数据库——关系型数据库和非关系型数据库调研
系统集成组数据库调研对比文档
- 关系型数据库和非关系型数据库
组内使用数据库为关系型数据库oracle,现在市场上出现了更为流行的关系型数据库诸如Mysql/MariaDB、PostgreSql、PPAS(增强型PostgreSql),以及当前在大数据框架中比较流行的非关系型数据库诸如Redis、MongoDB等。
首先从大的框架进行对比,关系型数据库和非关系型数据库之间的区别,以及两者使用的场景。这两种数据库理论上不应被用来进行对比,两者的侧重点不同,只能说在不同的场景下谁更适合而已。非关系型数据库理的论诞生其实也是因为传统的数据库在某些日益增长的数据量需求面前显得稍微乏力。两者不存在孰优孰劣,根据业务进行选择。
关系型数据库的特点:
- 高度组织化结构化数据
- 结构化查询语言(SQL) (SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
非关系型数据库的特点:
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
下面通过几个概念的介绍,将关系型和非关系型进行对比,说明为何两者分别具备上述特点:
-
- 数据结构
先用一张实例图大概说明关系型数据库和非关系型数据库在存储结构上的区别:

非关系型数据库是一种基于健值对K-V形式的数据存储结构,类似于Hash表,提供索引和值。在非关系型数据库中不再需要提前定义表(在NoSql中称作集合)的结构,可以将完全不同的数据结构插入到集合中(但一般插入同一集合的数据有一定关联性),如下图:

这就是非关系型数据库的数据结构不固定的特点,这为他本身的分布式存储及扩展性提供了较好的基础,但缺点是不便于对整个存储的理解。
而传统的关系型数据库的特点表结构,虽然对后续的信息扩展带来不便。但是基于表结构的关系模型使得存储更容易理解,贴近逻辑世界。同时关系模型提供的丰富的完整性(实体完整性、参照完整性和用户定义的完整性),使得维护方便,大大减低了数据冗余和数据不一致的概率。
-
- 读写性能、并发性能
在谈读写性能之前需要先说事务性的概念,事务特性可以说是关系型数据库最大的特点,不客气的说应该是区分关系型和非关系型数据库的主要特性。非关系数据库为了高并发和可扩展的性能,对事务特性进行了牺牲,比如弱一致性,后面将会说明非关系型数据本身的特性(CAP定理、BASE特性)。了解关系型数据库的事务特性,对我们进行数据库的选型有决定性的意义。
-
-
- 关系型数据库ACDI特性
-
ACDI特性包括:原子性、一致性、隔离性、永久性
原子性:原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
一致性:一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
独立性:所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
持久性:持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
-
-
- 非关系型数据库BASE特性
-
谈非关系型数据库的BASE特性之前,先了解CAP定理:
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。

BASE特性:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble --基本可用
- Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
- Eventual Consistency --最终一致性 最终一致性, 也是是 ACID 的最终目的。
从上面介绍的三个理论事务特性、CAP定理和BASE特性,在综合对比自己的系统所需要的特性,作为数据库选型的一个参考。
-
-
- 综述
-
关系型数据库的最大特点就是事务的一致性:传统的关系型数据库读写操作都是事务的,具有ACID的特点,这个特性使得关系型数据库可以用于几乎所有对一致性有要求的系统中,如典型的银行系统。
但是,在网页应用中,尤其是SNS应用中,一致性却不是显得那么重要,用户A看到的内容和用户B看到同一用户C内容更新不一致是可以容忍的,或者说,两个人看到同一好友的数据更新的时间差那么几秒是可以容忍的,因此,关系型数据库的最大特点在这里已经无用武之地,起码不是那么重要了。
相反地,关系型数据库为了维护一致性所付出的巨大代价就是其读写性能比较差,而像微博、facebook这类SNS的应用,对并发读写能力要求极高,关系型数据库已经无法应付(在读方面,传统上为了克服关系型数据库缺陷,提高性能,都是增加一级memcache来静态化网页,而在SNS中,变化太快,memchache已经无能为力了),因此,必须用新的一种数据结构存储来代替关系数据库。
-
- 扩展性能
扩展性能主要分为横向扩展和纵向扩展,纵向扩展主要是指提高单台物理机器的性能,以满足更大的数据需求以及并发的应用场景。横向扩展则是指在面对大数据和高并发的场景之下,可以方便的通过扩展物理机的数量,从而达到使用需求。
扩展性涉及到的相关概念有分布式系统和分布式的存储算法、分区及分片,其中分布式系统和分布式的存储算法概念都比较大,建议可以通过网络了解,在本文档中主要简单介绍一下分区和分片的概念,为后面对比关系型和非关系型数据库的扩展性能提供一定理论名词基础。
-
-
- 数据切分Sharding
-
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
-
-
- Sharding切分:Mysql vs MongoDB
-
MongoDB:由于前面说的数据结构不存在严格的关联性,数据之间耦合程度较低,这为非关系型Nosql的扩展性能提供了先天的优势。MongoDB数据库本身就集成了分片的功能。通过增加配置前端路由的节点,让整个集群看上去像单一数据库,前端应用可以透明使用。
Mysql:关系型数据库Mysql为了达到切分的功能,目前主流的方式是使用中间件,或者叫中间代理层,常用的譬如官方的MySqlProxy、谷歌团队的Hibernate Shards、基于java开发的Amoeba、基于java的HiveDB等。
因此,在扩展性上,非关系型数据库确实会存在天然的优势。但关系型数据库通过开源框架的中间件配合,也可以达到切分效果,对业务进行分布式的管理。
-
- 其他特性
SQL语句的支持:非关系型数据库不支持SQL语句,这对于长期使用关系型数据库的SQL语句的人员来说,适应其新的语法也将花不少时间。
以非关系型数据库MongoDB中对文档进行查询(更新某一条记录)为例:


- 关系型数据库MariaDB(MySql)
MariaDB是MySQL源代码的一个分支,在意识到Oracle会对MySQL许可做什么后分离了出来(MySQL先后被Sun、Oracle收购)。除了作为一个Mysql的“向下替代品”,MariaDB包括的一些新特性使它优于MySQL。
可以说MariaDB大部分兼容mysql的数据库,基本上原有的基本上原有的mysql写法和特性都支持。除非应用的性能非常高端,否则很难发现有不兼容的地方。
另外就是在Centos7及以上的操作系统版本中,默认在软件列表中提供的数据库有Mysql变为了MariaDB。
-
- MariaDB在Centos7下的安装
安装命令
#yum -y install mariadb mariadb-server
安装完成MariaDB,首先启动MariaDB
#systemctl start mariadb
设置开机启动
#systemctl enable mariadb
接下来进行MariaDB的相关简单配置
#mysql_secure_installation
首先是设置密码,会提示先输入密码
Enter current password for root (enter for none):<–初次运行直接回车
设置密码
Set root password? [Y/n] <– 是否设置root用户密码,输入y并回车或直接回车
New password: <– 设置root用户的密码
Re-enter new password: <– 再输入一次你设置的密码
其他配置
Remove anonymous users? [Y/n] <– 是否删除匿名用户,回车
Disallow root login remotely? [Y/n] <–是否禁止root远程登录,回车,
Remove test database and access to it? [Y/n] <– 是否删除test数据库,回车
Reload privilege tables now? [Y/n] <– 是否重新加载权限表,回车
初始化MariaDB完成,接下来测试登录
#mysql -uroot -ppassword
完成。
-
- MariaDB在Centos7下的配置
配置MariaDB的字符集:
编辑文件/etc/my.cnf
vi /etc/my.cnf
在[mysqld]标签下添加
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
编辑文件/etc/my.cnf.d/client.cnf
vi /etc/my.cnf.d/client.cnf
在[client]中添加
default-character-set=utf8
文件/etc/my.cnf.d/mysql-clients.cnf
vi /etc/my.cnf.d/mysql-clients.cnf
在[mysql]中添加
default-character-set=utf8
全部配置完成,重启mariadb
#systemctl restart mariadb
之后进入MariaDB查看字符集
mysql> show variables like "%character%";show variables like "%collation%";
显示为
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_unicode_ci |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
3 rows in set (0.00 sec)
字符集配置完成。
-
- MariaDB在Centos7下C++的数据库连接方式
- 采用驱动进行连接
- MariaDB在Centos7下C++的数据库连接方式
通过Driver的方式,这种方法的优点是可以结合各种面向对象的数据库访问技术(ADO, ODBC, JDBC等等),只要配置好不同的驱动,同样的代码可以访问各种不同的数据库;缺点就在于驱动的安装和配置不是一般的麻烦,还要考虑数据库版本和驱动版本兼容性的问题。
-
-
- 采用数据库自带的C API连接
-
相比于ADO之类的方法,这种方式不用配置驱动,因此也没有反人类的版本兼容性问题。另外在综合处理单元中已经有现成的mysql的连接接口,也是采用数据库自带的接口方式进行连接。

若编译出错则运行命令yum install mysql-devel安装对应的开发环境。
编译:
#g++ -L /usr/lib64/mysql/ mariadbtest.cpp -o mariadbtest –lmysqlclient
运行:
./mariadbtest
登录数据库查询对应记录:

给出数据库的操作接口函数:
mysql_affected_rows() 返回被最新的UPDATE, DELETE或INSERT查询影响的行数。
mysql_close() 关闭一个服务器连接。
mysql_connect() 连接一个MySQL服务器。该函数不推荐;使用mysql_real_connect()代替。
mysql_change_user() 改变在一个打开的连接上的用户和数据库。
mysql_create_db() 创建一个数据库。该函数不推荐;而使用SQL命令CREATE DATABASE。
mysql_data_seek() 在一个查询结果集合中搜寻一任意行。
mysql_debug() 用给定字符串做一个DBUG_PUSH。
mysql_drop_db() 抛弃一个数据库。该函数不推荐;而使用SQL命令DROP DATABASE。
mysql_dump_debug_info() 让服务器将调试信息写入日志文件。
mysql_eof() 确定是否已经读到一个结果集合的最后一行。这功能被反对; mysql_errno()或mysql_error()可以相反被使用。
mysql_errno() 返回最近被调用的MySQL函数的出错编号。
mysql_error() 返回最近被调用的MySQL函数的出错消息。
mysql_escape_string() 用在SQL语句中的字符串的转义特殊字符。
mysql_fetch_field() 返回下一个表字段的类型。
mysql_fetch_field_direct () 返回一个表字段的类型,给出一个字段编号。
mysql_fetch_fields() 返回一个所有字段结构的数组。
mysql_fetch_lengths() 返回当前行中所有列的长度。
mysql_fetch_row() 从结果集合中取得下一行。
mysql_field_seek() 把列光标放在一个指定的列上。
mysql_field_count() 返回最近查询的结果列的数量。
mysql_field_tell() 返回用于最后一个mysql_fetch_field()的字段光标的位置。
mysql_free_result() 释放一个结果集合使用的内存。
mysql_get_client_info() 返回客户版本信息。
mysql_get_host_info() 返回一个描述连接的字符串。
mysql_get_proto_info() 返回连接使用的协议版本。
mysql_get_server_info() 返回服务器版本号。
mysql_info() 返回关于最近执行得查询的信息。
mysql_init() 获得或初始化一个MYSQL结构。
mysql_insert_id() 返回有前一个查询为一个AUTO_INCREMENT列生成的ID。
mysql_kill() 杀死一个给定的线程。
mysql_list_dbs() 返回匹配一个简单的正则表达式的数据库名。
mysql_list_fields() 返回匹配一个简单的正则表达式的列名。
mysql_list_processes() 返回当前服务器线程的一张表。
mysql_list_tables() 返回匹配一个简单的正则表达式的表名。
mysql_num_fields() 返回一个结果集合重的列的数量。
mysql_num_rows() 返回一个结果集合中的行的数量。
mysql_options() 设置对mysql_connect()的连接选项。
mysql_ping() 检查对服务器的连接是否正在工作,必要时重新连接。
mysql_query() 执行指定为一个空结尾的字符串的SQL查询。
mysql_real_connect() 连接一个MySQL服务器。
mysql_real_query() 执行指定为带计数的字符串的SQL查询。
mysql_reload() 告诉服务器重装授权表。
mysql_row_seek() 搜索在结果集合中的行,使用从mysql_row_tell()返回的值。
mysql_row_tell() 返回行光标位置。
mysql_select_db() 连接一个数据库。
mysql_shutdown() 关掉数据库服务器。
mysql_stat() 返回作为字符串的服务器状态。
mysql_store_result() 检索一个完整的结果集合给客户。
mysql_thread_id() 返回当前线程的ID。
mysql_use_result() 初始化一个一行一行地结果集合的检索。
- 关系型数据库PostgreSQL

首先看一张图,mysql标榜的是最流行(most popular)的数据库,而postgresql标榜的则是最先进的(most advanced)的数据库。可以反馈出当前市场上对两款数据库的评价。流行偏重的是使用基数大,数据库的性能可以说是满足绝大部分应用场景。Postgresql的最先进则偏重技术层面,譬如更多数据类型存储支持(Array和json)、默认事务隔离级别并发性支持好、FDW(用统一的SQL,访问其他关系型数据库或者NoSQL以及一些数据库存储引擎方面的优化。
-
- PostgreSQL数据库vs MySql数据库
以下摘自知乎:
一、PostgreSQL 的稳定性极强, Innodb 等引擎在崩溃、断电之类的灾难场景下抗打击能力有了长足进步,然而很多 MySQL 用户都遇到过Server级的数据库丢失的场景——mysql系统库是MyISAM的,相比之下,PG数据库这方面要好一些。
二、任何系统都有它的性能极限,在高并发读写,负载逼近极限下,PG的性能指标仍可以维持双曲线甚至对数曲线,到顶峰之后不再下降,而 MySQL 明显出现一个波峰后下滑(5.5版本之后,在企业级版本中有个插件可以改善很多,不过需要付费)。
三、PG 多年来在 GIS 领域处于优势地位,因为它有丰富的几何类型,实际上不止几何类型,PG有大量字典、数组、bitmap 等数据类型,相比之下mysql就差很多,instagram就是因为PG的空间数据库扩展POSTGIS远远强于MYSQL的my spatial而采用PGSQL的。
四、PG 的“无锁定”特性非常突出,甚至包括 vacuum 这样的整理数据空间的操作,这个和PGSQL的MVCC实现有关系。
五、PG 的可以使用函数和条件索引,这使得PG数据库的调优非常灵活,mysql就没有这个功能,条件索引在web应用中很重要。
六、PG有极其强悍的 SQL 编程能力(9.x 图灵完备,支持递归!),有非常丰富的统计函数和统计语法支持,比如分析函数(ORACLE的叫法,PG里叫window函数),还可以用多种语言来写存储过程,对于R的支持也很好。这一点上MYSQL就差的很远,很多分析功能都不支持,腾讯内部数据存储主要是MYSQL,但是数据分析主要是HADOOP+PGSQL(听李元佳说过,但是没有验证过)。
七、PG 的有多种集群架构可以选择,plproxy 可以支持语句级的镜像或分片,slony 可以进行字段级的同步设置,standby 可以构建WAL文件级或流式的读写分离集群,同步频率和集群策略调整方便,操作非常简单。
八、一般关系型数据库的字符串有限定长度8k左右,无限长 TEXT 类型的功能受限,只能作为外部大数据访问。而 PG 的 TEXT 类型可以直接访问,SQL语法内置正则表达式,可以索引,还可以全文检索,或使用xml xpath。用PG的话,文档数据库都可以省了。
九,对于WEB应用来说,复制的特性很重要,mysql到现在也是异步复制,pgsql可以做到同步,异步,半同步复制。还有mysql的同步是基于binlog复制,类似oracle golden gate,是基于stream的复制,做到同步很困难,这种方式更加适合异地复制,pgsql的复制基于wal,可以做到同步复制。同时,pgsql还提供stream复制。
十,pgsql对于numa架构的支持比mysql强一些,比MYSQL对于读的性能更好一些,pgsql提交可以完全异步,而mysql的内存表不够实用(因为表锁的原因)
最后说一下我感觉 PG 不如 MySQL 的地方。
第一,MySQL有一些实用的运维支持,如 slow-query.log ,这个pg肯定可以定制出来,但是如果可以配置使用就更好了。
第二是mysql的innodb引擎,可以充分优化利用系统所有内存,超大内存下PG对内存使用的不那么充分,
第三点,MySQL的复制可以用多级从库,但是在9.2之前,PGSQL不能用从库带从库。
第四点,从测试结果上看,mysql 5.5的性能提升很大,单机性能强于pgsql,5.6应该会强更多.
第五点,对于web应用来说,mysql 5.6 的内置MC API功能很好用,PGSQL差一些。
另外一些:
pgsql和mysql都是背后有商业公司,而且都不是一个公司。大部分开发者,都是拿工资的。
说mysql的执行速度比pgsql快很多是不对的,速度接近,而且很多时候取决于你的配置。
对于存储过程,函数,视图之类的功能,现在两个数据库都可以支持了。
另外多线程架构和多进程架构之间没有绝对的好坏,oracle在unix上是多进程架构,在windows上是多线程架构。
很多pg应用也是24/7的应用,比如skype. 最近几个版本VACUUM基本不影响PGSQL 运行,8.0之后的PGSQL不需要cygwin就可以在windows上运行。
至于说对于事务的支持,mysql和pgsql都没有问题。
-
- PostgreSQL在Centos7下面的安装
登录postgresql官网选择对应系统后及需要安装版本之后,官网会给出通过yum安装的命令,按照命令一步步执行即可。下面以安装最新版本Postgresql 10为例进行简要说明:
https://www.postgresql.org/download/linux/redhat/
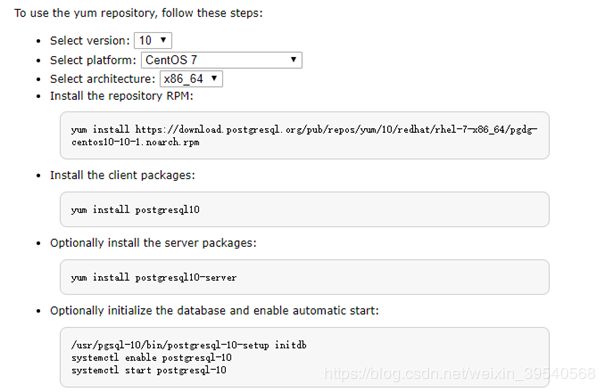
-
- PostgreSQL在Centos7下面配置使用
A、设置环境变量
# vim /etc/profile.d/prs7000env.sh
export PATH=/usr/pgsql-10/bin:$PATH
export LD_LIBRARY_PATH=/usr/pgsql-10/lib:$LD_LIBRARY_PATH
# source /etc/profile.d/prs7000env.sh
B、重启服务
# systemctl restart postgresql-10
C、修改用户密码
yum安装postgresql,默认会建一个名为”postgres”的系统账号,用于操作PogreSQL数据库。(PostgreSQL只支持在postgres的账户下操作,root用户无权操作)
# su - postgres
切换用户后,提示符变更为“-bash-4.2$”;同时数据库中也会生成一个名为”postgres”的数据库用户,且密码已自动生成;PostgreSQL在数据库用户同名的系统账号下登录免密;
#psql -U postgres
进入数据库后修改密码;
postgres=# alter user postgres with password 'nari'
D、简单使用
1)创建用户
postgres=# create user jeremiah with password 'nari';
2)创建数据库同时指定数据库的所有者
postgres=# create database testdb owner jeremiah;
3)数据库赋权未赋权则账户只能登录控制台
postgres=# grant all privileges on database testdb to jeremiah;
4)退出使用新建账号登录新建数据库
-bash-4.2$ psql -U jeremiah -d testdb

此处登录若提示对用户的认证失败,则需要更改配置文件,将下面文件中的图示位置处由原来的peer给为md5.
vim /var/lib/pgsql/10/data/pg_hba.conf
 重启数据库服务:
重启数据库服务:
Systemctl restart postgresql-10
5)创建表
postdb1=> create table tb1(
id int primary key,
name VARCHAR(20),
salary real
);
6)插入数据
postdb1=> insert into tb1(
id, name, salary)
values(
101, 'Mike', 5000.00
);
7)查询
postdb1=>select * from tb1;
-
- PostgreSQL在Centos7下C++的数据库连接方式
C/C++连接PostgreSQL,使用libpqxx库,这是官方的C++客户端API用于连接PostgreSQL。
通过开发库的使用,可以比较快捷的进行C++下PostgreSql数据库实例的连接,以下来自于参考网址:http://www.yiibai.com/html/postgresql/2013/080894.html
A、安装
libpqxx最新版本的可供下载链接下载libpqxx。所以下载的最新版本,并遵循以下步骤:Download Libpqxx.
wget http://pqxx.org/download/software/libpqxx/libpqxx-4.0.tar.gz
tar xvfz libpqxx-4.0.tar.gz
cd libpqxx-4.0
./configure
make
make install yiibai.com
注意:若执行./configure提示如下错误,则需要先安装PostgreSql的开发环境。

yum –y install postgresql-devel
B、编译测试

编译:
#g++ test.cpp -lpqxx -lpq -o test
运行:
./test
登录数据库查询对应记录,成功写入。
以下是重要接口例程可满足工作需求与PostgreSQL数据库的C/C + +程序:
| S.N. |
API & 描述 |
| 1 |
pqxx::connection C( const std::string & dbstring ) 这是将用于连接到数据库一个类型定义。这里dbstring提供所需要的参数,例如连接到数据库 dbname=testdb user=postgres password=pass123 hostaddr=127.0.0.1 port=5432. 如果连接设置成功,那么它创建C与连接对象提供各种有用的函数公共函数。 |
| 2 |
C.is_open() is_open()是一个连接对象的公共方法,并返回布尔值。如果连接处于活动状态,则此方法返回true,否则返回false。 |
| 3 |
C.disconnect() 使用此方法打开的数据库连接断开。 |
| 4 |
pqxx::work W( C ) 这是一个类型定义将用于创建一个事务对象,使用C连接方式,最终将被用于执行SQL语句的事务模式。 如果交易对象被创建成功,那么它被分配到变量W,这将被用来访问相关的事务性对象的公共方法。 |
| 5 |
W.exec(const std::string & sql) 这种从事务对象的公共方法将被用于执行SQL语句。 |
| 6 |
W.commit() 这种从事务对象的公共方法将用于提交事务。 |
| 7 |
W.abort() 这种从事务对象的公共方法将用于回滚事务。 |
| 8 |
pqxx::nontransaction N( C ) 这是一个类型定义,被用来创建使用C连接方式,最终将被用于在非事务性模式下执行SQL语句的非事务性对象。 如果交易对象被创建成功,那么它被分配到变量N将用于访问相关的非事务性对象的公共方法。 |
| 9 |
N.exec(const std::string & sql) 从非事务性对象的公共方法将被用于执行SQL语句,并返回一个结果对象,这实际上是一个的迭代器返回的记录。 |
- 非关系型数据库MongoDB
MongoDB是一个基于分布式文件存储的数据库,由C++语言编写。其旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
MongoDB的主要功能特性有:
1)面向集合存储,易存储对象类型的数据;
2) 支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言;
3) 文件存储格式为BSON(一种JSON的扩展);
4) 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 综述
若考虑稳定开发,推荐使用mysql/mariadb,数据库本身性能足以满足当前业务需
要,后续可以配合中间件进行数据库的分布式开发。
若考虑进行新技术的尝试,可以考虑PostgreSQL数据库。
不建议切换非关系型数据库。