Kylin 在腾讯的平台化及 Flink 引擎实践
近期的 Apache Kylin Meetup 深圳站上,我们邀请到腾讯的程广旭与 T3 出行的杨华分享了 Kylin 在腾讯的应用。本次分享分为两个部分,第一部分介绍了 Kylin 的平台化改造实践及改造后的预期效果,第二部分会介绍 Flink Cube Engine 的原理、使用方法及独特优势。
现场视频链接: https://v.qq.com/x/page/n0928qt51gv.html
Kylin 平台化实践
首先,介绍下我们为什么进行平台化改造?
我们部门为公司内其他业务线提供了各种大数据平台,如 Kylin、HBase、Spark、Flink 等等,提供公共统一的平台系统势必会牵扯到用户管理、资源隔离、部门内各个平台的融合等问题,而 Kylin 现有的用户管理、资源隔离机制并不能满足我们需求,基于此,我们对 Kylin 进行了平台化改造。平台化改造完成后,我希望在以下几个方面,能够有一些改进:
- 用户管理
- 资源隔离
- 易用性提升
- 方便运维
1. 用户管理
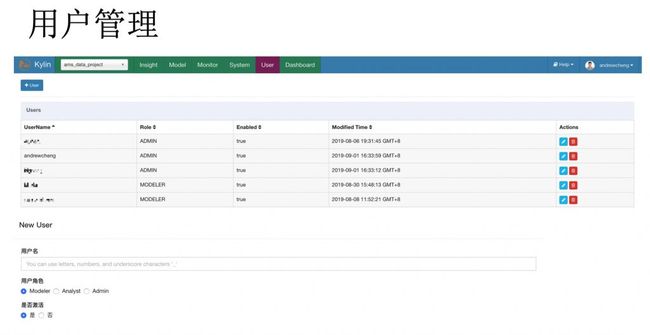
为了便于系统的管理及安全,公司内部有一套自己的认证系统,而且需要用个人账号去验证,所以 Kylin 作为一个平台对外提供服务的话,也需要接入到该系统。所以,我们新增了一个用户管理界面,该界面展示了 Kylin 平台内的所有用户。管理员可以新增任一用户到 Kylin 平台,新增用户时会填写企业微信名、用户角色以及是否激活用户。当用户登录系统时,会自动检测用户账号以及该账号是否在平台内注册,如果没有注册则无权限,反之自动登录系统。
2. 内部 Hive 兼容

由于历史原因,我们部门内的 Hive 版本(THive)与 Kylin 不兼容,这就导致 Kylin 无法正常访问 Kylin 集群,所以我们采用了上图所示的兼容方案。首先,我们使用社区 Hive 版本搭建一个全新的 Hive,并作为 Kylin 的默认 Hive;其次,当 kylin 加载源表时,我们是通过内部的 UPS 系统读取 THive 的元数据信息;最后,在 Load 源表到 Kylin 时,我们根据表的元数据信息在 Kylin 的 Hive 上创建一张相同的表,但该表的存储路径依旧指向 THive 的路径,而用户在构建 cube 时,则访问新创建的表,至此就解决了 Kylin 访问 THive 的问题。
3. 计算资源可配置化

目前,Kylin 配置计算资源信息有两种方式:一是在 Kylin 配置文件中配置一个全局的计算集群及队列;二是在创建工程或者 Cube 时,在扩展参数中指定集群配置。这两种配置方式在灵活性及便捷性方面都比较差,而在我们内部是有接口可以获取到某一个用户有计算资源的计算集群及计算队列的,所以,在创建工程或者 Cube 时,我们使用了下拉框选择式的方式,让用户选择提交任务的计算资源及队列,从而大大简化了用户的使用流程。
4. 通知机制

Kylin 只提供了发邮件通知的功能,而作为目前使用最广泛的工具,微信、企业微信在实时性及便捷性方面都远远胜于邮件,所以,我们提供了邮件、微信、企业微信三种方式,供用户选择。
5. 定时调度
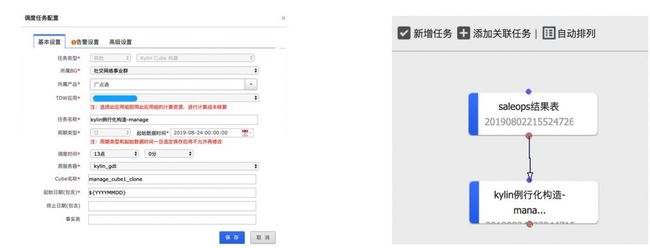
Kylin 系统自身并没有提供定时调度功能,但基本上每家公司都有自己的统一调度平台,我们也不例外。我们通过 Kylin 提供的API接口,将 Cube 定时构建的功能作为一个插件集成到了公司内部的统一调度平台上。
6. 业务接入

做完以上平台化改造后,Kylin 平台基本具备了接入不同类型业务的能力,用户申请接入流程如上图所示。
业务使用情况:
我们团队是在今年初才开始引入 Kylin,目前已经在使用的业务主要有 QQ 音乐、腾讯视频、广点通、财付通等,Cube 的数量有 10 个,单份数据存储总量是 5 T,数据规模在 30 亿条左右。
Flink Cube Engine 原理及实践
目前,Kylin 已经支持使用 MapReduce 和 Spark 作为构建引擎,而作为目前比较火的流批一体的大数据计算引擎怎能缺席?所以我使用 Flink 开发了一个高性能的构建引擎:Flink Cube Engine。
Flink Cube Engine 是腾讯基于 Kylin 插件化的 Cube Engine 架构开发的一个高性能构建引擎,目前已具备了上线使用的能力,感兴趣的同学可以体验一下,目前该引擎已经在腾讯生产环境上线 1 个月+,非常稳定而且效果不错。
Umbrella issue:
Umbrella issue:
https://issues.apache.org/jira/browse/KYLIN-3758
分支:
https://github.com/apache/kylin/tree/engine-flink
1. 支持 Flink Engine 的子任务
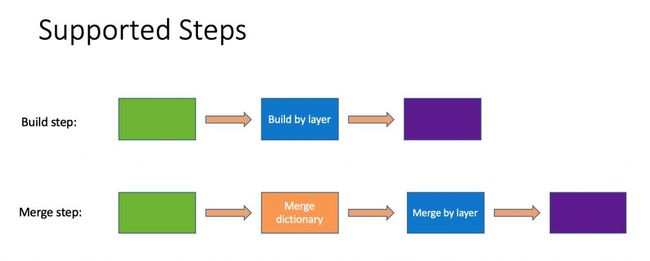
Kylin 的一次 Cube 构建任务,包含了很多个子任务,而最重要的莫过于 Cube 构建这一步骤,所以,我们在 build 和 merge Cube 这两种任务中,优先实现了Cube 构建这一步骤,其他计算步骤依旧通过使用 MapReduce 来实现。
2. 如何使用 Flink Cube Engine

选择使用 Flink Cube Engine 的方式也和选择 Map Reduce 和 Spark 任务类似,我们提供了前台可视化的界面,供用户选择。
3. Flink Cube Engine 与 Spark (线上业务)

上图是我们内部业务上线 Flink Cube Engine 之后的性能对比,从图中可见,该步骤的构建耗时从 49 分钟降到了 13 分钟,优化效果比较明显。两种情况的资源配置如下:
Flink 配置为:
-ytm 4G -yjm 2G -ys 1 -p 100 -yn 100
Spark 采用的动态分配资源如下:
kylin.engine.spark-conf.spark.dynamicAllocation.enabled=true
kylin.engine.spark-conf.spark.dynamicAllocation.minExecutors=2
kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors=1000
kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout=300
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
kylin.engine.spark-conf.spark.shuffle.service.port=7337
虽然,Spark 采用的是动态分配资源,但在任务执行过程中,我们观察到 Spark实际分配的资源远比 Flink 要多的多。
那为什么性能提升会那么明显呢?
4. Flink Cube Engine 的优化
性能的提升,无非有两方面的原因,一是参数的优化,二是代码的优化。
1) 调参

影响 Flink 任务性能主要有几个核心参数:并行度、单个 TM slot 数目、TM container 数目,其中单个 TM container 数目=并行度/单个 TM slot 数目。
我们调优的过程采用了控制变量法,即:固定并行度不变、固定 Job 总内存数不变。通过不断的调整单个 TM 的 slot 数目,我们发现如果单个 TM 的 slot 数目减少,拉起更多的 TM container 性能会更好。
此外,我们还使用了对象复用、内存预分配等方法,发现没有对性能提升起到太大的效果。
2) 代码优化(合并计算)

在实现 Flink Cube Engine 的时候,一开始我们使用了 Map/Reduce 两个算子,发现性能很差,比 Spark 的性能还要差很多,后来我们通过调整使用了 Flink 的 mapPartition/reduceGroup 两个算子,性能就有了明显的提升。
Flink Cube Engine 下一步的计划:
1. 全链路 Flink
如上所述,目前 Cube 构建过程中,只有最关键的 cube 构建这一子任务使用了 Flink,而其他子任务仍然使用的是 MapReduce,我们下一步会继续完善 Flink Cube Engine,将所有的子任务都使用 Flink 来构建。
2. Flink 升级到 1.9

Flink 最近发布了 1.9.0,该版本包含了很多重要特性且性能也有了一定提升,所以,我们会把 Flink Cube Engine 使用的 Flink 版本升级到1.9.0。
他们都在用 Apache Kylin
eBay | 滴滴 | 小米 | 美团 | 百度 | 携程
Strikingly | 斗鱼 | 银联 | 京东 | 思科 | 链家
58集团 | 唯品会 | 中国移动 | 网易游戏 | 搜狐
满帮集团 | 绿城 | 好买财富 | 魅族 | 4399
微医 | 马蜂窝 | 卷皮网 | 特来电 | 麻袋财富
Kylin's Github Repo 传送门
↓↓↓
https://github.com/apache/kylin
了解更多大数据资讯,点击进入Kyligence官网
---------------------------------------------------------------------------------------------
2019 年 11 月 16日 Apache Kylin Meetup 北京站正在火热报名!邀请到滴滴、微众银行、一点资讯以及 Kyligence的技术专家为大家呈现精彩应用案例与实践:https://www.huodongxing.com/event/2516174942311