之前介绍了在Spark Streaming的环境中,如何启动Receiver进行数据接收,那么当我们Receiver启动了之后,就会进行数据接收,接受的数据就会进行相应的存储等待后续的计算Job进行调用(这也是Spark Streaming叫做”micro-batch”的一个特色)。所以数据存储过程需要我们深度挖一下。
Spark Streaming 数据存储方式
资深老玩家只要看到在Receiver里面调用store() 来存储我们接收到的Block数据的时候,就领悟到实际上是利用ReceiverSupervisor来进行存储,那么我们就从ReceiverSupervisor看起走。
-
下面是ReceiverSupervisor提供出来的数据存储的相应接口
/** Push a single record of received data into block generator. */
def pushSingle(data: Any) {
defaultBlockGenerator.addData(data)
}
/** Store an ArrayBuffer of received data as a data block into Spark's memory. */
def pushArrayBuffer(
arrayBuffer: ArrayBuffer[_],
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(ArrayBufferBlock(arrayBuffer), metadataOption, blockIdOption)
}
/** Store an iterator of received data as a data block into Spark's memory. */
def pushIterator(
iterator: Iterator[_],
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(IteratorBlock(iterator), metadataOption, blockIdOption)
}
/** Store the bytes of received data as a data block into Spark's memory. /
def pushBytes(
bytes: ByteBuffer,
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(ByteBufferBlock(bytes), metadataOption, blockIdOption)
}
```
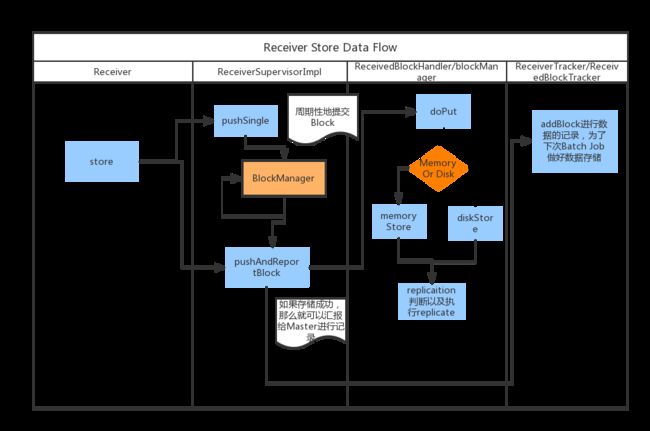
我们看到除了pushSingle* 跟大家不一样以外,几乎都是调用pushAndReportBlock来完成的存储,其实pushSingle最后也是调用pushAndReportBlock来完成的。那么这里defaultBlockGenerator.addData(data)做了什么呢,主要是就是要有规律的产生Block数据,这里剧透一个很关键的事情: 一份Block的数据就对应RDD里面的一个partition, partition就意味着task的数目,为了控制住partition以及task合理,这里对于单个的数据,我们就需要hold住下,有规律的产生Block。
BlockGenerator里面就有这两个线程: 一个周期性的把前一个batch的数据构造成一个Block, 一个就负责把这个Block的数据push到BlockManager.
**关键的一个主角参数出现一个: spark.streaming.blockInterval ,他就是控制产生Block的周期,默认为200ms,如果大家的流式数据量很大的话,那么就考虑降低这个参数,从而获得大量的partition以及task上面的并发。**
那么接下来我们还是看下**pushAndReportBlock**做了什么事情吧, 因为不管存single 还是 存一堆的 都是调用了他。
- pushAndReportBlock做了两件事调receivedBlockHandler帮他完成真正存储过程,并且通过之前跟master建立好的链trackerEndpoint汇报说我已经添加了一个Block.
val blockId = blockIdOption.getOrElse(nextBlockId) // nextBlockId = streamId + newBlockId.getAndIncrement() 来取一个唯一的Id
.....
val blockStoreResult = receivedBlockHandler.storeBlock(blockId, receivedBlock)
.....
trackerEndpoint.askWithRetryBoolean
我们先看下接下来看下 ReceivedBlockHandler如何存Block, 然后再看下汇报给master, master又做了什么对于这个Block做了什么
3. 在ReceivedBlockHandler里面进行存储的时候,真正存储的主角就出现啦 ---**BlockManager**,首先这里需要讲清楚一点,我一开始也没有理解透的,后来翻了好多代码才明白的,就是这个BlockManager是如何每个Executor都有一个的?
```java
private val host = SparkEnv.get.blockManager.blockManagerId.host
private val executorId = SparkEnv.get.blockManager.blockManagerId.executorId
从上面代码不难看出blockManager是从一个全局SparkEnv中得到,当每个Executor启动的时候就会创建自己Executor的SparkEnv,这时候就会有BlockManager产生(先立FLAG在后面就会讲到Executor创建BlockManager的整个流程)。机智的我,一开始一直以为这个SparkEnv来自于master(创建这个ReceiverSupervisor的时候,从master序列化过来的), 后来发现怎么也绕不通这个流程,后来无意翻到Executor的代码才发现原来每个Executor构造自己jvm执行环境的时候就创建了自己的SparkEnv.
- 重点来了,吃瓜群众终于等到了BlockManager如何存储数据的了。那我们就聊下这个流程吧。
a. 第一步,我们会通过BlockInfoManager获得写入这个Block的锁,当已经有人在写入同一个Block的时候,那么就会进行等待直到有人已经成功写入,这时候我们写入操作会变成一个读取操作(获取一个读锁接着读),同时会返回给我们告诉这个Block已经被人捷足先登啦,这次写入就返回失败,如果一切顺利,那么就会拿到这个BlockId的写锁。
b. 第二步,如果存储等级可以level.useMemory , 那么就先利用memoryStore放入内存,如果放不下就会利用diskStore来存入磁盘里面。如果存储等级为level.useDisk 就直接存入磁盘中, 不管是数据最后存入memory 还是 disk, 都会去check存储的状态,顺利存储就会通知master
c.第三步, 根据level.replication > 1来去判断是否要进行replicate, 如果要进行replicate,就会replicate(blockId, bytesToReplicate, level, remoteClassTag) 来完成block到其他node的replicate.
存储到本Executor的blockManager的过程就完成,接下来我们会看下汇报给master之后,汇报给master的目的其实就是为了构造分布式任务的时候,master可以做到分布式调配。
-
大家还记得我们是通过下面这个方法, 从Receiver端告诉master,Block已经加成功
javatrackerEndpoint.askWithRetry[Boolean](AddBlock(blockInfo))
注意这里的blockInfo里面主要有个carry信息: 成功存储的BlockId信息在这之前有那么一个东西叫做 ReceiverTracker, 他是在JobScheduler里面初始化的。这家伙就会监听这种Block成功加入的消息。
这家伙接受到消息之后就会通过专门的ReceivedBlockTracker来进行记录,
记录主要就是StreamId和这个BlockId 存入streamIdToUnallocatedBlockQueues里面,为什么叫unallocated, 就是代表Streaming的job还没有来进行处理这些blockIds,等着被收割的。后续最要的工作的就留给Spark Streaming Job的讲解啦, 下面贴一个Store存储的流程图,一言不合就上图.