AInnoFace:Accurate Face Detection for High Performance(论文阅读笔记)
摘要
随着深度卷积神经网络(CNNs)的发展,人脸检测技术得到了长足的发展。如何提高微小人脸的检测性能是近年来研究的核心问题。为此,近年来的许多工作提出了一些具体的策略,重新设计了体系结构,并引入了新的用于微小目标检测的损失函数。在这篇报道中,我们从流行的单阶段RetinaNet[20]方法开始,应用一些最新的技巧来获得高性能的人脸检测器,即AInnoFace。具体来说,我们应用IoU损失函数[45进行]回归,采用两步分类和回归进行检测[4],修改了基于data-anchor-sampling的数据增强[32]进行,利用max-out操作[54]用于分类并采用多尺度测试策略进行推理[54]。因此,提出的人脸检测方法在最流行和最具挑战性的人脸检测基准WIDER face[43]数据集上实现了最先进的性能。
1 引言
人脸检测是计算机视觉中一个非常重要的领域,在人脸识别、情绪分析、视频监控等诸多领域都有重要的应用。给定任意一张图像,人脸检测的目的是确定图像中是否存在人脸,如果存在,则返回每个人脸的图像位置和范围。人脸检测的最新问题是如何提高非受限场景下的检测性能。由于在真实图像中检测人脸存在许多困难,包括遮挡、尺度变化显著、光照条件不同、姿态各异、表情丰富等。为了解决这一问题,人们进行了大量的工作,随着深度卷积神经网络的发展取得了很大的进展。例如,近年来,在具有挑战性的WIDER Face数据集[43]上,平均精度(AP)性能已经从40%提高到90%。
为了提高在存在大量小人脸的非限制场景下人脸检测的性能,一些工作[40,42,48,24,44]将传统方法(如DPM中的基于级联机制和基于部件的方法)与深度学习方法(如CNN)相结合进行人脸检测。许多工作[57,14,23]基于Faster R-CNN[27]和SSD[21]检测器,利用人脸区域周围的上下文信息来寻找微小的人脸。有几项工作[3,4,47,33]重新设计了现代物体检测体系结构,以便更好地检测微小的人脸。一系列的工作[35,37,54,56,46]提出了将一些针对微小人脸的特殊策略转化为通用的目标检测方法,以提高人脸检测的性能。有许多工作[32,51,16]提出了一些新的数据增强,用于微小的人脸,以提高性能。有文献[36,55]引入特征图的注意机制,将注意力集中在人脸区域,提高检测性能。
在这项工作中,我们首先修改了流行的单阶段RetinaNet[20]方法,将人脸检测作为我们的基线模型。然后在此基础上应用了一些最新的技巧,开发了一种高性能的人脸检测器,即AInnoFace:(1)采用两步分类和回归进行检测;(2)利用(IoU)损失函数进行回归;(3)对基于data-anchor-sampling的数据增强进行修改用于训练;(4)利用max-out操作以获取更鲁棒的分类;(5)采用多尺度测试策略进行推理。因此,我们在具有挑战性的人脸检测基准WIDER Face[43]数据集上实现了一些最新的AP结果。
2 相关工作
2.1 传统方法
人脸检测自20世纪90年代出现至今,由于其广泛的实际应用而受到广泛的研究。Viola和Jones的开创性工作[34]使用Haarlike特性和AdaBoost策略来训练几个级联的人脸检测器,在一些简单和固定的场景中,在准确性和效率之间实现了非常好的权衡。之后,后续的工作[2,18]通过开发更高级的特性和更强大的分类器取得了很大的进展。除了增强级联方法外,有几项研究[39,58,40]将另一个著名的可变形部件模型(Deformable Part Model, DPM)[22]框架引入人脸检测任务领域,该框架通过建模可变形部件之间的关系来检测人脸,在一些简单的应用场景中取得了很好的性能。然而,这些传统的人脸检测器在复杂的场景中是不可靠的,因为它们依赖于非健壮的手工特征和分类器。
2.2 深度学习方法
‘深度学习方法极大地推动了人脸检测领域的最新进展,基于cnn的人脸检测器在最近几年取得了最高的性能。基于级联CNN的方法[15,26]分别或联合训练一系列CNN模型进行人脸检测,同时达到了很好的精度和效率。在此基础上,MTCNN[48]和PCN[30]在级联式结构下,通过多任务学习,从粗到精地检测五个人脸landmarks,预测人脸角度。Faceness[42]根据人脸部位的空间结构和排列得到不同的分数,用于检测严重遮挡和无约束姿态变化下的人脸。LDCF+[24]利用改进的决策树分类器检测人脸。UnitBox[45]引入了IOU(IoU)损失,以直接最小化预测的IOU和更精确定位ground truth。ScaleFace[44]通过应用一组特殊的具有不同结构的CNNs来检测不同尺度的人脸。SAFD[11]开发了一个尺度proposal阶段,在检测前自动标准化人脸大小。Hu等人使用不同尺度的独立检测器来探测背景信息,寻找微小的人脸。S2AP[31]通过注意图像金字塔中的特定尺度和每个尺度层的有效位置来寻找人脸。Zhu等人使用期望最大重叠(EMO)评分来评价anchors的质量。Bai等人通过[1]生成一个清晰的超分辨率人脸,从一个模糊的小人脸经过GAN[9]检测模糊的小人脸。
此外,许多stateof the art人脸检测器是由一般的目标检测方法发展而来的,包括两阶段方法(Faster R-CNN[27]、R-FCN[5]和FPN[19])和一阶段方法(SSD[21]、RefineDet[49]和RetinaNet[20])。基于Faster R-CNN和R-FCN,一些人脸检测方法(如人脸R-CNN[35]、人脸R-FCN[37]、CMS-RCNN[57]和FDNet[46])结合人脸检测的特点设计了几种具体的训练和测试策略。与FPN类似,FANet[47]聚合了更高层次的特征,以增强用于人脸检测的更低层次的特征。基于SSD, DCFPN[52]和FaceBoxes[53]设计了一个轻量级的人脸检测网络,实现了CPU的实时速度,取得了很好的效果。而S3FD[54]、SFDet[50]、SSH[23]、PyramidBox[32, 17]、DSFD[16]等高性能人脸检测器,为SSD更好地检测小面孔提供了特定的策略,如结构图、训练策略、上下文推理、多层挖掘等。此外,FAN[36]和DFS[33]在RetinaNet上使用不同类型的注意机制来处理hard facees。SRN[4]结合RefineDet[49]中的多步检测和RetinaNet[20]中的focal losss,实现高效、准确的人脸检测。在此之后,VIM-FD[55]和ISRN[51]结合了许多以前的SRN技术,实现了state of the art的性能。
3 方法
从RetinaNet[20]人脸检测基线开始,我们应用了一些最近提出的策略,以实现在具有挑战性的WIDER Face[43]数据集上的state of the art性能。
3.1 RetinaNet Baseline
RetinaNet是目前最流行的单阶段目标检测方法之一。应用于对可能的目标位置进行常规、密集采样的单级检测器有可能更快、更简单,但由于在训练过程中遇到了极端的阶级不平衡,它的精度落后于二阶段检测器。为了解决这一问题,在RetinaNet中提出focal loss如下:

其中![]() }表示ground-truth 类别,
}表示ground-truth 类别,![]() 是类别标签 y=1 的模型估计估计概率,
是类别标签 y=1 的模型估计估计概率,![]() 是平衡因子,
是平衡因子,![]() 可调聚焦参数。focal loss是交叉熵损失的重构,使分类良好的样本所分配的损失权重降低。这种新的focal loss聚焦训练集一组稀疏的hard样本上,防止训练过程中大量的easy的负样本压倒检测器。
可调聚焦参数。focal loss是交叉熵损失的重构,使分类良好的样本所分配的损失权重降低。这种新的focal loss聚焦训练集一组稀疏的hard样本上,防止训练过程中大量的easy的负样本压倒检测器。

图1:我们的人脸检测baseline架构建立在RetinaNet[20]上。(a)backbone:前馈式ResNet-152[12]架构提取多尺度特征图。(b)Neck:一个6级特征金字塔网络(FPN)[19]结构生成了一个更丰富的多尺度卷积特征金字塔。然后连接两个共享子网络,一个用于对achor boxes进行分类(c),另一个用于从anchor boxes回归到ground-truth 目标boxes (d),最后我们使用 focal loss [20]进行二元分类,IoU loss[45]进行回归。
在本文中,我们将修改后的RetinaNet(如图1所示)作为baseline,它是由一个backbone、一个neck网络和两个特定于任务的子网络组成的单一统一的网络。backbone和neck网络负责计算整个输入图像上的多尺度卷积特征图。第一个子网络对backbone输出进行分类,第二个子网进行卷积边界盒回归。具体来说,我们采用了具有6级特征金字塔结构的ResNet-152[12]作为backbone。我们按照FPN[19]中的方法生成6级特征图(P2到P7)进行检测。
3.2 IOU 回归损失
目标检测任务由分类子任务和回归子任务组成。在回归中,smooth-L1损失[7]是常用的损失函数,用来减小anchor boxes与ground-th边界盒之间的差异,而 IoU是目标检测基准中最常用的评价指标。然而,正如[28]所示,优化常用的smooth-L1距离损失来回归边界盒的参数与最大化IoU度量值之间存在差距。度量的最佳目标应该是度量本身,因此我们遵循UnitBox[45],通过直接使用IoU作为回归损失来最小化预测与ground-truth之间的差异。
IOU 回归损失函数定义如下:

其中,![]() ,
,![]() 分别表示预测的边界boxes和ground-truth box。Intersection()和Union()表示
分别表示预测的边界boxes和ground-truth box。Intersection()和Union()表示![]() 和
和![]() 的交集和并集。
的交集和并集。
3.3 Selective Refinement Network
如选择性精细网络(SRN)[4]中所述,使用RetinaNet进行人脸检测仍然存在两个问题:(a)召回效率低:在高召回率下,准确率不够高,即,precision-recall曲线向右延伸足够远,但不够陡;(b)定位精度低:当IoU阈值增加时,性能急剧下降,即,边界框定位精度有待提高。为了解决上述两个问题,在SRN中提出了选择性两步分类(STC)和选择性两步回归(STR),并根据这些设计进一步提高了人脸检测器的性能。
STC在三个低层检测层上进行两步分类,滤除最简单的负样本,减少后续分类器的搜索空间。其损失函数为:

STR执行的是在三个高层检测层上的两步回归,以调整anchors,并为后续回归器提供更好的初始化。其损失函数为:
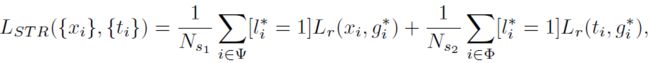
其中 i 是anchor 的索引,![]() 和
和![]() 分别表示第一/第二步的分类和回归的预测。
分别表示第一/第二步的分类和回归的预测。![]() 是类别定位的ground-truth。
是类别定位的ground-truth。![]() 是在第一/第二步中正anchor的数量。
是在第一/第二步中正anchor的数量。![]() 是第一步中分类/回归的样本集合,
是第一步中分类/回归的样本集合,![]() 是第二步的样本集合。
是第二步的样本集合。![]() 是sigmoid focal loss ,
是sigmoid focal loss ,![]() 表示只计算正anchorIOU回归损失。
表示只计算正anchorIOU回归损失。
3.4 数据增强
数据增强对于单阶段检测器构建鲁棒模型以适应目标的变化具有重要意义,特别是对于具有大量小人脸的人脸检测。在大多数人脸检测器的基础上,我们随机扩展和裁剪原始训练图像,并附加随机光度蒸馏[13],然后翻转生成训练样本。此外,我们将概率为0.5的随机裁剪操作替换为PyramidBox中的data-anchor-sampling,以多样化训练样本的尺度分布。基于data-anchor-sampling的操作首先在batch中随机选择一个尺寸为![]() 的人脸,然后找到其最近的anchor尺度
的人脸,然后找到其最近的anchor尺度![]() 。然后,它随机选择一个最近的anchor尺度
。然后,它随机选择一个最近的anchor尺度![]() 。最后,通过
。最后,通过![]() 调整图像的大小,随机裁剪包含所选人脸的训练大小的标准尺寸,得到anchor采样的训练数据。
调整图像的大小,随机裁剪包含所选人脸的训练大小的标准尺寸,得到anchor采样的训练数据。
3.5 Max-out 标签
为了减少来自背景区域的小人脸的假阳性,在[54]中引入了背景类的max-out操作,接下来的工作[32]在前景和背景类别上都使用了这个max-out操作。在提出的人脸检测方法中,分类子网采用max-out操作,可以同时召回更多的人脸,减少误报。分类子网首先预测每个anchor的cp+cn得分,然后选择max{cp}和max{cn}作为最终的人脸和无人脸置信度得分,计算分类损失。根据经验,我们设置cp = 3, cn = 3 来训练最终的模型。
3.6 多尺度测试
由于在具有挑战性的WIDER Face数据集中有大量的小人脸,因此采用多尺度测试策略可以有效地提高性能。我们使用开源code在推理期间进行多尺度测试。它将不同大小的图像多次输入训练后的模型,然后将这些检测结果与边界框投票操作合并。
4 实验
4.1 实验数据集
我们在WIDER Face [43]数据集上验证了所提出的AInnoFace检测器,该数据集是一种流行的人脸检测基准数据集,其图像选自公共可用的WIDER[38]数据集。WIDER FACE数据集包含32203幅图像和393703个带注释的人脸边界框,在尺度、姿势、遮挡、表情、化妆和光照方面具有高度可变性,如图2所示。所有的图像都是基于61个事件类进行组织的,并从每个事件类中随机抽取40%/10%/50%作为训练、验证和测试子集。根据边界盒[59]的检测率,将验证和测试子集划分为易、中、难三个难度等级。采用平均精度(AP)作为评价指标。在MALF[41]和Caltech[6]数据集之后,该数据集不释放测试图像的边界框ground truth,研究者需要提交最终的预测文件来获得测试子集的AP性能。该方法在训练子集上进行训练,并在验证子集和测试子集上进行评估。
4.2 anchor 细节
遵循【4】(SRN)我们设置两个![]() 和
和![]() 个anchor 尺度(S是检测层的下采样因子)和1.25的aspect ratio。因此,每个位置有A=2 个anchors,在1024*1024 的图像中覆盖了 8~362 的像素大小。在训练阶段,利用
个anchor 尺度(S是检测层的下采样因子)和1.25的aspect ratio。因此,每个位置有A=2 个anchors,在1024*1024 的图像中覆盖了 8~362 的像素大小。在训练阶段,利用![]() 的门限值给anchor分配ground-truth boxes,如果IOU处于
的门限值给anchor分配ground-truth boxes,如果IOU处于![]() 则为背景。剩下的处于
则为背景。剩下的处于![]() 之间的anchors被忽略。我们在第一个阶段设置
之间的anchors被忽略。我们在第一个阶段设置![]() ,
, ![]() ,在第二个阶段
,在第二个阶段![]() ,
, ![]() 。
。
4.3 优化细节
在ImageNet[29]数据集上,通过预训练模型初始化所提出的AInnoFace检测器的主干网络。我们使用“xavier”[8]方法随机初始化新添加的卷积层的参数。采用随机梯度下降(SGD)算法对模型进行finetune。momentum=0.9、weight decay=0.0001、batch sieze为32。采用[10]warmup策略,在前5个阶段将学习率从0.0003125逐渐提高到0.01。之后,它会切换到常规的学习率机制。即,在第100个epoch和第120个epoch的时候除以10,在130的时候结束。完整的培训和测试代码建立在PyTorch库[25]上。
4.4 评估结果
实验对比结果见下面的precision-recall 曲线。
easy 的验证集和测试集结果:

medium 的验证集和测试集结果:

hard的验证集和测试集结果:
