创建线程池
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
其中参数的含义为
corePoolSize 为核心线程梳理
corePoolSize 个线程会一直存在线程池之中,直到 workQueue 所有任务都被执行。
maximumPoolSize 最大线程梳理
其中 corePoolSize 不能小于 0
maximumPoolSize 不能小于1
maximumPoolSize 不能小于 corePoolSize
keepAliveTime 非核心线程最大存活时间
如果线程池中的线程,超出 corePoolSize ,多出的线程执行完任务后将会被回收。
keepAliveTime 为该线程空闲时,最长存活时间。
unit 时间单位
workQueue 任务队列
当线程池 corePoolSize 个线程全部都在运行时,任务会被放到该队列
threadFactory 线程工厂
创造线程的工厂
handler 处理无法执行的任务(任务队列满,也无法创建新的线程)
无法被执行的任务,通过这个handler处理
添加任务到线程池
executorService.execute( Runnable)
executorService.submit( Runnable)
Executors 框架提供的方式
Executors 提供了四种创建线城市的方式
分别是
Executors.newSingleThreadExecutor();
创建单线程池。
corePoolSize = maximumPoolSize = 1
Executors.newCachedThreadPool()
最小为0 ,最大为Integer.MAX_VALUE 个线程的线程池
corePoolSize = 0
maximumPoolSize = Integer.MAX_VALUE
Executors.newFixedThreadPool(corePoolSize);
创建 corePoolSize 个核心线程的线程池
corePoolSize = maximumPoolSize = corePoolSize
Executors.newScheduledThreadPool(corePoolSize)
最小为corePoolSize ,最大为Integer.MAX_VALUE 个线程的线程池
corePoolSize = corePoolSize
maximumPoolSize = Integer.MAX_VALUE
创建线程
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
备注
executorService.submit() 会调用 execute
代码在 ThreadPoolExecutor 父类 AbstractExecutorService 中可以查看
public Future submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
流程图如下
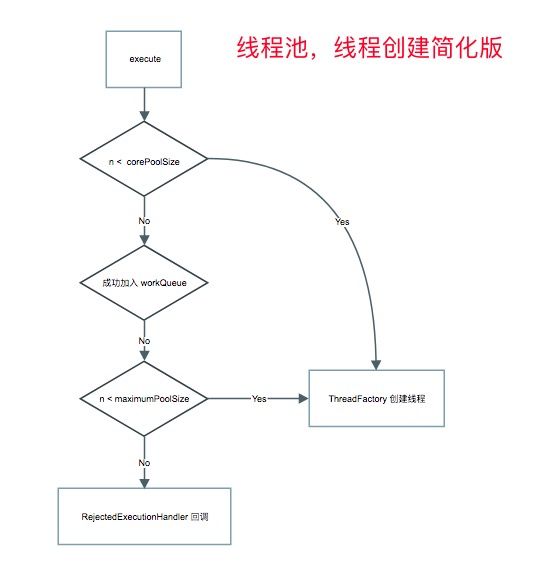
任务执行
ThreadPoolExecutor 中的线程都被封装到 Worker 类之中。
一个 Worker 可以认为就是一个线程。
Worker 被存放到一个叫做 workers 的 HashSet
private boolean addWorker(Runnable firstTask, boolean core) {
……
}
方法创建 Worker
addWorker 方法可以分为两个部分
第一部分
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
该部分通过以下条件判断是否可以继续创建线程
1、线程池是否还在运行
2、当前线程数量是否超过最大线程梳理
3、如果可以创建线程 ctl 对象(AtomicInteger)+1
备注
ctl 对象是用来记录当前线程数量,线程池运行状态的 AtomicInteger 。
AtomicInteger 一共 32 为存储空间
前 3 位代表线程池运行状态,后面 29 位表示能线程数量
第二部分
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
第二部分代码创建 Worker 对象,并且执行了 Worker 中 thread.run() 方法。
通过 Worker 构造函数,可以得知:thread.run() 最终执行的是 Worker 的 run 方法。
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
而 work.run 中会调用 ThreadPoolExecutor 的 runWorker 方法
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
……
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
runWorker()方法最终会调用我们 executorService.execute(runnable) 中的 runnable.run()
以上流程图如下

线程回收
上文中说过 ThreadPoolExecutor 会维护 corePoolSize 个线程常驻(或者不到 corePoolSize)。
超出 corePoolSize 不到 maximumPoolSize 的线程在执行完毕任务以后,就会被回收。
线程伴随的 Worker 创建以后,在 runWorker(Worker w) 方法中 开始执行一个名字为 firstTask 的 Runnable 。
然后在 runWorker(Worker w) 一直调用 getTask() 从 workQueue 中获取新的 Runnable 执行。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
如果 getTask 中返回了 null ,线程将会执行完毕,进行回收。
如果 getTask 在阻塞 比如在
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
或者返回了一个 Runnable 线程将会继续执行。
流程图如下:

任务队列 workQueue 的维护
[创建线程] 有提到,当线程池线程超过核心线程时,会尝试将任务放到。如果添加不成功再试图创新新的线程。核心方法是 BlockingQueue 的 offer(E e) 方法
BlockingQueue workQueue;
……
workQueue.offer(command)
BlockingQueue 本身是一个接口,线程池中使用的 BlockingQueue 子类有
SynchronousQueue (newCachedThreadPool)
LinkedBlockingQueue (newFixedThreadPool)
LinkedBlockingQueue (newSingleThreadExecutor)
DelayedWorkQueue (newScheduledThreadPool)
-
其中 newFixedThreadPool 和 newSingleThreadExecutor 使用 LinkedBlockingQueue ,并且 corePoolSize = maximumPoolSize 。
在线程数量到达corePoolSize 以后的任务都会被存在 workQueue 之中。 直到 LinkedBlockingQueue 对了满为止。 LinkedBlockingQueue 默认容量为 Integer.MAX_VALUE -
newCachedThreadPool 创建的线程池。corePoolSize = 0,maximumPoolSize Integer.MAX_VALUE 。
SynchronousQueue 本身没有什么容量 offer() 往queue里放一个element后立即返回, 如果碰巧这个element被另一个thread取走了,offer方法返回true,认为offer成功; 否则返回false 所以 SynchronousQueue 可以重复利用存活的线程,在无法使用存活线程执行任务时 创建新的线程。 newCachedThreadPool 创建的线程,在没有任务可以执行的时候,会回收 newScheduledThreadPool 创建的线程池,corePoolSize < maximumPoolSize = Integer.MAX_VALUE 。使用了 DelayedWorkQueue 控制
DelayedWorkQueue 是一个无界队列,初始大小为 16 ,
可以自增长,最大为 Integer.MAX_VALUE。
ScheduledThreadPoolExecutor 提供了一些不同于其他线程池的功能,这里不做研究。
有兴趣的可以看下其他人的研究,比如 深入理解Java线程池:ScheduledThreadPoolExecutor