Coursera北大《数据结构基础》之概论
刷书有点看不下去了,打算换课程试试。
Mooc上有一样的内容,更喜欢Coursera。
本文基于Coursera北大课程《数据结构基础》,所有文中非标注图片均来自课件,侵删
程序 = 数据结构 + 算法
1. 问题求解
数据结构与算法是围绕问题求解进行的。那么什么是问题求解的过程呢?
我们要明确编写计算机程序的目的是为了解决实际应用问题。面对一个问题,首先,我们要将其抽象出来,抓住问题的核心,建立问题模型;伴随着问题会有一些数据出现,我们需要使用合适的数据结构来表示数学模型;在数据模型的基础上,我们使用合理的算法进行设计。
这里要注意的一点是,数据结构是离不开算法的,其由逻辑、存储和运算三个方面组成。通常来说这里的“运算”就是指算法。通常程序设计中的算法和数据结构抽象是可以一同进行的。

课程中举了一个《过河游戏》的例子,刚好是我小时候很爱玩的一个游戏(第二关怪兽吃人简直是童年阴影),每一关都挺好玩的,值得尝试,链接如下:
http://www.e-bobo.net/php/game1.php?ID=472&Page=6&Name=%E9%81%8E%E6%B2%B3%E9%81%8A%E6%88%B2
第一关如下:
狼不能和羊单独在一起;羊不能和菜单独一起;人作为限制条件可以阻止A被B吃掉(人必须在船上)。目标是一顿操作要把狼羊菜都运到对岸。
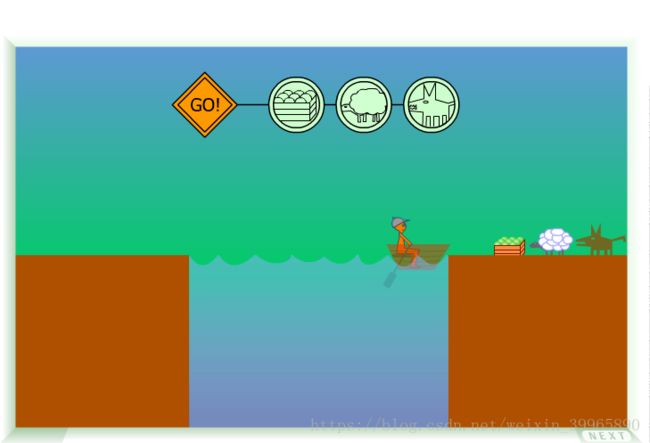
这个问题中,模型就是人-狼-羊-菜的图模型:
不合理状态有:人狼、狼羊、羊菜、人菜、狼羊菜、人。
最终状态为(右岸)空。
步骤如下:

我们可以把它转化为一个矩阵求最短路径的问题:

因为这个问题以后会详细说,这里就不展开了。
2. 数据结构与抽象数据类型
结构=实体+关系
数据结构=逻辑关系+数据存储方法+运算【三者缺一不可】
整个数据结构以逻辑关系为主线来组织。
2.1 数据结构的逻辑关系
2.1.1 线性结构
线性表(表、栈、队列、串等):最简单最通用的结构
2.1.2 非线性结构
树(二叉树,Huffman树,二叉检索树等)
图(有向图,无向图等)
2.2 数据结构的存储结构
是从逻辑结构到物理存储空间的映射,主要有顺序(数组形式,连续存储)、链接(指针的地址指向关系,十分重要,尤其对非线性结构)、索引(对数据建立索引表,通过表找到数据存储地址)、散列(特殊的索引结构,通过关键码映射快速找到存储空间)四种形式组成,其中前两种形式是基础。
这里注意一点,访问内存任意一个地址所需要的时间都是相同的。
对于逻辑结构(K,r),其中r∈R,对结点集K建立一个从K到存储器M的单元的映射:K→M,对于每一个结点j∈K都对应一个唯一的连续存储区域c∈M。

具体例子如上图所示,有一个长度为3的整型数组a,如果a[0]的起始地址是4,那么相对应地,a[1]就是8,a[2]是12(每一个整型数值占4字节)。
2.3 抽象数据类型(Abstract Data Type, ADT)
数据如何存放在内存里并不是重点,重点是如何表示。抽象数据类型是随着模块化和面向对象方法发展起来的。
ADT主要关乎逻辑和运算两个方面,和物理存储没有关系。
一个抽象数据结构二元组可以表达为:<数据对象D,数据操作P>。
通常我们先定义逻辑结构(数据对象及其关系),再定义运算(数据操作)。
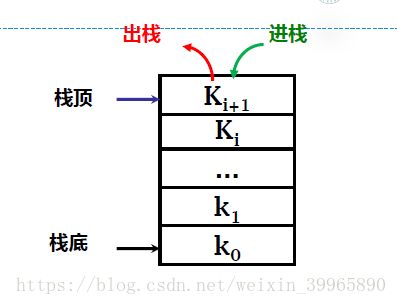
这里举了一个栈的ADT的例子:
栈的逻辑结构是线性表,操作特点是限制访问端口,也就是说,栈必须是按照一定逻辑顺序排列(如下图所示)。栈遵循的是先进后出(出栈:读pop;入栈:写push),不允许从中间地址进行数据操作。
3. 算法特性及分类
算法是对特定问题求解过程的描述,是有限的指令。
3.1 算法特性
(1)通用性
算法对这一类问题都适用。例如求取1+2+3+4的和,我们可以用(1+4)*(4/2)=10求得,那么推广至:n个从a开始到b结束的整数的连加(n为偶数)则为(a+b)*(n/2)。
(2)有效性
算法是有限条指令序列,由一系列具体步骤组成。每一步都必须是有效的。
(3)确定性
每一步都必须是明确的,可以获得明确的结果,而不是模棱两可的描述。
(4)有穷性
有限步数内结束。
3.2 算法的分类
(1)穷举法
就是挨个访问、搜索寻找答案
(2)回溯、搜索
树和图遍历。通过一些已知的不可能情况排除穷举法中的一些例子,避免资源浪费
(3)递归分治
二分法、快排、归并排序
(4)贪心法
前提是数据必须具有贪心特质,在每次一求解中都贪心最优解,得到的解的集合也是最优的。例如Huffman编码树、最短路径Dijkstra算法和最小生成树Prim算法等
(5)动态规划
初高中学的那个
4. 算法效率与度量
设计一个算法后,我们要关注算法的时间和空间效率,尤其是时间效率(即该算法能不能在规定时间内完成任务)。
4.1 大O表式法(时间效率)
(1)定义
设f和g是定义域为自然数、值域为非负实数集的函数。如果存在正数c和n0,使得对于任意n>=n0,都有f(n)<=cg(n)【即f(n)总在集合O(g(n))中】,则称f(n)是O(g(n))的,或f(n)=O(g(n))。
(2)相关符号
大O表示一个函数增长率的上限,这里需要注意一个函数的增长率上限可能不止一个,我们需要尽量寻找最逼近的那个。
除了大O表式法,我们还用Ω来表示一个函数增长率的下限,有大Ω表式法。当同时表示上限和下限时,我们用Θ。在很多数据结构教材里,人们会把ΩΘ混用。一般教材中只会介绍大O表式法,当遇到其它两种时,用类比思想考虑即可【即找到最紧的下界用大Ω表式法;当上限和下限相同时,用大Θ表式法:有c1和c2把f夹在中间】。
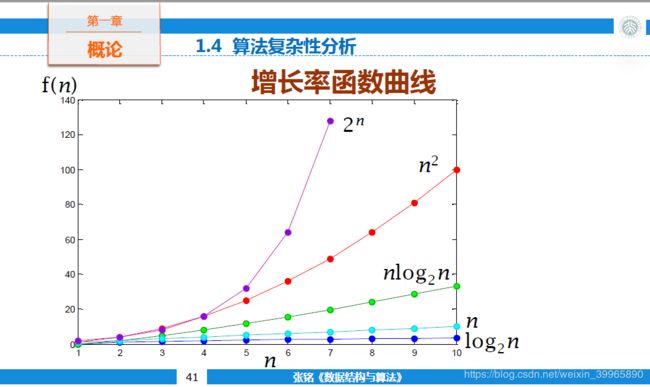
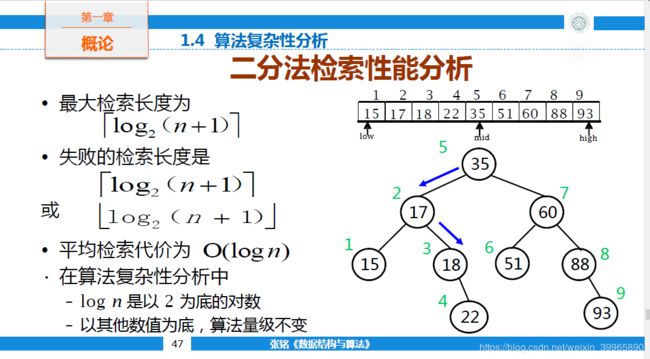
(3)关于n 我们默认n0之前的n是小样本的,因此并不关心n0之前的效率问题。 (4)大O表式法的单位时间 以下简单的语句可以被视为单位时间: (5)大O表式法运算法则 加法规则: 例如 中,O(f(n))=n^3 加法规则在顺序结构(如if, switch)中适用 乘法规则: 适用于for, while, do-while结构 例如如下代码块的大O复杂度就是n*n。 如图所示【上图摘自Coursera北京大学《数据结构与算法》】,如果能找到log2n的增长率算法就很好了。但是在做搜索引擎等算法时,我们希望O(f)=O(1)的,需要特殊的算法。 通常在设计一个算法时,我们需要考虑最好(例如排序中的插入排序)、最坏(压力测试)和平均情况(统计意义下算法大致性能,例如概率期望值),然后进行组合考虑。 在决策树下,每下降一层的性能都用log以2为底来衡量。 在上图【摘自Coursera北京大学《数据结构与算法》】的例子中,我们使用二分法检索,用到了二叉树。最大检索长度为log2(n+1) 二分查找的基本思想是将n个元素分成大致相等的两部分,去a[n/2]与x做比较,如果x=a[n/2],则找到x,算法中止;如果x 时间复杂度无非就是while循环的次数! 总共有n个元素, 渐渐跟下去就是n,n/2,n/4,....n/2^k,其中k就是循环的次数 由于你n/2^k取整后>=1 即令n/2^k=1【二分只能到1,之后要结束】 可得k=log2n,(是以2为底,n的对数) 所以时间复杂度可以表示O()=O(logn) 大多数时候数据结构的设计是先于算法设计的,但是也有特殊情况,例如某些经典问题需要特定算法解决,我们可能为了能实现这种算法而用特定数据结构来表示。 在设计数据结构时,要注意数据结构的可扩展性,即在数据输入规模发生变化时,数据结构是否能够适应并依然能够进行问题求解。
![]()
![]()
![]()
for(i=0;i4.2 增长率函数曲线
4.3 二分法检索性能分析
---------------------
作者:frances_han
来源:CSDN
原文:https://blog.csdn.net/frances_han/article/details/6458067
版权声明:本文为博主原创文章,转载请附上博文链接!4.4 数据结构和算法的选择