Python 3.X | Regular Expression(正则表达式)
Python 3.6.3、Windows 10
“我知道 可以使用正则表达式来解决这个问题”。于是,现在“我”就有了两个问题需要解答了:
- 正则表达式本身就是一个难题,但非常有用。
- 原问题。
一、理论篇
1、起源

正则表达式 起源于上图4位美国大佬:
- 1943年,Warren McCulloch和Walter Pitts研究出一种用数学方法来描述神经网络的新方法;
- 1956年,Stephen Cole Kleene基于前两位大佬的基础上发表《神经网事件的表示法》论文,文中引入正则表达式的概念,用于描述作者称为“正则集的代数”的表达式,因而采用正则表达式这个术语;
- Ken Thompson将成果应用于计算搜索算法的一些早期研究,即第一次将正则表达式应用到Unix QED编辑器中。
随之,由于正则表达式强大的文本处理能力,很快被广泛应用于Perl、PHP、JavaScript、JAVA、Python、Ruby等语言和开发环境中。
2、概念和原理简介
正则表达式(又称 规则表达式)是用来描述字符串特定结构(规则)的语言(即 本身就是一种小型的、高度专业化的编程语言),由相关引擎执行。
在Python中,通过内嵌集成re模块,可直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后经由C编写的匹配引擎执行。
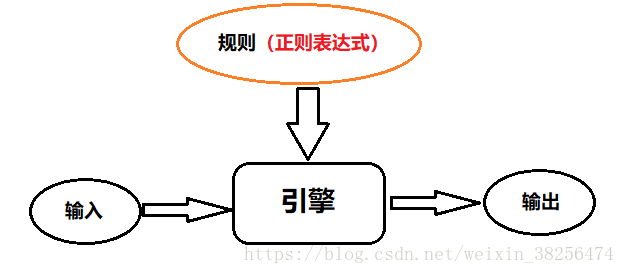
正则表达式是一种特殊的字符串模式,用于匹配一组字符串。运用给定的组成规则和字符来匹配表达式。
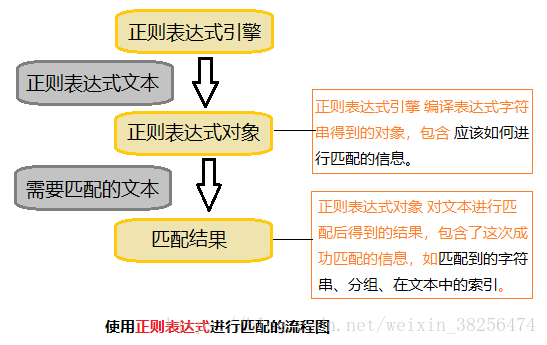
3、作用
通常被用来检索、替换那些符合某个模式(规则)的文本。
- 数据验证(测试字符串内的模式):测试输入的字符串 是否符合一定的规则、是否允许输入等。例如可测试输入的字符串,以查看字符串内是否出现电话号码模式、信用卡号码模式、IP地址模式等;对Email地址合法性、出生年月日等进行验证。
- 操作文本:使用正则表达式识别文档中的特定文本,完全删除该文本或用其他文本替换掉。
- 基于模式匹配从字符串中提取子字符串:查找文档内、或输入域内特定的文本。
4、基础语法(规则)
前情提要:
- 字符串 是编程中涉及到的最多的一种数据结构,对字符串进行操作的需求无处不在。
正则表达式的匹配(操作)对象 是字符串,而不是其他类型的内容。 - 要搜索的模式 和字符串 可以是Unicode字符串(str)或8位字符串(字节)。但是,不可将Unicode字符串与字节模式匹配,反之亦然。即 类型必须相同。
- 反斜杠
\的困扰:正则表达式使用反斜杠字符\作为转义字符。这可能会产生一些冲突,例:需要匹配文本中的字符\,那么使用编程语言表示的正则表达式里将需要4个反斜杠\\\\:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。解决方案是使用Raw String(原始字符串),它是未经过特殊处理的字符串,如转义序列。如果需要去指定原始字符串,则只需在其前面加r或R即可:例中的正则表达式可使用r"\\"表示。同样,匹配一个数字的\\d可以写成r"\d"。r"Newlines are indicated by \n"。在正则表达式中,应全程使用原始字符串。否则将会有大量Backwhacking需要处理。 - 正则表达式可以连接起来形成新的正则表达式。例如
A、B都是正则表达式,则AB也是正则表达式。即一个字符串p匹配A,字符串q匹配B,则字符串pq匹配AB。 - 数量词的贪婪模式与非贪婪模式:Python中数量词默认是贪婪的,总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。例:正则表达式
ab*如果用于查找abbbc,将找到abbb;而如果使用非贪婪的数量词ab*?,将找到a。 - 匹配模式:正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在
Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
Python 3.X 支持的正则表达式 元字符和语法:
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| 字符 | |||
| 字母、数字 | 匹配自身 | abc | abc |
. |
点号,匹配任意除换行符(\n)外的字符(在DOTALL模式中也能匹配换行符) | a.c | abc |
\ |
转义字符,使后一个字符改变原来的意思。如果字符串中有字符*需要匹配,可使用\* 或字符集[*]。 | a\.c a\\c |
a.c a\c |
[...] |
字符集(字符类)。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。第一个字符如果是^,则表示取反,如[^abc]表示不是abc的其他字符,即非abc。所有的特殊字符在字符集中都失去其原有的特殊含义。在字符集中如果要使用]、-或^,可以在前面加上反斜杠,或把]、-放置第一个字符,把^放在非第一个字符。 | a[bcd]e | abe ace ade |
| 预定义字符集(可以写在字符集[...]中) | |||
\d |
数字:[0-9] | a\dc | a1c |
\D |
非数字:[^\d] | a\Dc | abc |
\s |
空白字符:[<空格>\t\r\n\f\v] | a\sc | a c |
\S |
非空白字符:[^\s] | a\Sc | abc |
\w |
单词字符:[A-Za-z0-9] | a\wc | abc |
\W |
非单词字符:[^\w] | a\Wc | a c |
| 数量词(用在字符或(...)之后) | |||
* |
匹配前一个字符0次或无限次 | abc* | ab abccc |
+ |
匹配前一个字符1次或无限次 | abc+ | abc abccc |
? |
匹配前一个字符0次或1次 | abc? | ab abc |
{m} |
匹配前一个字符m次 | ab{2}c | abbc |
{m,n} |
匹配前一个字符m至n次。 m和n可以省略:若省略m,则匹配0至n次;若省略n,则匹配m至无限次。 |
ab{1,2}c | abc abbc |
*?;+?;??;{m,n}? |
使* + ? {m,n}变成非贪婪模式。 | 示例将在下文中介绍。 | |
| 边界匹配(不消耗待匹配字符串中的字符) | |||
^ |
匹配字符串开头。 在多行模式中匹配每一行的开头。 |
^abc | abc |
$ |
匹配字符串末尾 或刚好在字符串末尾的新行之前。 在多行模式中匹配每一行的末尾。 |
abc$ | abc |
\A |
仅匹配字符串开头。 | \Aabc | abc |
\Z |
仅匹配字符串末尾。 | abc\Z | abc |
\b |
匹配\w和\W之间 | a\b!bc | a!bc |
\B |
[^\b] | a\Bbc | abc |
| 逻辑、分组 | |||
| |
或。匹配 | 左右表达式任意一个,从左到右匹配。 它总是先尝试匹配左边的表达式,一旦成功匹配则跳过匹配右边的表达式。 如果 | 没有包括在()中,则它的范围是整个正则表达式 |
abc|def | abc def |
(...) |
被括起来的表达式将作为分组,从表达式左边开始每遇到一个分组的左括号"(",编号就+1。另外, 分组表达式作为一个整体,可以后接数量词。表达式中的 | 仅在该组中有效。 |
(abc){2} a(123|456)c |
abcabc a456c |
(?P<name>...) |
分组,除了原有的编号外,再指定一个额外的别名。这和分组差不多(下同),这是命名分组。例:要匹配两个相同的字符,即(\w)\1。其中,\1是对(\w)的引用(即下方的 编号分组),不过这样有个弊端(如分组很多、或有嵌套时),不易分清\n引用的哪个分组。命名分组就很直观明了,例改为:(?P<word>\w)(?P=word) |
(?P<id>abc){2} |
abcabc |
\<number> |
引用编号为<number>的分组 匹配到的字符串。 |
(\d)abc\1 | 1abc1 5abc5 |
(?P=name) |
引用别名为<name>的分组 匹配到的字符串。 |
(?P<id>\d)abc(?P=id) |
1abc1 5abc5 |
| 特殊构造(不作为分组) | |||
(?:...) |
(...)的不分组版本,用于使用“|”或后接数量词 | (?:abc){2} | abcabc |
(?aiLmsux) |
aiLmsux的每个字符代表一个匹配模式,只能用在正则表达式的开头,可选多个。匹配模式将在下文中介绍。 | (?i)abc | AbC |
(?imsx-imsx:...) |
imsx的每个字符代表一个匹配模式。如:Re.i(忽略);R.m(多行);Re.S(. 匹配所有);Re.X(verbose),用于表达式的一部分。 | Python 3.6 新增。示例将在下文中介绍。 | |
(?#...) |
#后的内容将作为注释被忽略。 | abc(?#comment)123 | abc123 |
(?=...) |
之后的字符串内容需要匹配表达式才能成功匹配。不消耗字符串内容。 | a(?=\d) | 后面是数字的a |
(?!...) |
之后的字符串内容需要不匹配表达式才能成功匹配。不消耗字符串内容。 | a(?!\d) | 后面不是数字的a |
(?<=...) |
之前的字符串内容需要匹配表达式才能成功匹配。不消耗字符串内容。 | (?<=\d)a | 前面是数字的a |
(? |
之前的字符串内容需要不匹配表达式才能成功匹配。不消耗字符串内容。 | (? | 前面不是数字的a |
(?(id/name)yes-pattern|no-pattern) |
如果编号为id/别名为name的组匹配到字符串,则需要匹配yes-pattern,否则需要匹配no-pattern。|no-pattern可省略。 | (\d)abc(?(1)\d|abc) | 1abc2 abcabc |
二、Python正则表达式 | 实践篇:re模块详解
Python通过 re模块实现正则表达式。使用 re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例;然后使用Pattern实例处理文本并获得匹配结果(一个Match实例);最后使用Match实例获得信息,进行其他操作。
1、re模块定义的几个函数、常量、异常:
在Python 3.6以上版本,Flag常量现在是RegexFlag(它是enum.IntFlag的子类)的实例。
1.1、re.compile(pattern[, flags=0])
它是Pattern类的工厂方法,将字符串形式的正则表达式模式 编译成正则表达式对象(Pattern对象),可以使用正则表达式对象的match()、search()、和其他方法进行匹配(下一节讲述)。
其中,第二个参数flags 是匹配模式,取值可使用按位或运算符 | 表示同时生效,比如re.I | re.M。另外,也可在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
flags 可选值有:
| 名称 | 说明 |
|---|---|
re.A(re.ASCII) |
使 \w、\W、\b、\B、\d、\D、\s、\S只执行ASCII匹配,而不是完整的Unicode匹配。PS:为了向后兼容,re.U标志仍然存在(以及re.Unicode 和(?u))。但在Python 3中,这些是多余的,因为默认情况下,字符串的匹配是Unicode(字节不允许Unicode匹配)。 |
re.DEBUG |
显示有关编译表达式的调试信息 |
re.I(re.IGNORECASE) |
执行不区分大小写的匹配。如:表达式[A-Z]将匹配小写字母。 |
re.L(re.LOCALE) |
使预定字符类 \w、 \W、 \b 、\B 取决于当前区域设定。PS:Python 3.6以上,re.LOCALE只用于字节模式,与re.ASCII不兼容。 |
re.M(re.MULTILINE) |
多行模式,改变 ^和$的行为。 |
re.S(re.DOTALL) |
点任意匹配模式,改变 . 行为。 |
re.X(re.VERBOSE) |
详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。 |
关于re.VERBOSE,以下两个正则表达式是等价的:
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""", re.X)
b = re.compile(r"\d+\.\d*")
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
m = re.match(r'hello', 'hello world!')
print(m.group())
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
1.2、re.search(pattern, string, flags=0)
扫描字符串,查找正则表达式模式产生匹配的第一个位置,并返回相应的匹配对象。如果字符串中没有位置与模式匹配,则返回None;注意,这跟查找字符串中某个点的零长度匹配不同。
1.3、re.match(pattern, string, flags=0)
如果字符串开头的0个 或多个字符 与正则表达式模式匹配,则返回相应的匹配对象。如果字符串与模式不匹配,则返回None;注意,这跟0长度匹配不同。
PS:即使在MULTILINE模式下,re.match()将只在字符串的开始匹配,而不是在每行的开头匹配。
如果想在字符串中的任何位置找到匹配项,则使用search()。
1.4、re.fullmatch(pattern, string, flags=0)
Python 3.4新增的。
如果整个字符串与正则表达式模式匹配,则返回相应的匹配对象。
如果字符串与模式不匹配,则返回None;注意,这也与0长度匹配不同。
1.5、re.split(pattern, string, maxsplit=0, flags=0)
通过正则表达式将字符串分割(正则表达式作为分割符)。如果用括号将正则表达式括起来,那么匹配的字符串也会被列出到list中返回。参数 maxsplit是分割的次数,默认为0;在非0时,最多发生maxsplit次拆分,并且字符串的其余部分作为列表的最后元素返回。参数flags在Python 3.1增加的;
C:\Users\Administrator>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.split(r"\W+", "Words,words,words.")#用r"\W+"匹配1次或多次非单词字符,并将它作为分割字符串的模式。. 也算,所以它后面是空字符。
['Words', 'words', 'words', '']
>>> re.split(r"(\W+)", "Words,words,words.")#匹配的字符串也出现在列表中
['Words', ',', 'words', ',', 'words', '.', '']
>>> re.split(r"\W+", "Words,words,words.", 1)#分割1次
['Words', 'words,words.']
>>> re.split("[a-f]+", "0a3B9", flags=re.IGNORECASE)#匹配模式忽略大小写,以字母作为分割字符串的模式。结果是得到分割的数字。
['0', '3', '9']
如果分割符用括号括起(分组捕获)且它正好匹配到字符串的开头,得出的结果将以空字符串开头。同样适用于结尾。
>>> re.split(r'(\W+)', '...words, words...')
['', '...', 'words', ', ', 'words', '...', '']
这样,分隔符组件总是在结果列表中找到相同的相对索引。
PS:split()不会用一个空模式匹配去分割一个字符串。例:即使'x*'可以匹配到 0个'x',但不会返回这个结果['', 'a', 'b', 'c', '']。例子正确的结果是匹配到1个'x'。
>>> re.split('x*', 'axbc')
['a', 'bc']
在Python3.5中,如果匹配模式为空,那么将引发ValueError:
>>> re.split("^$", "foo\n\nbar\n", flags=re.M)
Traceback (most recent call last):
File "", line 1, in
...
ValueError: split() requires a non-empty pattern match.
1.6、re.findall(pattern, string, flags=0)
以列表形式返回字符串中所有非重叠的匹配模式。字符串从左到右扫描,并按找到的顺序返回匹配项。如果模式中存在一个或多个组,则返回组列表;如果模式有多个组,则返回元组列表。结果中包含空匹配。
>>>findall(r'^|\w+', 'two words')
['', 'wo', 'words']
PS:由于当前实现的限制,空匹配后面的字符不包括在下一个匹配中。因此,上述结果中没有“t”。这在Python 3.7改了。
正则表达式 r'^|\w+'表示匹配空字符串开头 或 单词字符开头。| 从左到右进行匹配,一旦左边匹配成功,就会跳过右边表达式匹配。
1.7、re.finditer(pattern, string, flags=0)
返回一个迭代器,它在字符串中的RE模式的所有非重叠匹配中产生匹配对象。字符串从左到右扫描,并按找到的顺序返回匹配项。结果中包含空匹配。可参考findall()。
1.8、re.sub(pattern, repl, string, count=0, flags=0)
sub,substitute缩写,译作 替换。
利用正则表达式,实现比普通字符串的replace更加强大的替换功能。
pattern,表示正则表达式的模式字符串,可以是一个字符串或一个pattern对象;若pattern未提供,则将返回原字符串。
repl,可以是一个字符串或一个函数。
如果是一个字符串,则将处理其中任何一个反斜杠 \ 转义,也就是说 \n 转换为单个换行符、\r转换为回车符等,对于未知的转义 如 \&将识别为它本身,而反向引用(如\6)表示匹配pattern的第6个group。
PS:pattern若由\ 和ASCII字母组成的未知转义,将会error。
>>> re.sub(r'def\s+([a-zA-Z_][a-zA-Z_0-9]*)\s*\(\s*\):', r'static PyObject*\npy_\1(void)\n{', 'def myfunc():')
'static PyObject*\npy_myfunc(void)\n{'
如果repl是一个函数,举例:
>>> def dashrepl(matchobj):
... if matchobj.group(0) == '-': return ' '
... else: return '-'
>>> re.sub('-{1,2}', dashrepl, 'pro----gram-files')
'pro--gram files'
>>> re.sub(r'\sAND\s', ' & ', 'Baked Beans And Spam', flags=re.IGNORECASE)
'Baked Beans & Spam'
count,替换的最大次数。
1.9、re.subn(pattern, repl, string, count=0, flags=0)
执行操作和sub()相似,但返回一个元组(new_string, number_of_subs_made)。包括新字符串、替换次数。
1.10、re.escape(pattern)
转义pattern中所有字符,但ASCII字母、数字、‘_’除外。如果想匹配一个其中包含正则表达式元字符的字符串,这将非常有用。
>>> print(re.escape('python.exe'))
python\.exe
>>> legal_chars = string.ascii_lowercase + string.digits + "!#$%&'*+-.^_`|~:"
>>> print('[%s]+' % re.escape(legal_chars))
[abcdefghijklmnopqrstuvwxyz0123456789\!\#\$\%\&\'\*\+\-\.\^_\`\|\~\:]+
>>> operators = ['+', '-', '*', '/', '**']
>>> print('|'.join(map(re.escape, sorted(operators, reverse=True))))
\/|\-|\+|\*\*|\*
这个函数不可用在sub()、subn()替换字符串中,只有反斜杠被转义。例:
>>> digits_re = r'\d+'
>>> sample = '/usr/sbin/sendmail - 0 errors, 12 warnings'
>>> print(re.sub(digits_re, digits_re.replace('\\', r'\\'), sample))
/usr/sbin/sendmail - \d+ errors, \d+ warnings
1.11、re.purge()
purge,译作 清除、净化。
清理正则表达式缓存。
1.12、异常 re.error(msg, pattern=None, pos=None)
当传递给函数之一的字符串 不是有效的正则表达式、或在编译或匹配期间发生其他错误时,引发的异常。
re.error()实例的属性有:msg、pattern、pos、lineno、colno。
2、正则表达式对象 pattern
正则表达式编译后的对象(regular expression object)支持如下方法和属性:
2.1、regex.search(string[, pos[, endpos]])
扫描字符串查找出正则表达式产生匹配的第一个位置,并返回一个对应的match对象。假如在字符串中没有匹配到pattern的位置,则返回None;不过这跟在字符串中某个点找到0长度匹配不同。
参数 pos,是可选的,表示搜索的开始索引,默认是0。这不同于字符串切片。'^'模式字符 在字符串的真正开始处、换行符之后的位置匹配,但不一定在搜索开始的索引处匹配。
参数endpos,也是可选的,限制了搜索字符串的距离;若endpos是字符串的长度,那么将只搜索从pos到endpos-1的字符进行匹配;若endpos<pos,则找不到匹配;另外,若rx是编译后的正则表达式对象,那么rx.search(string, 0, 50) 等价于rx.search(string[:50], 0)。
>>> pattern = re.compile("d")
>>> pattern.search("dog") # Match at index 0
<_sre.SRE_Match object; span=(0, 1), match='d'>
>>> pattern.search("dog", 1) # No match; search doesn't include the "d"
2.2、regex.match(string[, pos[, endpos]])
假如在string的开头匹配到这个正则表达式的0个或多字符,将返回一个对应的match对象。假如没有匹配到,返回None。
可选参数pos、endpos参照regex.search()。
>>> pattern = re.compile("o")
>>> pattern.match("dog") # No match as "o" is not at the start of "dog".
>>> pattern.match("dog", 1) # Match as "o" is the 2nd character of "dog".
<_sre.SRE_Match object; span=(1, 2), match='o'>
search() VS match()区别:
re.match()检查的只是字符串的开头;
re.search()检查的是字符串的任何位置。
>>> re.match("c", "abcdef") # No match
>>> re.search("c", "abcdef") # Match
<_sre.SRE_Match object; span=(2, 3), match='c'>
正则表达式 以'^'开头用到search()中,将会严格匹配到字符串的开头位置:
>>> re.match("c", "abcdef") # No match
>>> re.search("^c", "abcdef") # No match
>>> re.search("^a", "abcdef") # Match
<_sre.SRE_Match object; span=(0, 1), match='a'>
2.3、regex.fullmatch(string[, pos[, endpos]])这是Python 3.4新增的。
如果整个字符串与正则表达式匹配,则返回对应的match对象;否则,返回None。
>>> pattern = re.compile("o[gh]")
>>> pattern.fullmatch("dog") # No match as "o" is not at the start of "dog".
>>> pattern.fullmatch("ogre") # No match as not the full string matches.
>>> pattern.fullmatch("doggie", 1, 3) # Matches within given limits.
<_sre.SRE_Match object; span=(1, 3), match='og'>
2.4、regex.split(string, maxsplit=0)
使用了编译后的pattern后,与re.spilt()相同。
2.5、regex.findall(string[, pos[, endpos]])
使用了编译后的pattern后,与re.findall()相似。加上pos、endpos参数,就跟re.search()相似了。
2.6、regex.finditer(string[, pos[, endpos]])
使用了编译后的pattern后,与re.finditer()相似。加上pos、endpos参数,就跟re.search()相似了。
2.7、regex.sub(repl, string, count=0)
使用了编译后的pattern后,与re.sub()相同。
2.8、regex.subn(repl, string, count=0)
使用了编译后的pattern后,与re.subn()相同。
2.9、regex.flags
这是正则表达式匹配的标志。是提供给compile()的标志组合,(?..)在pattern中的内联标志;假如pattern是Unicode字符串,则是隐式标志(如 UNICODE)。
2.10、regex.groups
在pattern中捕获的group序号。
2.11、regex.groupindex
2.12、regex.pattern
编译了的RE对象的pattern字符串。
3、匹配对象
Match对象支持如下方法和属性:
3.1、match.expand(template)
返回一个字符串,它是通过在字符串模板做反斜杠替换取得的,如同sub()方法。诸如\n之类的转义被转换为适当的字符,且数字反向引用(如 \1,\2)、命名反向引用(\g<1>,\g)被相应group的内容替换。
Python 3.5更改了:未匹配到的group将以空字符串替换。
3.2、match.group([group1, ...])
返回一个或多个匹配的子组。
>>> m = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist")
>>> m.group(0) # The entire match
'Isaac Newton'
>>> m.group(1) # The first parenthesized subgroup.
'Isaac'
>>> m.group(2) # The second parenthesized subgroup.
'Newton'
>>> m.group(1, 2) # Multiple arguments give us a tuple.
('Isaac', 'Newton')
>>> m = re.match(r"(?P\w+) (?P\w+)", "Malcolm Reynolds")
>>> m.group('first_name')
'Malcolm'
>>> m.group('last_name')
'Reynolds'
>> m.group(1)
'Malcolm'
>>> m.group(2)
'Reynolds'
>>> m = re.match(r"(..)+", "a1b2c3") # Matches 3 times.
>>> m.group(1) # Returns only the last match.
'c3'
3.3、match.__getitem__(g):这是Python 3.6新增的。
它等同于m.group(g)。它更容易从匹配中访问单个group。
>>> m = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist")
>>> m[0] # The entire match
'Isaac Newton'
>>> m[1] # The first parenthesized subgroup.
'Isaac'
>>> m[2] # The second parenthesized subgroup.
'Newton'
3.4、match.groups(default=None)
返回一个包含匹配的所有子组的元组。
>>> m = re.match(r"(\d+)\.(\d+)", "24.1632")
>>> m.groups()
('24', '1632')
>>> m = re.match(r"(\d+)\.?(\d+)?", "24")
>>> m.groups() # Second group defaults to None.
('24', None)
>>> m.groups('0') # Now, the second group defaults to '0'.
('24', '0')
3.5、match.groupdict(default=None)
返回一个包含匹配到的所有命名子组的字典。
>>> m = re.match(r"(?P\w+) (?P\w+)", "Malcolm Reynolds")
>>> m.groupdict()
{'first_name': 'Malcolm', 'last_name': 'Reynolds'}
3.6、match.start([group])和match.end([group])
返回由group匹配的子字符串的开始、结束的索引。
>>> email = "tony@tiremove_thisger.net"
>>> m = re.search("remove_this", email)
>>> email[:m.start()] + email[m.end():]
'[email protected]'
3.7、match.span([group])
对于一个match m,返回一个元组(m.start(group), m.end(group))。
3.8、match.pos和match.endpos
pos和endpos的值 正是传递给regex对象的方法search()或match()的。
3.9、match.lastindex
得到最后一个匹配的捕获的group的索引。没有的话,则是None。
3.10、match.lastgroup
得到最后一个匹配的捕获的group的名字。没有则返回None。
3.11、match.re
match()或search()方法产生的match实例的正则表达式对象。
3.12、match.string
取得传递给match()或search()方法的string。
4、正则表达式 官方示例
扑克牌找对子
玩家手中有5张扑克牌,分别对应5个字符,那么5张牌就是一个包含5个字符的字符串。其中,a表示王;k表示国王;q表示女王;j表示杰克;t表示10;2-9表示本身的值。
首先、用一个helper function优雅地显示匹配对象:
def displaymatch(match):
if match is None:
return None
return '' % (match.group(), match.groups())
其次,检查手中的牌是否有效:
>>> valid = re.compile(r"^[a2-9tjqk]{5}$")
>>> displaymatch(valid.match("akt5q")) # Valid.
""
>>> displaymatch(valid.match("akt5e")) # Invalid.
>>> displaymatch(valid.match("akt")) # Invalid.
>>> displaymatch(valid.match("727ak")) # Valid.
""
然后,检查手中牌是否有对子:
>>> pair = re.compile(r".*(.).*\1")
>>> displaymatch(pair.match("717ak")) # Pair of 7s.
""
>>> displaymatch(pair.match("718ak")) # No pairs.
>>> displaymatch(pair.match("354aa")) # Pair of aces.
""
最后,找出对子是啥:
>>> pair.match("717ak").group(1)
'7'
# Error because re.match() returns None, which doesn't have a group() method:
>>> pair.match("718ak").group(1)
Traceback (most recent call last):
File "", line 1, in
re.match(r".*(.).*\1", "718ak").group(1)
AttributeError: 'NoneType' object has no attribute 'group'
>>> pair.match("354aa").group(1)
'a'
参考:
Python 3.6 官方文档----re模块