kubernetes集群中部署EFK日志管理系统
前言
在生产环境中,日志对于排查问题至关重要,我们需要有一个日志管理系统,如efk就是目前最受欢迎的日志管理系统。kubernetes可以实现efk的快速部署和使用,通过statefulset控制器部署elasticsearch组件,用来存储日志数据,还可通过volumenclaimtemplate动态生成pv实现es数据的持久化。通过deployment部署kibana组件,实现日志的可视化管理。通过daemonset控制器部署fluentd组件,来收集各节点和k8s集群的日志。这篇文章会带领大家去安装配置EFK组件,这又是一篇万字长文,纯干货,无需踩坑,保证100%完成实验环境部署,内容较多,可先关注收藏,在慢慢学习,愿和大家共同进步和成长~
EFK组件介绍
在Kubernetes集群上运行多个服务和应用程序时,日志收集系统可以帮助你快速分类和分析由Pod生成的大量日志数据。Kubernetes中比较流行的日志收集解决方案是Elasticsearch、Fluentd和Kibana(EFK)技术栈,也是官方推荐的一种方案。
Elasticsearch是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。
Elasticsearch通常与Kibana一起部署,kibana是Elasticsearch 的功能强大的数据可视化的dashboard(仪表板)。Kibana允许你通过Web界面浏览Elasticsearch日志数据,也可自定义查询条件快速检索出elasticccsearch中的日志数据。
Fluentd是一个流行的开源数据收集器,我们将在Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
我们先来配置启动一个可扩展的 Elasticsearch 集群,然后在Kubernetes集群中创建一个Kibana应用,最后通过DaemonSet来运行Fluentd,以便它在每个Kubernetes工作节点上都可以运行一个 Pod。
资料下载
1.下文需要的yaml文件所在的github地址如下:
https://github.com/luckylucky421/efk
下面实验用到yaml文件大家需要从上面的github上clone和下载到本地,解压,然后把解压后的yaml文件传到k8s集群的master节点上,如果直接复制粘贴格式可能会有问题。
2.下文里提到的efk组件需要的镜像获取方式在百度网盘,链接如下:
链接:https://pan.baidu.com/s/1lsP2_NrXwOzGMIsVCUHtPw
提取码:kpg2
3.实验之前需要把镜像上传到k8s集群的各个节点,通过docker load -i 解压,这样可以保证下面的yaml文件可以正常执行,否则会存在镜像拉取失败问题:
docker load -i busybox.tar.gz
docker load -i elasticsearch_7_2_0.tar.gz
docker load -i fluentd.tar.gz
docker load -i kibana_7_2_0.tar.gz
docker load -i nfs-client-provisioner.tar.gz
docker load -i nginx.tar.gz
4.需要k8s环境,如果没有k8s环境,可参考如下链接部署:
https://mp.weixin.qq.com/s?__biz=MzU0NjEwMTg4Mg==&mid=2247484160&idx=1&sn=894b777d522176291065655afd976178&chksm=fb638c15cc1405033be46c1d81803d7fd49f33751e37a9ef25a028c018b081ac82c9b60ab6c7&token=1570124030&lang=zh_CN#rd
正文-安装efk组件
下面的步骤在k8s集群的master1节点操作
#创建名称空间
在安装Elasticsearch集群之前,我们先创建一个名称空间,在这个名称空间下安装日志收工具elasticsearch、fluentd、kibana。我们创建一个kube-logging名称空间,将EFK组件安装到该名称空间中。
1.创建kube-logging名称空间
cat kube-logging.yaml
kind: Namespace
apiVersion: v1
metadata:
name: kube-logging
kubectl apply -f kube-logging.yaml
2.查看kube-logging名称空间是否创建成功
kubectl get namespaces | grep kube-logging
显示如下,说明创建成功
kube-logging Active 1m
#安装elasticsearch组件
通过上面步骤已经创建了一个名称空间kube-logging,在这个名称空间下去安装日志收集组件efk,首先,我们将部署一个3节点的Elasticsearch集群。我们使用3个Elasticsearch Pods可以避免高可用中的多节点群集中发生的“裂脑”的问题。Elasticsearch脑裂可参考https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain
1.创建一个headless service(无头服务)
创建一个headless service的Kubernetes服务,服务名称是elasticsearch,这个服务将为3个Pod定义一个DNS域。headless service不具备负载均衡也没有IP。要了解有关headless service的更多信息,可参考https://kubernetes.io/docs/concepts/services-networking/service/#headless-services。
cat elasticsearch_svc.yaml
kind: ServiceapiVersion: v1metadata: name: elasticsearch namespace: kube-logging labels: app: elasticsearchspec: selector: app: elasticsearch clusterIP: None ports: - port: 9200 name: rest - port: 9300 name: inter-node在kube-logging名称空间定义了一个名为 elasticsearch 的 Service服务,带有app=elasticsearch标签,当我们将 ElasticsearchStatefulSet 与此服务关联时,服务将返回带有标签app=elasticsearch的 Elasticsearch Pods的DNS A记录,然后设置clusterIP=None,将该服务设置成无头服务。最后,我们分别定义端口9200、9300,分别用于与 REST API 交互,以及用于节点间通信。使用kubectl直接创建上面的服务资源对象:
kubectl apply -f elasticsearch_svc.yaml
查看elasticsearch的service是否创建成功
kubectl get services --namespace=kube-logging
看到如下,说明在kube-logging名称空间下创建了一个名字是elasticsearch的headless service:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None 9200/TCP,9300/TCP 2m
现在我们已经为 Pod 设置了无头服务和一个稳定的域名.elasticsearch.kube-logging.svc.cluster.local,接下来我们通过 StatefulSet来创建具体的 Elasticsearch的Pod 应用。
2.通过statefulset创建elasticsearch集群
Kubernetes statefulset可以为Pods分配一个稳定的标识,让pod具有稳定的、持久的存储。Elasticsearch需要稳定的存储才能通过POD重新调度和重新启动来持久化数据。更多关于kubernetes StatefulSet可参考https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/。
1)下面将定义一个资源清单文件elasticsearch_statefulset.yaml,首先粘贴以下内容:
apiVersion: apps/v1kind: StatefulSetmetadata: name: es-cluster namespace: kube-loggingspec: serviceName: elasticsearch replicas: 3 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch
上面内容的解释:在kube-logging的名称空间中定义了一个es-cluster的StatefulSet。然后,我们使用serviceName 字段与我们之前创建的ElasticSearch服务相关联。这样可以确保可以使用以下DNS地址访问StatefulSet中的每个Pod:,es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local,其中[0,1,2]与Pod分配的序号数相对应。我们指定3个replicas(3个Pod副本),将matchLabels selector 设置为app: elasticseach,然后在该.spec.template.metadata中指定pod需要的镜像。该.spec.selector.matchLabels和.spec.template.metadata.labels字段必须匹配。
2)statefulset中定义pod模板,内容如下:
. . . spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: - name: cluster.name value: k8s-logs - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch" - name: cluster.initial_master_nodes value: "es-cluster-0,es-cluster-1,es-cluster-2" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m"
上面内容解释:在statefulset中定义了pod,容器的名字是elasticsearch,镜像是docker.elastic.co/elasticsearch/elasticsearch:7.2.0。使用resources字段来指定容器需要保证至少有0.1个vCPU,并且容器最多可以使用1个vCPU(这在执行初始的大量提取或处理负载高峰时限制了Pod的资源使用)。了解有关资源请求和限制,可参考https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/。暴漏了9200和9300两个端口,名称要和上面定义的 Service 保持一致,通过volumeMount声明了数据持久化目录,定义了一个data数据卷,通过volumeMount把它挂载到容器里的/usr/share/elasticsearch/data目录。我们将在以后的YAML块中为此StatefulSet定义VolumeClaims。
最后,我们在容器中设置一些环境变量:
cluster.name
Elasticsearch 集群的名称,我们这里是 k8s-logs。
node.name
节点的名称,通过metadata.name来获取。这将解析为 es-cluster-[0,1,2],取决于节点的指定顺序。
discovery.zen.ping.unicast.hosts
此字段用于设置在Elasticsearch集群中节点相互连接的发现方法。
我们使用 unicastdiscovery方式,它为我们的集群指定了一个静态主机列表。
由于我们之前配置的无头服务,我们的 Pod 具有唯一的DNS域es-cluster-[0,1,2].elasticsearch.logging.svc.cluster.local,
因此我们相应地设置此变量。由于都在同一个 namespace 下面,所以我们可以将其缩短为es-cluster-[0,1,2].elasticsearch。
要了解有关 Elasticsearch 发现的更多信息,请参阅 Elasticsearch 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html。
discovery.zen.minimum_master_nodes
我们将其设置为(N/2) + 1,N是我们的群集中符合主节点的节点的数量。
我们有3个Elasticsearch 节点,因此我们将此值设置为2(向下舍入到最接近的整数)。
要了解有关此参数的更多信息,请参阅官方 Elasticsearch 文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain。
ES_JAVA_OPTS
这里我们设置为-Xms512m -Xmx512m,告诉JVM使用512MB的最小和最大堆。
尼应该根据群集的资源可用性和需求调整这些参数。
要了解更多信息,请参阅设置堆大小的相关文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html。
3)initcontainer内容
. . . initContainers: - name: fix-permissions image: busybox command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true
这里我们定义了几个在主应用程序之前运行的Init 容器,这些初始容器按照定义的顺序依次执行,执行完成后才会启动主应用容器。第一个名为 fix-permissions 的容器用来运行 chown 命令,将 Elasticsearch 数据目录的用户和组更改为1000:1000(Elasticsearch 用户的 UID)。因为默认情况下,Kubernetes 用 root 用户挂载数据目录,这会使得 Elasticsearch 无法方法该数据目录,可以参考 Elasticsearch 生产中的一些默认注意事项相关文档说明:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#_notes_for_production_use_and_defaults。
第二个名为increase-vm-max-map 的容器用来增加操作系统对mmap计数的限制,默认情况下该值可能太低,导致内存不足的错误,要了解更多关于该设置的信息,可以查看 Elasticsearch 官方文档说明:https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html。最后一个初始化容器是用来执行ulimit命令增加打开文件描述符的最大数量的。此外 Elastisearch Notes for Production Use 文档还提到了由于性能原因最好禁用 swap,当然对于 Kubernetes 集群而言,最好也是禁用 swap 分区的。现在我们已经定义了主应用容器和它之前运行的Init Containers 来调整一些必要的系统参数,接下来我们可以添加数据目录的持久化相关的配置。
4)在 StatefulSet 中,使用volumeClaimTemplates来定义volume 模板即可:
. . . volumeClaimTemplates: - metadata: name: data labels: app: elasticsearch spec: accessModes: [ "ReadWriteOnce" ] storageClassName: do-block-storage resources: requests: storage: 10Gi
我们这里使用 volumeClaimTemplates 来定义持久化模板,Kubernetes 会使用它为 Pod 创建 PersistentVolume,设置访问模式为ReadWriteOnce,这意味着它只能被 mount到单个节点上进行读写,然后最重要的是使用了一个名为do-block-storage的 StorageClass 对象,所以我们需要提前创建该对象,我们这里使用的 NFS 作为存储后端,所以需要安装一个对应的 provisioner驱动。
5)创建storageclass,实现nfs做存储类的动态供给
#安装nfs服务,选择k8s集群的master1节点,k8s集群的master1节点的ip是192.168.0.6:
yum安装nfs
yum install nfs-utils -y
systemctl start nfs
chkconfig nfs on
在master1上创建一个nfs共享目录
mkdir /data/v1 -p
cat /etc/exports
/data/v1 192.168.0.0/24(rw,no_root_squash)
exportfs -arv
使配置文件生效
systemctl restart nfs
#实现nfs做存储类的动态供给
创建运行nfs-provisioner的sa账号
cat serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-provisioner
kubectl apply -f serviceaccount.yaml
对sa账号做rbac授权
cat rbac.yaml
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
- apiGroups: [""]
resources: ["services", "endpoints"]
verbs: ["get"]
- apiGroups: ["extensions"]
resources: ["podsecuritypolicies"]
resourceNames: ["nfs-provisioner"]
verbs: ["use"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-provisioner
subjects:
- kind: ServiceAccount
name: nfs-provisioner
namespace: default
roleRef:
kind: ClusterRole
name: nfs-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-provisioner
subjects:
- kind: ServiceAccount
name: nfs-provisioner
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-provisioner
apiGroup: rbac.authorization.k8s.io
kubectl apply -f rbac.yaml
通过deployment创建pod用来运行nfs-provisioner
cat deployment.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-provisioner
spec:
selector:
matchLabels:
app: nfs-provisioner
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-provisioner
spec:
serviceAccount: nfs-provisioner
containers:
- name: nfs-provisioner
image: registry.cn-hangzhou.aliyuncs.com/open-ali/nfs-client-provisioner:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: example.com/nfs
- name: NFS_SERVER
value: 192.168.0.6
- name: NFS_PATH
value: /data/v1
volumes:
- name: nfs-client-root
nfs:
server: 192.168.0.6
path: /data/v1
kubectl apply -f deployment.yaml
kubectl get pods
看到如下,说明上面的yaml文件创建成功:
NAME READY STATUS RESTARTS AGE
nfs-provisioner-595dcd6b77-rkvjl 1/1 Running 0 6s
注:上面yaml文件说明:
- name: PROVISIONER_NAME
value: example.com/nfs
#PROVISIONER_NAME是example.com/nfs,example.com/nfs需要跟后面的storageclass的provisinoer保持一致
- name: NFS_SERVER
value: 192.168.0.6
#这个需要写nfs服务端所在的ip地址,大家需要写自己的nfs地址
- name: NFS_PATH
value: /data/v1
#这个是nfs服务端共享的目录
volumes:
- name: nfs-client-root
nfs:
server: 192.168.0.6
#这个是nfs服务端的ip,大家需要写自己的nfs地址
path: /data/v1 #这个是nfs服务端的共享目录
创建storageclass
cat class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: do-block-storage
provisioner: example.com/nfs
kubectl apply -f class.yaml
注:
provisioner:example.com/nfs #该值需要和provisioner配置的保持一致
6)最后,我们指定了每个 PersistentVolume 的大小为 10GB,我们可以根据自己的实际需要进行调整该值。最后,完整的elasticsaerch-statefulset.yaml资源清单文件内容如下:
cat elasticsaerch-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 10Gi
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 10Gi
kubectl apply -f elasticsaerch-statefulset.yaml
kubectl get pods -n kube-logging
显示如下,说明es创建成功了:
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 2m8s
es-cluster-1 1/1 Running 0 117s
es-cluster-2 1/1 Running 0 107s
kubectl get svc -n kube-logging
显示如下
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None 9200/TCP,9300/TCP 33m
pod部署完成之后,可以通过REST API检查elasticsearch集群是否部署成功,使用下面的命令将本地端口9200转发到 Elasticsearch 节点(如es-cluster-0)对应的端口:
kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
然后,在另外的终端窗口中,执行如下请求,新开一个master1终端:
curl http://localhost:9200/_cluster/state?pretty
输出如下:
{
"cluster_name" : "k8s-logs",
"compressed_size_in_bytes" : 348,
"cluster_uuid" : "QD06dK7CQgids-GQZooNVw",
"version" : 3,
"state_uuid" : "mjNIWXAzQVuxNNOQ7xR-qg",
"master_node" : "IdM5B7cUQWqFgIHXBp0JDg",
"blocks" : { },
"nodes" : {
"u7DoTpMmSCixOoictzHItA" : {
"name" : "es-cluster-1",
"ephemeral_id" : "ZlBflnXKRMC4RvEACHIVdg",
"transport_address" : "10.244.8.2:9300",
"attributes" : { }
},
"IdM5B7cUQWqFgIHXBp0JDg": {
"name" : "es-cluster-0",
"ephemeral_id" : "JTk1FDdFQuWbSFAtBxdxAQ",
"transport_address" : "10.244.44.3:9300",
"attributes" : { }
},
"R8E7xcSUSbGbgrhAdyAKmQ" : {
"name" : "es-cluster-2",
"ephemeral_id" :"9wv6ke71Qqy9vk2LgJTqaA",
"transport_address" : "10.244.40.4:9300",
"attributes" : { }
}
},
...
看到上面的信息就表明我们名为 k8s-logs的Elasticsearch 集群成功创建了3个节点:es-cluster-0,es-cluster-1,和es-cluster-2,当前主节点是 es-cluster-0。
#安装kibana组件
elasticsearch安装成功之后,开始部署kibana
cat kibana.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.2.0
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
上面我们定义了两个资源对象,一个Service和Deployment,为了测试方便,我们将 Service 设置为了 NodePort 类型,Kibana Pod 中配置都比较简单,唯一需要注意的是我们使用ELASTICSEARCH_URL 这个环境变量来设置Elasticsearch 集群的端点和端口,直接使用 Kubernetes DNS 即可,此端点对应服务名称为 elasticsearch,由于是一个 headless service,所以该域将解析为3个 Elasticsearch Pod 的 IP 地址列表。
配置完成后,直接使用 kubectl工具创建:
kubectl apply -f kibana.yaml
kubectl get pods -n kube-logging
显示如下,说明kibana也已经部署成功了
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 170m
es-cluster-1 1/1 Running 0 170m
es-cluster-2 1/1 Running 0 170m
kibana-5749b5778b-c9djr 1/1 Running 0 4m3s
kubectl get svc -n kube-logging
显示如下:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None 9200/TCP,9300/TCP 3h28m
kibana ClusterIP 10.104.159.24 5601/TCP 11m
修改service的type类型为NodePort:
kubectl edit svc kibana -n kube-logging
把type:ClusterIP变成type: NodePort
保存退出之后
kubectlget svc -n kube-logging
显示如下:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearchClusterIP None 9200/TCP,9300/TCP 3h50m
kibana NodePort 10.104.159.24 5601:32462/TCP 34m
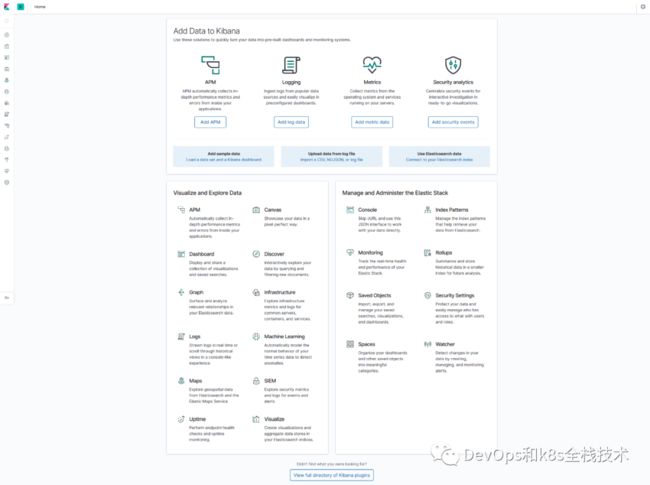
在浏览器中打开http://<任意节点IP>:32462即可,如果看到如下欢迎界面证明 Kibana 已经成功部署到了Kubernetes集群之中。
#安装fluentd组件
我们使用daemonset控制器部署fluentd组件,这样可以保证集群中的每个节点都可以运行同样fluentd的pod副本,这样就可以收集k8s集群中每个节点的日志,在k8s集群中,容器应用程序的输入输出日志会重定向到node节点里的json文件中,fluentd可以tail和过滤以及把日志转换成指定的格式发送到elasticsearch集群中。除了容器日志,fluentd也可以采集kubelet、kube-proxy、docker的日志。
cat fluentd.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
imagePullPolicy: IfNotPresent
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
kubectl apply -f fluentd.yaml
查看是否部署成功
kubectl get pods -n kube-logging
显示如下,看到status状态是running,说明部署成功:
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 6 57m
es-cluster-1 1/1 Running 5 57m
es-cluster-2 1/1 Running 0 45m
fluentd-fs54n 1/1 Running 0 37m
fluentd-ghgqf 1/1 Running 0 37m
kibana-5749b5778b-zzgbc 1/1 Running 0 39m
Fluentd启动成功后,我们可以前往 Kibana 的 Dashboard 页面中,点击左侧的Discover,可以看到如下配置页面:

在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,这里只需要在文本框中输入logstash-*即可匹配到 Elasticsearch集群中的所有日志数据,然后点击下一步,进入以下页面:
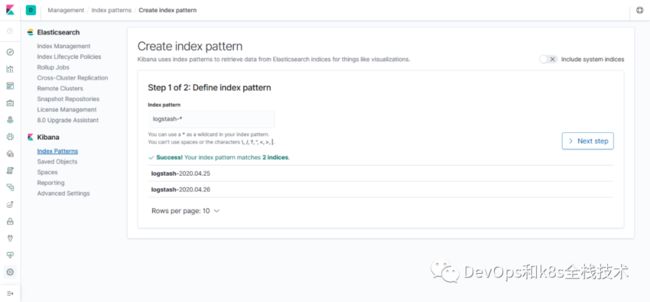
点击next step,出现如下

选择@timestamp,创建索引
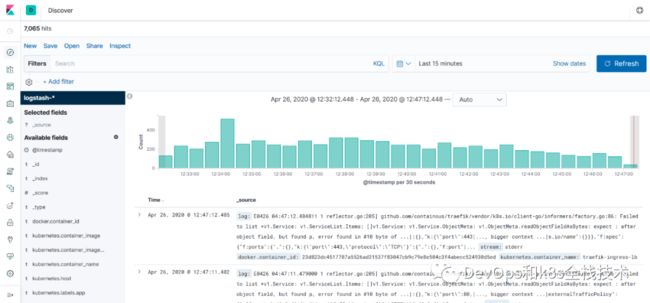
点击左侧的discover,可看到如下:
#测试容器日志
cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
imagePullPolicy: IfNotPresent
args: [/bin/sh, -c,'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
kubectl apply -f pod.yaml
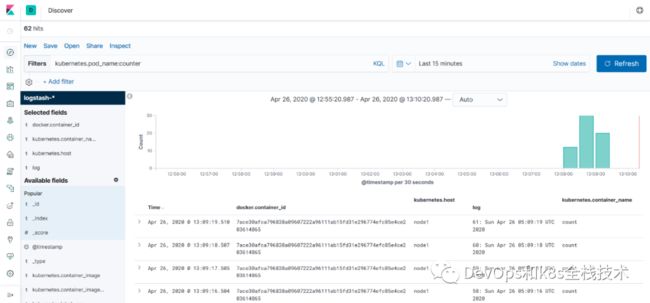
登录到kibana的控制面板,在discover处的搜索栏中输入kubernetes.pod_name:counter,这将过滤名为的Pod的日志数据counter,如下所示:
总结
通过上面几个步骤,我们已经在k8s集群成功部署了elasticsearch,fluentd,kibana,这里使用的efk系统包括3个Elasticsearch Pod,一个Kibana Pod和一组作为DaemonSet部署的Fluentd Pod。
要了解更多关于elasticsearch可参考:https://www.elastic.co/cn/blog/small-medium-or-large-scaling-elasticsearch-and-evolving-the-elastic-stack-to-fit。
Kubernetes中还允许使用更复杂的日志系统,要了解更多信息,可参考https://kubernetes.io/docs/concepts/cluster-administration/logging/
技术交流
学无止境,了解更多关于kubernetes/docker/devops/openstack/openshift/linux/IaaS/PaaS相关内容,想要获取更多资料和免费视频,可按如下方式进入技术交流群
微信:luckylucky421302
按如下指纹可关注公众

本文参考链接如下:
https://www.digitalocean.com/community/tutorials/how-to-set-up-an-elasticsearch-fluentd-and-kibana-efk-logging-stack-on-kubernetes