干货 | 一文让你了解Pandas数据结构

作者:木木
来源:Python数据分析实战与AI干货
1
导入相关的包
import numpy as np
import pandas as pd
from pandas import DataFrame
from pandas import Series
2
Series 的相关操作
obj = Series([4, 7, -5, 3])
print(obj)
print(obj.values)
print(obj.index)

obj2 = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
print(obj2)
print(obj2['a'])

obj2['d'] = 6
print(obj2[['c', 'a', 'd']])

obj2[obj2 > 0]

obj2 * 2

np.exp(obj2)

print('b' in obj2)
print('e' in obj2)

# Dict -> Series
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = Series(sdata)
obj3

states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = Series(sdata, index=states) # 自动与dict的key匹配
obj4

print(pd.isnull(obj4))
print(pd.notnull(obj4))

print(obj3 + obj4) # 数据自动对齐

obj4.name = '人口'
obj4.index.name = '州'
obj4
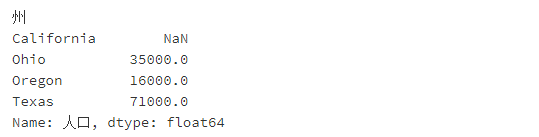
obj = Series([4, 7, -5, 3])
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan'] # 更新索引
obj

3
DataFrame 的相关操作
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = DataFrame(data) # key对应frame的列名
frame

frame = DataFrame(data, columns=['year', 'state', 'pop']) # 指定列顺序
frame

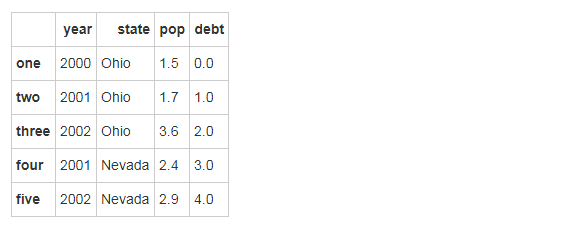
frame2 = DataFrame(data,
columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five']) # 分别指定行列名字,缺失值自动填充,比如debt列。
frame2

print(frame2['state']) # 通过索引返回指定列,返回类型为Series
print(frame2.year)
print(type(frame.state))

print(frame2.loc['three']) # 使用loc访问行,iloc针对默认的数字索引
print(frame2.iloc[0])

frame2['debt'] = 16.5 # 修改整列值
frame2

frame2['debt'] = np.arange(5.)
frame2
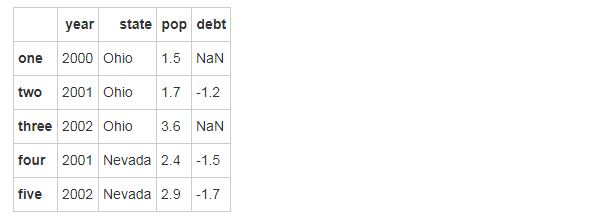
val = Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
frame2['debt'] = val # 索引不匹配的话自动补NaN
frame2
del frame2['eastern'] # 删除指定列
frame2.columns
![]()
pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame3 = DataFrame(pop) # 通过嵌套字典指定列和行索引
frame3.T # 转置

pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame3 = DataFrame(pop) # 通过嵌套字典指定列和行索引
DataFrame(pop, index=[2001, 2002, 2003]) # 索引2003匹配不到,自动填充NaN

pdata = {'Ohio': frame3['Ohio'][:-1],
'Nevada': frame3['Nevada'][:2]} # 使用Series替代普通数组
DataFrame(pdata)

frame3.index.name = 'year' # 设置索引和列的名字
frame3.columns.name = 'state'
frame3

print('Ohio' in frame3.columns)
print(2003 in frame3.index)

# Index的方法和属性
# append: 连接另一个Index对象,产生一个新的Index。
# diff: 计算差集,并得到一个Index。
# interp:计算交集
# union: 计算并集
# isin: 计算一个指示各值是否都包含在参数集合中的布尔型数组
# delete: 删除索引i处的元素,并得到新的Index。
# drop: 删除传入的值,并得到新的Index。
# insert: 将元素插入到索引i处,并得到新的Index。
# is_monotonic:如果单调增长,返回True。
# is_unique: 当Index没有重复值时,返回True。
# unique: 计算Index中唯一值得数组
◆ ◆ ◆ ◆ ◆

长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:

猜你喜欢
● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!
● 全球股市跳水大战,谁最坑爹!
● 上万条数据撕开微博热搜的真相!
● 你相信逛B站也能学编程吗