大数据利用hive on spark程序操作hive
hive on spark
作者:小涛
Hive是数据仓库,他是处理有结构化的数据,当数据没有结构化时hive就无法导入数据,而它也是远行在mr程序之上的基于磁盘计算,然而我们今天来让hive远行在spark上,基于内存计算,在基于内存来让hive远行在内存上这样就比以前的快个几十倍,现在让我们一起来看看hive on spark吧!
首先要说说hive他的一些元数据信息是保存在mysql里面的,所以我们首先要安装mysql服务,而真实的数据是存储在hdfs中的,本文作者的大数据集群hadoop 2.8.7 spark 2.3.0
Scala 2.11 jdk 1.8.45 hive 1.2.2
安装:mysql通过yum -y install mysql mysql-server

启动:mysql服务service mysqld start,当启动好以后可以在命令行直接登录mysql了,输入mysql,但是这样是不安全的我们需要给mysql初始化密码跟设置密码
在命令行输入/usr/mysql_secure_installation,通过这个来设置密码
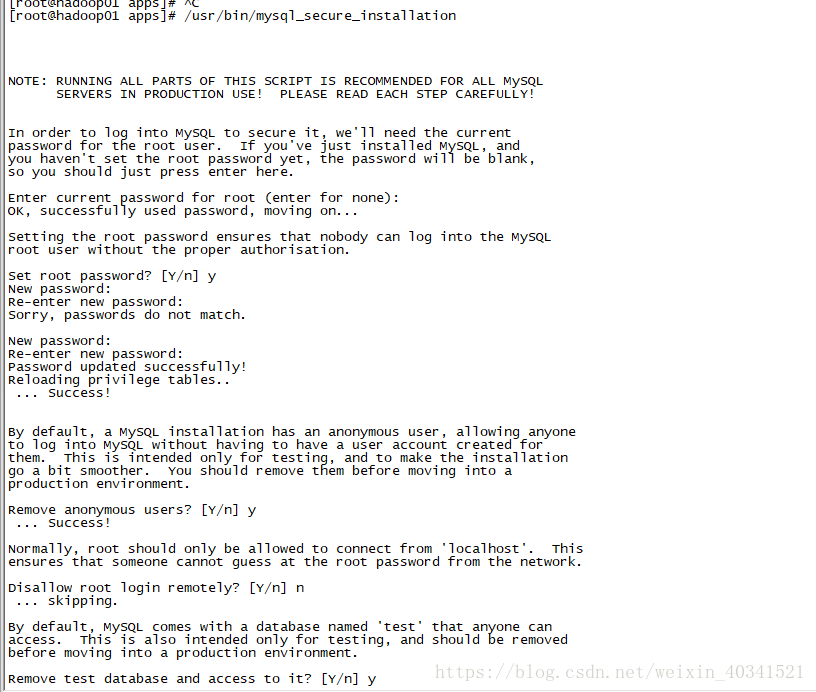
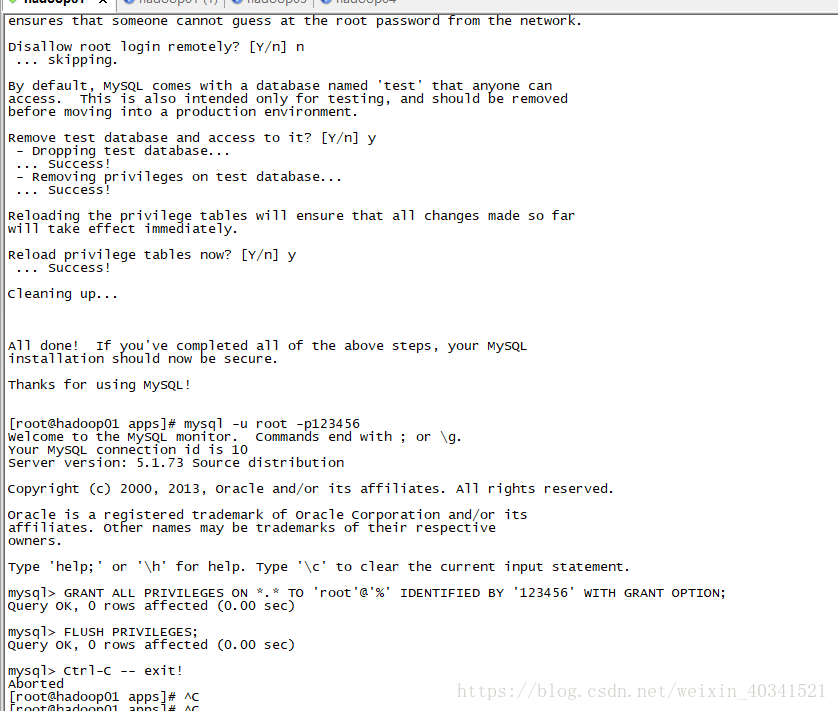
本文作者通过以上操作就把mysql的密码初始化了,密码是root123
通过mysql -u root -proot123就可以登录成功了

然后我们通过navicat来连接mysql的服务,这个时间可能连接不上服务,我们需要给相应的用授权
GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘root123’ WITH GRANT OPTION;
FLUSH PRIVILEGES;
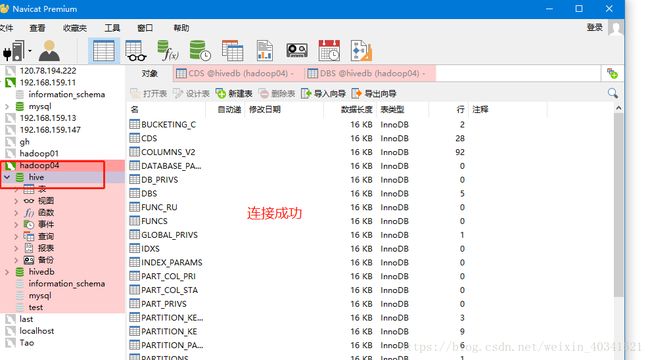
如下图就连接成功了mysql
现在我们解决hive的jar包,通过tar -zxvf hive-1.2.2-bin.tgz -C /apps/hive/
然后进入hive的目录中找到hive的配置文件,通过vim 来新建hive的元数据信息库的配置文件,vim hive-site.xml

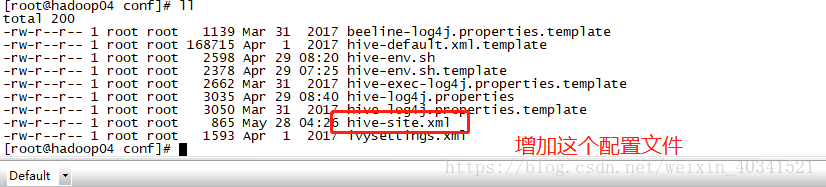
vim hive-site.xml的具体配置信息如下
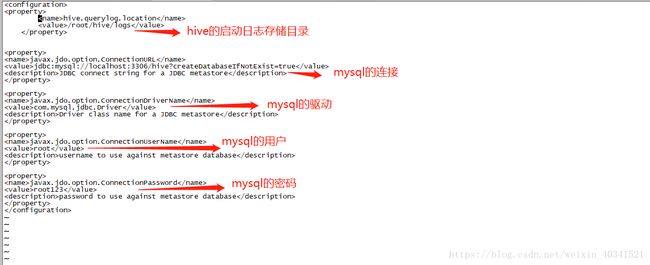
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop04:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
root123
password to use against metastore database
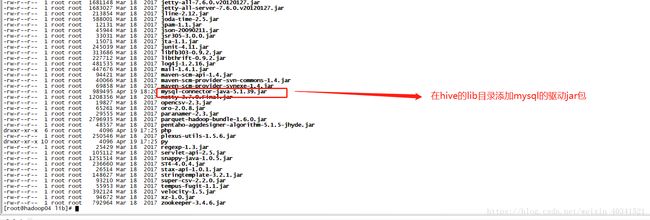
因为hive在启动跟用的时间会连接mysql服务,所有我们需要将mysql的驱动jar包拷贝到hive的lib目录下cp /etc/java/mysqljar/ mysql-connector-java-5.1.39.jar /apps/hive/lib/
这个时间我们就可以启动hive了,进入bin目录下,通过nohup ./hiveserver2 &在后台启动hive的服务端我们就可以任意通过各种客户端去连接操作hive了
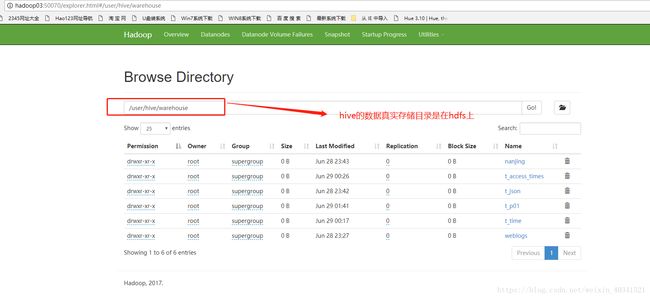
我们可以在hdfs行hive 的具体存储数据的路径跟具体数据
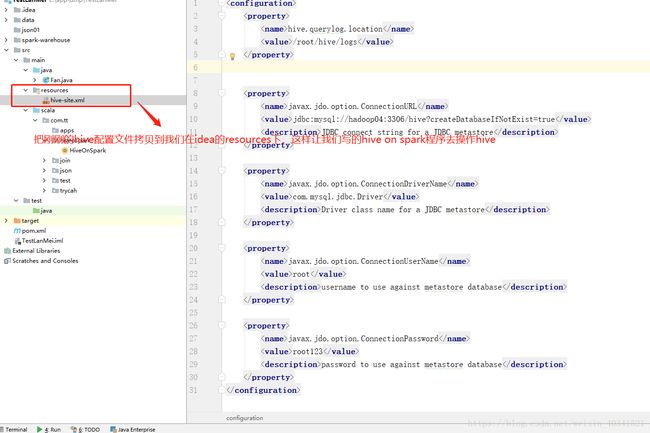
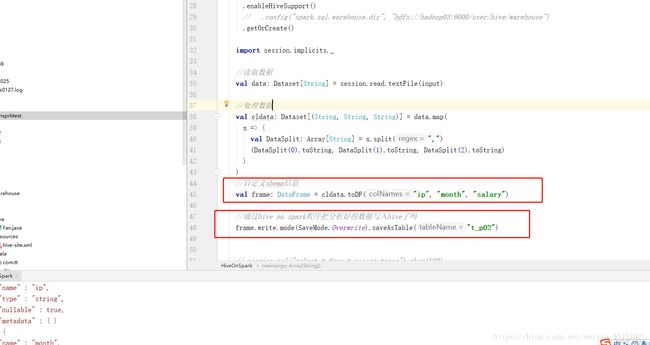
我们在我们的开发工具idea中新建一个项目叫hive on spark ,这个时间我们通过spark程序去操作hive了,需要把刚刚的hive配置文件拷贝到配置文件下如下图所示
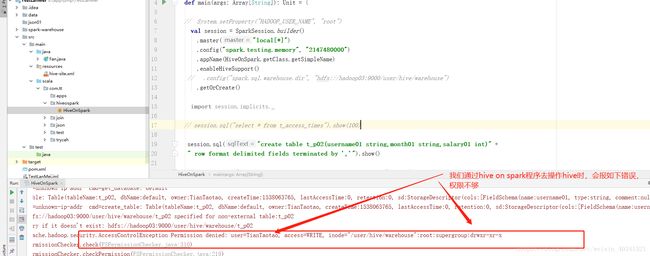
我们通过spark程序来新建一个表这个时间会报错,说用户的权限不足,这个时间我们需要伪装自己本机的用户为root用户去操作hive,报错如下
我们通过hadoop中的一些参数来伪装自己的身份,如图
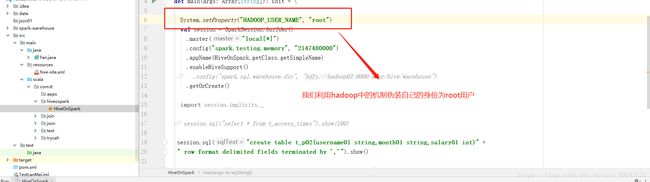
这个时间可以可以创建成功了这个表,如图代码中有t_p02表的创建,代码远行成功,我们看看是否远行成功了,去hdfs的存储目录就知道了,如下
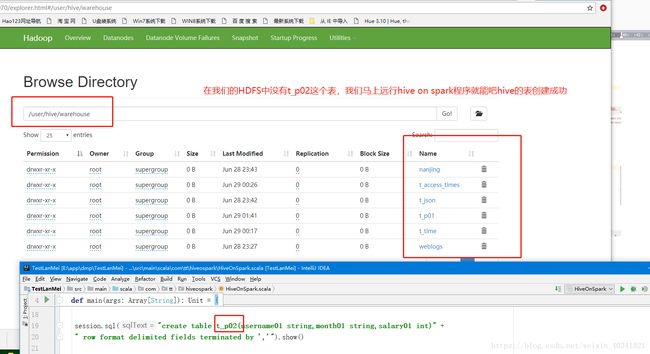
成功了我们的hive on spark程序
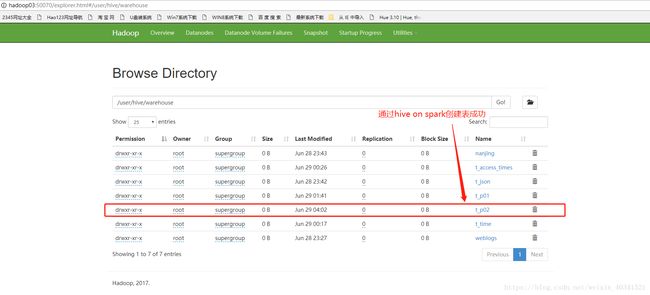
上面上创建表成功,我们来导入数据吧,比如
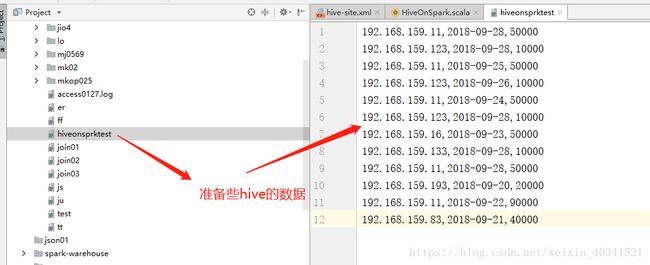
192.168.159.11,2018-09-28,50000
192.168.159.123,2018-09-28,10000
192.168.159.11,2018-09-25,50000
192.168.159.123,2018-09-26,10000
192.168.159.11,2018-09-24,50000
192.168.159.123,2018-09-28,10000
192.168.159.16,2018-09-23,50000
192.168.159.133,2018-09-28,10000
192.168.159.11,2018-09-28,50000
192.168.159.193,2018-09-20,20000
192.168.159.11,2018-09-22,90000
192.168.159.83,2018-09-21,40000
通过spark程序把原始数据处理了,就写入hive如下图代码
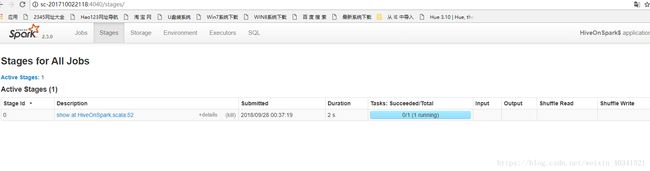
Hive on spark 的远行图
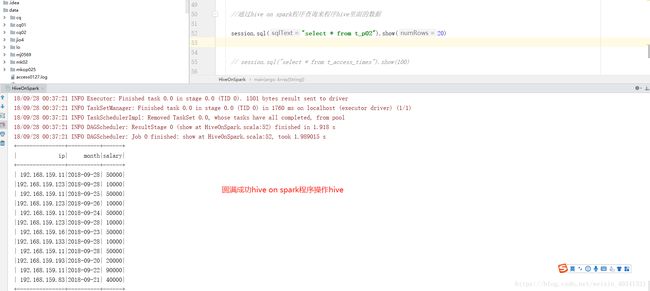
我们在在读取刚刚的数据,就这样我们的hive on spark程序就圆满成功了
其实hive我们完全可以不用hive的服务来支持,我们可以完全脱离hive来利用spark操作hive,敬请期待,下篇博客文章的出现,如果喜欢楼主了,记得为我点赞,谢谢,有什么问题请留言,谢谢!!!