Openpose win10编译(Visual Studio2019)
Openpose win10编译(Visual Studio2019)
- 前言
- 准备工作
- 需求工具
- 安装CUDA及cudnn
- 编译VS工程
- 项目测试
前言
Openpose 地址:Openpose主页
使用git clone https://github.com/CMU-Perceptual-Computing-Lab/openpose下载openpose
参考博客:https://blog.csdn.net/zb1165048017/article/details/82115724,https://blog.csdn.net/m0_37638031/article/details/78896818
【注】如果使用git时下载速度过慢,可以将openpose代码fork到国内的码云中后再clone代码
git clone https://gitee.com/aydon/openpose.git
准备工作
需求工具
CMake,Visual Studio 2019,CUDA,cudnn
在编写此文章时使用的版本为:
CMake:3.15.0
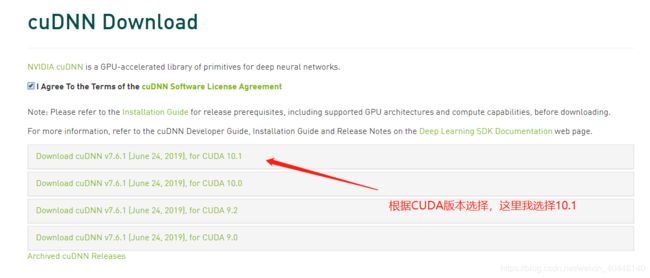
CUDA:10.1 CUDA10.1下载


cudnn:cudnn-10.1-windows10-x64-v7.6.1.34,戳这里
安装CUDA及cudnn
CUDA下载完成后,点击执行.exe文件,接下来一直选择下一步即可。
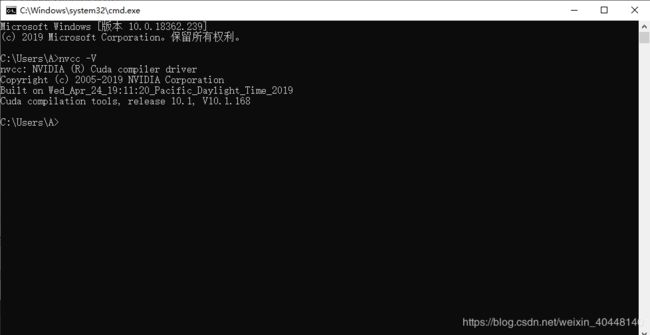
安装完成后打开cmd,输入nvcc -V,显示如下则安装成功。最后一行显示版本号,图中是10.1.
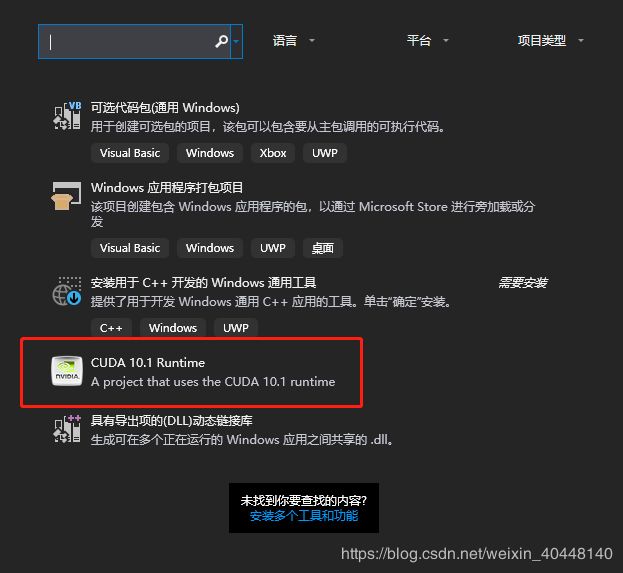
打开Visual sutdio新建工程,选择CUDA模块
复制以下代码,替换kernel.cu下的内容
// CUDA runtime 库 + CUBLAS 库
#include "cuda_runtime.h"
#include "cublas_v2.h"
#include 右键解决方案名打开属性,在VC++目录中加入变量:
包含目录为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
库目录为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib
【注】如果是默认安装CUDA,那么目录就是这个。如果自定义安装的话,选择你安装时的路径名。
配置属性–>链接器–>输入–>附加依赖中添加库文件:
cublas.lib
cuda.lib
cudadevrt.lib
cudart.lib
OpenCL.lib
cudnn.lib
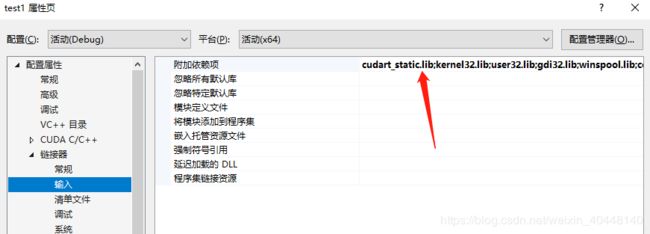
添加完成后不要忘记点击应用按钮。
按F5运行,得到结果,则CUDA安装成功。
接下来安装cudnn
将解压下来的文件中的所有内容(即cudnn中的这三个文件夹)复制到CUDA文件夹中即可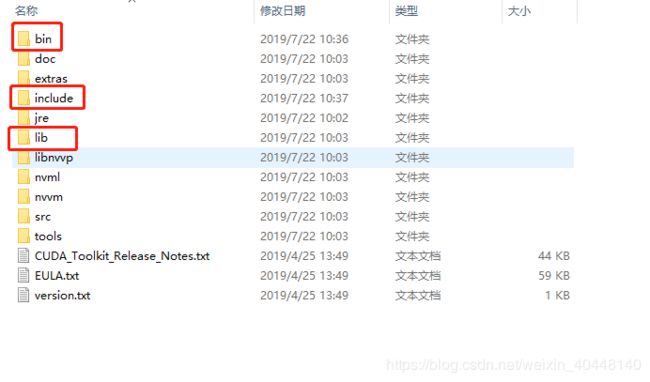
复制代码,替换kernel.cu中的内容
#include 右键选择解决方案名,选额CUDA C/C++中的Device将第一个修改为是
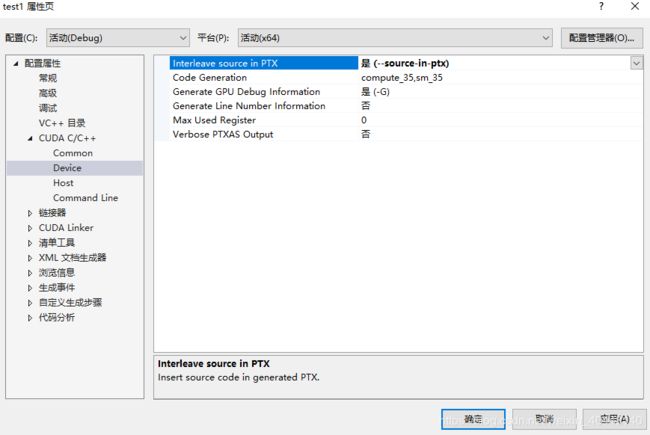
点击F5运行代码,成功则安装完成。
编译VS工程
在openpose文件夹中创建bulid文件夹:
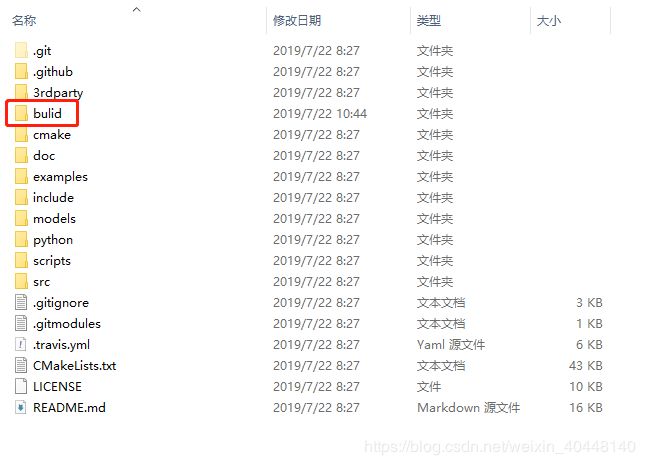
设置CMake路径
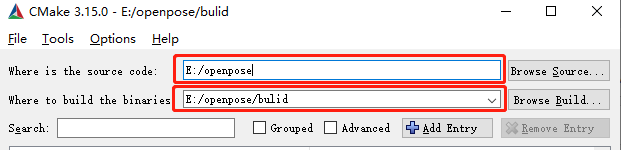
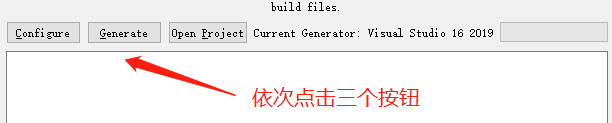
【注】如果第一次点击Configure爆红的话是正常现象,在重新点击一个Configure就可以了,直到全部变白为止
如果点击Open Project无反应的话就找到openpose下的bulid文件夹中的OpenPose.sln,并用Visual Studio 2019打开

打开解决方案,选择ALL_BUILD,右键点击生成
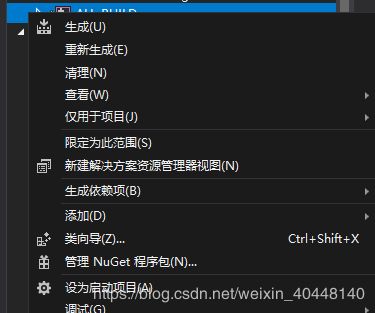
项目测试
选择Examples文件夹下的其中一个例子,右键设为启动项后点击使用F5运行