username、password正是数据库用户凭证。
PS:SQLite没有服务,故hostname、username、password可缺省,且数据库是一个磁盘文件名。
MySQL格式如:
dialect+driver://username:password@host:port/database?charset=utf8
mysql+pymysql://数据库用户名(如root):密码@127.0.0.1:3306/数据库名?utf8mb4(或?charset=utf-8或?utf8)
其中dialect 指数据库的实现,如MySQL/SQLite等,并全换为小写
driver 指Python对应的驱动,若不指定,则会选择默认的驱动。
如在Python3.x中,MySQL默认驱动是pymysql。
username 指连接数据库的用户名
password 指连接数据库的密码
host 指连接数据库的域名
port 指数据库监听的端口号
database 指连接哪个数据库的名字
代码:
from flask-sqlalchemy import SQLALchemy
from flask import Flask
app = Flask(__name__)
'''配置数据库'''
app.config['SECRET_KEY'] = 'hard to guess'#一个字符串,密码。也可以是其他如加密过的
#在此登录的是root用户,要填上密码如123456,MySQL默认端口是3306。并填上创建的数据库名如youcaihua
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:[email protected]:3306/youcaihua'
#设置下方这行code后,在每次请求结束后会自动提交数据库中的变动
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
db = SQLAlchemy(app)#实例化数据库对象,它提供访问Flask-SQLAlchemy的所有功能关于用SQLAlchemy管理MySQL数据库的官方文档:
http://docs.sqlalchemy.org/en/latest/dialects/mysql.html
2.2模型定义
模型 指应用程序使用的持久化实体。而在表中相当于定义了一个表头。
在ORM背景下,一个模型 通常是一个带有属性的Python类,其属性与数据库表中的列匹配对应。Flask-SQLAlchemy数据库实例 提供了一个基类、一组辅助类 和函数用于定义它的结构。
参考文档:
http://www.pythondoc.com/flask-sqlalchemy/models.html
代码:
'''定义模型,建立关系'''
class Role(db.Model):#所有模型的基类叫 db.Model,它存储在创建的SQLAlchemy实例上。
#定义表名
__tablename__ = 'roles'
#定义对象
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
user = db.relationship('User', backref='role')
#__repr__()方法显示一个可读字符串,虽然不是完全必要,不过用于调试、测试是很不错的。
def __repr__(self):
return '' .format(self.name)
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
def __repr__(self):
return '' .format(self.name)
__tablename__类变量 定义数据库中表的名称。若这个变量缺省,则Flask-SQLAlchemy会指定默认的表名,但缺省名称不遵守使用复数命名的约定。因此,最好是显示命名 表名。
其余变量 是模型的属性,被定义为db.Column类 的实例。
传给db.Column类的构造函数的第一个参数 是数据库列的类型,即模型属性的数据类型。
下图列出 一些常用的 数据库列的类型(SQLAlchemy列类型),对应于模型中的Python数据类型。
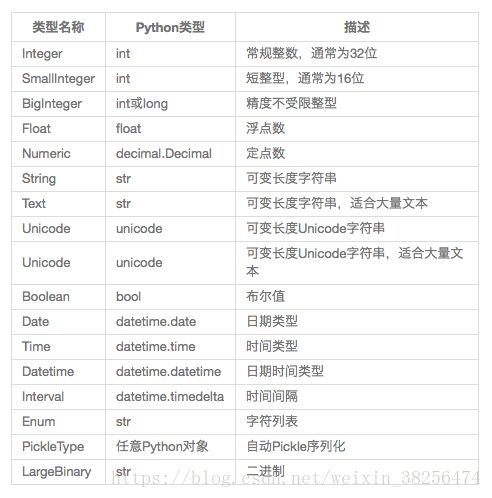
传给db.Column类的构造函数 剩余的参数为每个属性指定了配置选项,下图列出了SQLAlchemy列 可用的选项:

2.3关系
关系型数据库 通过使用关系 在不同的表中建立连接。2.2中的对应关系图清楚地表达了用户、用户角色之间的简单关系。角色、用户 是一对多的关系。而一个用户只能拥有一个角色。
模型类的定义中展示了 所表达的一对多关系,代码如下:
class Role(db.Model):
...
users = db.relationship('User', backref='role')
class User(db.Model):
...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))关系 通过用 外键来连接两行。
添加给User模型的role_id列 被定义为 外键。且建立关系。db.ForeignKey()的参数role.id指定的列 是roles表的持有id值的列。
添加给Role模型的users属性 表现了关系的面向对象的观点。给Role类的实例,users属性会返回一组连接到该角色的用户。指定给db.relationship()的第一个参数表明模型中关系的另一边。如果类还未定义,这个模型可作为字符串提供。
从SQLAlchemy源码中可知,ForeignKey类 的column接收三种类型的参数:’模型名.属性名’、’表名.列名’、[未知]
db.relationship()的backref参数通过给User模型增加role属性来定义反向关系。这个属性可替代role_id访问Role模型,是作为对象而不是外键。
大多数情况下 db.relationship()可定位自己的外键关系,但有时不能确定哪个列被用作外键。例如:若User模型有两个 或更多的列被定义为Role的外键,SQLAlchemy将不知道使用两个中的哪一个了。每当外键配置模棱两可时,就必须使用额外参数在db.relationship()中,下方图片列出常用配置选项用于定义关系:

2.4数据库操作
代码:
'''进行数据库操作'''
if __name__ == '__main__':
#删除旧表
db.drop_all()
db.create_all()#创建新表
#给Role表,插入数据,3种角色
admin_role = Role(name='Admin')
mod_role = Role(name='Moderator')
user_role = Role(name='User')
#role属性也可使用,虽然它不是真正的数据序列,但却是一对多关系的高级表示。给User表插入3条数据
user_john = User(username='john', role=admin_role)
user_susan = User(username='susan', role=user_role)
suer_david = User(username='david', role=user_role)
#在将对象写入数据库之前,先将其添加到会话中,数据库会话db.session和Flask session对象没有关系,数据库会话也称 事物 译作Database Transaction。
db.session.add_all([admin_role, mod_role, user_role, user_john, user_susan, user_david])
#提交会话到数据库
db.session.commit()
#修改roles名
admin_role.name = 'Administrator'
db.session.add(admin_role)
db.session.commit()
#删除数据库会话,从数据库中删除“Moderator”角色
db.session.delete(mod_role)
db.session.commit()#注意:删除 和插入、更新一样,都是在数据库会话提交后执行
#查询
print(user_role)
print(User.query.filter_by(role=user_role.all())过滤器如filter_by()通过query对象来调用,且返回经过提炼后的query。多个过滤器可依次调用直到需要的查询配置结束为止。查询中常用的过滤器:


在需要的过滤器已全部运用于query后,调用all()会触发query执行并返回一组结果,但是除了all()以外还有其他方式可触发执行。如下图,用预览观看:常用SQLAlchemy查询执行器
image
2.5执行
python app.py查看数据库,可以看到数据已写入了。