python数据清洗(二)
第二部分整理数据进行分析
1、识别整洁的数据
要使数据整洁,它必须具有:
(1)每个变量作为单独的列。
(2)每行作为单独的观察。
作为数据科学家,将遇到以各种不同方式表示的数据,因此在看到数据时能够识别整洁(或不整洁)数据非常重要。
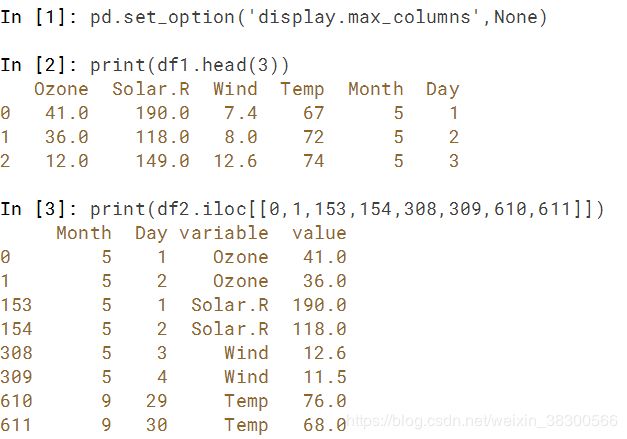
请注意,df2的变量列包含值Solar.R,Ozone,Temp和Wind。为了使它整洁,这些应该都在单独的列中,如df1中所示。
2、使用melt重塑数据
Melting data是将数据列转换为数据行的过程。 考虑上面的DataFrame。 在df1的DataFrame中,变量Ozone,Solar.R,Wind和Temp都有自己的列。 但是,如果希望这些变量在行中,则可以melt DataFrame。 但是,这样做会使数据不整齐! 记住这一点非常重要:根据数据的表示方式,必须以不同方式对其进行重新整形(例如,这可以使绘制值更容易)。
pd.melt()应该注意两个参数:id_vars和value_vars。
id_vars表示不想融化的数据列(即,保持其当前形状),而value_vars表示希望融入行的列。 默认情况下,如果未提供value_vars,则未在id_vars中设置的所有列都将被熔化。
下面的代码将df1结构通过pd.melt()函数转换为df2结构。
#显示全部列
pd.set_option('display.max_columns',None)
# Print the head of airquality
print(airquality.head())
# Melt airquality: airquality_melt
airquality_melt = pd.melt(airquality, id_vars=['Month', 'Day'])
# Print the head of airquality_melt
print(airquality_melt.head()) 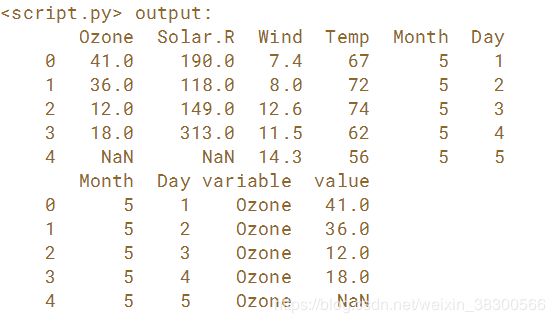
这个方法将整洁的数据进行融合。 此练习演示了如果你想要数据整洁,融合DataFrame并不总是合适的。 你可能需要执行其他转换,这取决于数据的具体表示方式。
This exercise demonstrates that melting a DataFrame is not always appropriate if you want to make it tidy. You may have to perform other transformations depending on how your data is represented.
自定义melted数据
在融合DataFrames时,可以命名几个有意义的名称,(pd.melt()使用的默认名称)。默认名称可能在某些情况下有效,但最好始终拥有可自我解释的数据。可以通过指定var_name的参数来重命名变量列,并通过指定value_name的参数来重命名值列。
# Print the head of airquality
print(airquality.head())
# Melt airquality: airquality_melt
airquality_melt = pd.melt(airquality, id_vars=['Month', 'Day'], var_name='measurement', value_name='reading')
# Print the head of airquality_melt
print(airquality_melt.head()) 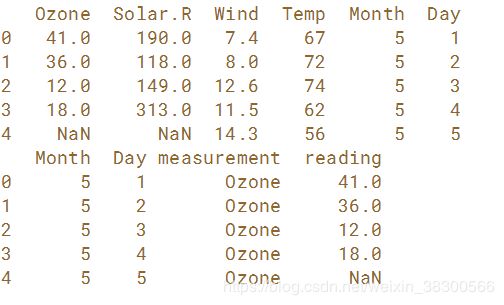
与上一个例子相比将,默认的变量Varible和value变成了 measureme和reading。
4、Pivot透视数据
透视数据与融化数据相反。 还记得Airquality DataFrame融化之前所处的整洁形式吗?使用.pivot_table()方法将融合数据重新转换回清洁数据,即将df2转化为df1.
虽然melt需要一组列并将其转换为单个列,但Pivot将为指定列中的每个唯一值创建一个新列。
.pivot_table()有一个index参数,可用于指定不需要透视的列:它类似于pd.melt()的id_vars参数。
必须指定的另外两个参数是columns(要透视的列的名称)和values(透视列时要使用的值)。
# Print the head of airquality_melt
print(airquality_melt.head())
# Pivot airquality_melt: airquality_pivot
airquality_pivot = airquality_melt.pivot_table(index=['Month', 'Day'], columns='measurement', values='reading')
# Print the head of airquality_pivot
print(airquality_pivot.head())
可以看到透视的DataFrame实际上看起来不像原始DataFrame。 接下来,要把此Pivot的DataFrame重新转换为其原始形式。
5、重置DataFrame的索引
在上一个练习中透视airquality_melt之后,没有完全恢复原始DataFrame。得到的是一个带有分层索引的pandas DataFrame(也称为MultiIndex)。在使用pandas操作DataFrames时,深入介绍了层次索引。 实质上,它们允许按照另一个变量对列或行进行分组 - 在本例中,按“月”和“日”。可以使用一种非常简单的方法从枢轴化的DataFrame中恢复原始DataFrame:.reset_index()。
# Print the index of airquality_pivot
print(airquality_pivot.index)
# Reset the index of airquality_pivot: airquality_pivot_reset
airquality_pivot_reset = airquality_pivot.reset_index()
# Print the new index of airquality_pivot_reset
print(airquality_pivot_reset.index)
# Print the head of airquality_pivot_reset
print(airquality_pivot_reset.head())

透视重复值
假设数据收集方法意外地复制了之前的数据集。这样一个数据集,其中每一行都是重复的,已经预先加载为airquality_dup,它复制的是airquality_melt。此外,上一个练习中的airquality_melt DataFrame已预先加载。通过访问.shape属性来确认airquality_dup中存在的重复行,从而在IPython Shell中探索它们的形状。
使用.pivot_table()和aggfunc参数,不仅可以重塑数据,还可以删除重复项。最后,使用.reset_index()展平已透视的DataFrame的列。
import numpy as np
import pandas as pd
# Pivot table the airquality_dup: airquality_pivot
airquality_pivot = airquality_dup.pivot_table(index=['Month', 'Day'], columns='measurement', values='reading', aggfunc=np.mean)
# Print the head of airquality_pivot before reset_index
print(airquality_pivot.head())
# Reset the index of airquality_pivot
airquality_pivot = airquality_pivot.reset_index()
# Print the head of airquality_pivot
print(airquality_pivot.head())
# Print the head of airquality
print(airquality.head())

.pivot_table()使用的默认聚合函数是np.mean()。 因此,即使没有显式指定aggfunc参数,也可以在此DataFrame中透视重复值。
6、用.str拆分列
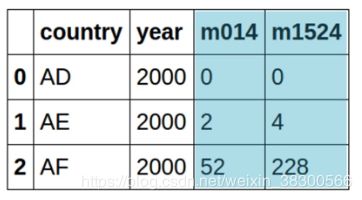
在本练习中,整理'm014'专栏,该专栏代表0-14岁的男性。 为了解析此值,需要将第一个字母提取到性别的新列中,其余部分提取到age_group的列中。 这里,由于可以按位置解析值,因此可以通过使用object类型的列的str属性来利用pandas的矢量化字符串切片。能够根据需要拆分列以便访问与您的问题相关的数据至关重要。
# Melt tb: tb_melt
tb_melt = pd.melt(tb, id_vars=['country', 'year'])
# Create the 'gender' column
tb_melt['gender'] = tb_melt.variable.str[0]
# Create the 'age_group' column
tb_melt['age_group'] = tb_melt.variable.str[1:]
# Print the head of tb_melt
print(tb_melt.head())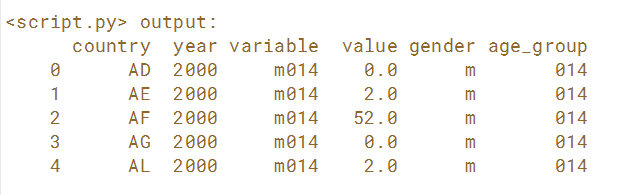
7、使用.split()和.get()拆分列
多个变量存储在列中的另一种常见方式是使用分隔符存在一列中。使用由埃博拉病例组成的数据集以及州和国家的死亡计数来处理此类病例。它已作为埃博拉病毒预先加载到DataFrame中。
数据具有列名,例如Cases_Guinea和Deaths_Guinea。这里,下划线_用作第一部分(案例或死亡)和第二部分(国家)之间的分隔符。
这一次,不能像上一个练习那样按位置直接切片变量。需使用Python的内置字符串方法.split()。默认情况下,此方法将字符串拆分为由空格分隔的部分。但是,在这种情况下,希望它由下划线拆分。可以在Cases_Guinea上执行此操作,例如,使用Cases_Guinea.split('_'),它返回列表['Cases','Guinea']。
提取此列表的第一个元素并将其分配给类型变量,将列表的第二个元素分配给国家/地区变量。可以通过访问列的str属性并使用.get()方法检索0或1索引来完成此操作,具体取决于需要的部分。

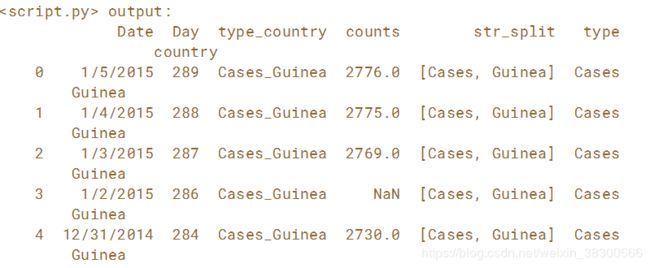
# Melt ebola: ebola_melt
ebola_melt = pd.melt(ebola, id_vars=['Date', 'Day'], var_name='type_country', value_name='counts')
# Create the 'str_split' column
ebola_melt['str_split'] = ebola_melt.type_country.str.split('_')
# Create the 'type' column
ebola_melt['type'] = ebola_melt.str_split.str.get(0)
# Create the 'country' column
ebola_melt['country'] = ebola_melt.str_split.str.get(1)
# Print the head of ebola_melt
print(ebola_melt.head())