ClickHouse合集(一):分布式集群部署及python调用
0.ClickHouse
参考资料 :
Clickhouse 在腾讯的应用实践 : http://www.yidianzixun.com/article/0NaOwJjF?appid=mibrowser
0.基础概念
0.0.概述
俄罗斯 Yandex 2016 开源 列式存储数据库 DBMS
0.1.应用场景
在线分析处理查询OLAP – 使用SQL实时生成分析数据报告
0.2.适用场景
只有几列常用 查询非常快
1.安装及启动
1.1.方式一 单机模式
-
安装/卸载
-
1.确保CentOS支持外网
$ ping Baidu.com -
2.确保CentOS支持SSE
$ grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iN6JRHE6-1585995391656)(media/15716513356460/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202019-10-21%20%E4%B8%8B%E5%8D%888.12.05.png)]](http://img.e-com-net.com/image/info8/39c774e6604141e3be8ad485ff2ee6f2.jpg)
-
3.CentOS取消打开文件数限制
vi /etc/security/limits.conf # 在文件末尾追加配置 * soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072 vi /etc/security/limits.d/20-nproc.conf # 在文件末尾追加配置 * soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072 -
4.CentOS取消SELINUX
vi /etc/selinux/config # 修改SELINUX的值 SELINUX=disabled -
5.创建安装目录/opt/software/clickhouse(不用)
$ mkdir /opt/software/clickhouse $ cd /opt/software $ ll -
6.上传安装包

-
7.安装

-
8.解决依赖
$ yum install libicu.x86_64
-
9.重新安装

-
-
启动/关闭服务
-
1.启动服务
# 全局目录下 $ service clickhouse-server start![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6k2HnkbN-1585995391659)(media/15716513356460/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202019-10-21%20%E4%B8%8B%E5%8D%888.13.19.png)]](http://img.e-com-net.com/image/info8/f4dadfe2c14b450bb3881d41029ed148.jpg)
- 默认重启服务器服务自启动
-
2.关闭服务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0Nlrgti2-1585995391660)(media/15716513356460/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202019-10-21%20%E4%B8%8B%E5%8D%888.50.38.png)]](http://img.e-com-net.com/image/info8/14fb1f3ae2b34a5e9a8e36ba33e91f94.jpg)
-
3.卸载
$ yum list installed | grep clickhouse $ yum remove -y clickhouse-common-static $ yum remove -y clickhouse-server-common $ rm -rf /var/lib/clickhouse $ rm -rf /etc/clickhouse-* $ rm -rf /var/log/clickhouse-server
-
-
进出客户端/交互模式 – 同集群模式
-
客户端内使用/交互模式内使用 – 同集群模式
1.2.方式二 分布式/集群模式
- 节点分布 : 10.255.175.240 10.255.175.241 10.255.175.242
-
安装/卸载 – 每个节点执行
-
0.分布式部署前提
-
0.1关闭防火墙
$ firewall-cmd --state $ systemctl stop firewalld $ firewall-cmd --state $ systemctl disable firewalld.service $ systemctl list-unit-files | grep firewalld -
0.2修改主机名
$ vi /etc/hostname 第1行主机名改成 clickhousex $ reboot $ hostname -
0.3修改主机名与IP映射
$ vi /etc/hosts 添加以下3行 10.255.175.240 clickhouse1 10.255.175.241 clickhouse2 10.255.175.242 clickhouse3 -
0.4配置SSH免密登录
# 1.开启Authentication免登陆 — 每个节点都操作 $ vi /etc/ssh/sshd_config 以下三行去掉注释 RSAAuthentication yes PubkeyAuthentication yes PermitRootLogin yes # 如果非root用户这行不需要 # 2.生成authorized_keys -- 每个节点都操作 $ ssh-keygen -t rsa # 生成key 会在/root/.ssh生成:authorized_keys id_rsa.pub id_rsa 三个文件 一直回车 # 3.合并公钥到authorized_keys文件 — master操作 $ cd /root/.ssh # 将三个节点的公钥逐一追加到master的authorized_key文件 $ cat id_rsa.pub>> authorized_keys $ ssh [email protected] cat ~/.ssh/id_rsa.pub>> authorized_keys $ ssh [email protected] cat ~/.ssh/id_rsa.pub>> authorized_keys # 将合并后信息持有三个公钥的authorized_key文件copy给其他两个slave节点 $ scp authorized_keys 10.255.65.2:/root/.ssh/ $ scp authorized_keys 10.255.65.3:/root/.ssh/ # 4.修改authorized_keys文件权限为只当前用户读写 — 每个节点都操作 $ cd /root/.ssh $ chmod 600 authorized_keys # 5.重启SSH服务 — 每个节点都操作 $ service sshd restart # 6.测试免密登录 — 每个节点都操作 $ ssh 10.255.175.x 测试互相访问对方是否不需要输入密码就可连接 -
5.创建软件文件夹 — 每个节点都操作
$ mkdir /opt/software $ cd /opt/software $ ll -
6.CentOS上安装lrzsz工具
$ yum install lrzsz -
7.安装zookeeper集群
-
-
1.确保CentOS支持外网$ ping Baidu.com
-
2.确保CentOS支持SSE
-
3.CentOS取消打开文件数限制
-
4.CentOS取消SELINUX
-
5.创建安装目录/opt/software/clickhouse
-
6.上传安装包
-
7.安装
-
8.解决依赖
-
9.重新安装
- 以上1~9步同单机模式
-
-
配置分布式部署
每台节点执行以下步骤 :
-
1.配置config.xml
vi /etc/clickhouse-server/config.xml # 把这行代码注释去掉 使其他IP可访问本机:: -
2.新建metrika.xml
vi /etc/metrika.xml # 编写如下内容部分根据不同机器更改 # 服务器集群设置 # 集群名 可自定义 张三 # 配置高可用时需要ZK# 数据分片1/分片信息(分片:我的数据有9条 我设置3个分片的话 就一个分片存储3条 分片就是一块储存区域 3个分片也一定在不同的节点上) # 开启自动复制/启用自动表备份 # 数据分片2true # 副本 -- 指定本分片/节点上的数据的备份 要放在的哪写些节点上做备份 -- 节点2上放一份 节点3上放一份就要再加一个标签 hadoop102 9000 true hadoop103 9000 true hadoop104 9000 hadoop102 2181 hadoop103 2181 hadoop104 2181 hadoop102 ::/0 10000000000 0.01 1z4
-
-
启动/关闭服务
-
0.启动3个ZK
# 启动 $ cd /opt/software/zookeeper-3.4.5/bin $ ./zkServer.sh start # 查看状态 $ ./zkServer.sh status $ jps # Jps查看进程 如果三台机器都有QuorumpeerMain 则启动成功 -
1.分别启动3个clickhouse服务
# 全局目录下 $ service clickhouse-server start
-
-
进出客户端/交互模式
-
1.进入客户端/交互模式 – 任一节点
$ clickhouse-client
-
2.退出客户端/交互模式
:) exit
- 客户端常用参数

- 举例
- -q : 非交互模式 执行查询语句
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FQRpPYKX-1585995391667)(media/15716513356460/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202019-10-21%20%E4%B8%8B%E5%8D%888.29.51.png)]](http://img.e-com-net.com/image/info8/cf4f244e6bcf4de7a5ae477ea7de3e80.jpg)
- -q : 非交互模式 执行查询语句
- -t -q : 非交互模式 显示查询语句执行耗时

- -d : 指定数据库进入交互模式

- -m : 设置回车不自动执行语句 只有;才是语句结束
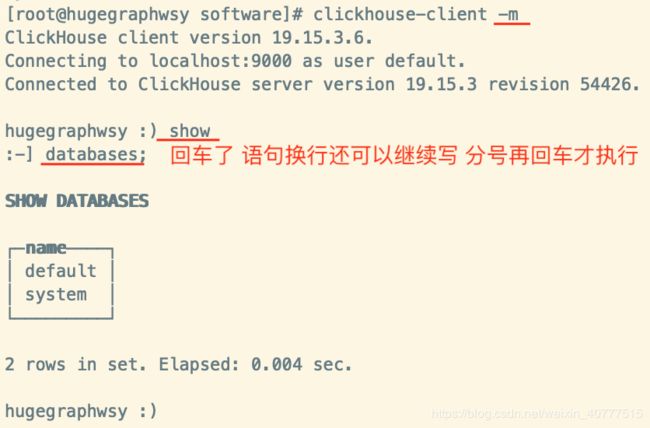
- 客户端常用参数
-
-
客户端内使用/交互模式内使用 (同单机模式)
-
0.查看集群信息
:) select * from system.clusters # 查看集群有几个分片(节点)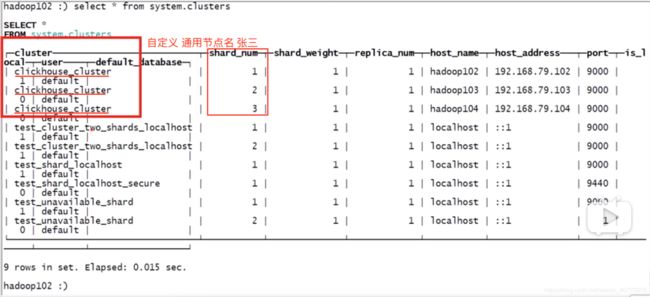
-
1.查看所有数据库
:) show databases;
-
2.切库
:) use system;- 不指定数据库 就建表 默认存在default库中
-
3.查看所有表
:) show tables; -
4.内置函数
-
cast – 转换
:) select cast(boo,'Int8') from enum; -
toTypeName(变量) – 查看数据类型
:) select array(1,2,3) as arr, toTypeName(arr) # 结果 : [1,2,3] Array(UInt8) -
currentDatabase() – 获取当前数据库名
:) create table t(id UInt16, name String) ENGINE=Merge(currentDatabase(), '^t');
-
-
2.数据类型
- 与其他框架对比

-
整型
- 分类
- 有符号整型 – 一定范围用于表示正负数
- Int8 – [-128 : 127]
- Int16 – [-32768 : 32767]
- Int32 – [-2147483648 : 2147483647]
- Inte64 – [-9223372036854775808 : 9223372036854775807]
- 无符号整型 – 一定范围只用于表示正数
- UInt8 – [0 : 255]
- UInt16 – [0 : 65535]
- UInt32 – [0 : 4294967295]
- UInt64 – [0 : 18446744073709551615]
- 有符号整型 – 一定范围用于表示正负数
- 分类
-
浮点型 – 官方不建议使用 损失精度
- 分类
- 常规浮点型
- Float32 – float
- Float64 – double
- 独有浮点型
- -Inf – 负无穷
- Inf – 正无穷
- NaN – 非数字
- 因为独有浮点型 clickhouse计算支持/0
- 常规浮点型
- 损失精度举例
``` :) select 1-0.9 ```- 独有浮点型举例
- 负无穷-Inf
``` :) select -1/0 # 结果 : 负无穷-inf ```- 正无穷Inf
``` :) select 1/0 # 结果 : 正无穷inf ```- 非数字NaN
``` :) select 0/0 # 结果 : 非数字nan ``` - 分类
-
字符串
- 分类
- String – 任意长度 可包含任意字节集 包含空字节
- FixedString(N) – N是字符串长度
一般用String就够了 要限制长度时才用FixedString(N)
- 分类
-
枚举
- 分类
- Enum8 – ‘String’=Int8
- Enum16 – ‘String’=Int16
clickhouse的枚举 只能用’String’=整型 描述 不能像Java一样’String’='String’来描述
- 分类
-
布尔型 – 用枚举代替
-
应用场景 : 新建一张表enum 一个字段boo 数据类型达到boolean效果 使用户插入只能写入’true’或’false’ 实际存储的是0或1
# 举例 # 新建一张表enum 一个字段boo 数据类型达到boolean效果 使用户插入只能写入'true'或'false' 实际存储的是0或1# 查看枚举键值的映射 (应用场景 : 别人的表 你select * from enum表时 只知道boo字段的值是'true'或'false' 想知道谁对应0谁对应1) :) select * from enum :) select cast(boo,'Int8') from enum # 将两个结果对应起来即可
-
-
数组Array(T)
- 建议一个数组中元素的数据类型只用一种 – 尽管T可以是任意类型 一个数组 支持多种数据类型的元素存在 但Clickhouse对多位数组的支持有限 不能在Merge表中存储多维数组
```
# 创建数组
[1,2,3]
或
array(1,2,3) # array内置函数
```
-
元祖Tuple(T1,T2,…) – 每个元素都可以有单独的类型
# 创建元祖 tuple(1,'a','b',4) -
Date日期类型 – 0000-00-00
- 用2字节存储 表示从1970-01-01(无符号)到当前的日期
-
DateTime时间戳类型 – 0000-00-00 00:00:00
- 存储Unix时间戳 精确到秒(没有闰秒)
3.表引擎
- 概念
- 表的类型
- 作用
- 1.决定此表 存储位置 内存还是硬盘
- 2.决定此表 是否支持 Alter Update
- 3.决定此表 是否支持 并发 多线程
- 4.决定此表 是否支持 索引
- 5.决定此表 数据复制参数 – 直接体现在 高可用 (分片 复制几份 复制到哪)
大多数正式的任务 使用MergeTree族中的引擎
- 分类
-
TinyLog – 最简单的表引擎
- 特点
- 1.存在磁盘 占空间小 节省空间
- 2.不支持index
- 3.几乎不支持并发 – r+r 支持 ; r+w 直接报错Exception ; w+w 数据直接损坏 # r : read ; w : write
- 适用情景
- 1.小表很多 节省空间
- 2.只查询 比如国家信息 省份信息 几乎不变
# 创建一个TinyLog引擎的表 :) create table stu1(id Int8, name String)engine=TinyLog # 插入一条数据 insert into stu1 values(1, 'zs');# 查看数据实际存储位置 $ cd /var/lib/clickhouse/data/default/stu1/ $ ls # 结果 : id.bin name.bin sizes.json- 数据实际存储位置 /var/lib/ckickhouse/data/数据库名/表名/很多个xx.bin文件
- 一个 列名.bin 是压缩过的文件 对应一列数据
- 一个 尺寸文件sizes.json 记录了每个.bin文件的大小
- 特点
-
Memory
- 特点
- 1.存在内存
- 2.读写不阻塞
- 3.太快了 简单查询10G数据/s – 不支持索引 不必要 已经这么快了
- 应用情景
- 1.测试用 数据不重要 关机可销毁 数据量上限1亿行
- 特点
-
Merge
-
特点
- 1.本身不存储数据
- 2.用于合并其他表的数据 – 被合并的表不能跨服务器 创建时直接用参数指定要合并数据的表
# 创建一个TinyLog引擎的表 :) create table t1 (id UInt16, name String)ENGINE=TinyLog; :) create table t2 (id UInt16, name String)ENGINE=TinyLog; :) create table t3 (id UInt16, name String)ENGINE=TinyLog; # 插入数据 :) insert into t1(id, name) values(1, 'first'); :) insert into t2(id, name) values(2, 'second'); :) insert into t3(id, name) values(3, 'i am in t3'); # 创建一个Merge引擎的表 :) create table t(id UInt16, name String) ENGINE=Merge(currentDatabase(), '^t'); # 参数1 -- 指定要合并的表所在的数据库 ; 参数2 -- 正则表达式 匹配表名 指定要合并的表 # ^t匹配所有t开头的表名 # 向Merge引擎表中插入数据 :) insert into t values(1, 'd'); # 结果 : 会报错Exception:Method write is not supported by storage Merge 不可以插入数据 只能合并其他表的数据
-
-
MergeTree – 最强大(重点)
-
作用
- 一开始存入时 一条数据存一个文件夹 数据多了 自动按月分区合并 (实质上先合并数据量少的文件夹 再按月分区)
-
特点
- 1.按主键排序 – 利用 : 可以创建一个小稀疏索引
- 2.指定主键后 可使用日期分区 – 一般按月分区 表中必须有一个Date类型字段
- 3.支持数据副本 – 利用 : ReplicatedMergeTree系列的表便是用于此
- 4.支持数据采样 – 利用 : 需要的话 可给表设置一个采样方法
# 创建一个MergeTree引擎的表 :) create table a(id UInt16, name String, createtime Date) ENGINE=MergeTree() [PARTIDION BY expr] [ORDER BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [SETTINGS name=value,...] # PARTITION BY expr : 按月分区 例如toYYYYMMM(date_column) ; # ORDER BY expr : 按expr排序 如果参数没指定主键 默认ORDER BY后都变为主键 例如ORDER BY(id,name) ; # PRIMARY KEY : 指定主键 不能和ORDER BY后的字段相同 ; # SAMPLE BY : 用于抽样的表达式 如果要用抽样表达式 主键中必须包含这个表达式 ; # SETTINGS : 影响MergeTree性能的额外参数设置 [index_granularity = 8192] 设置索引粒度 即索引中相邻标记间的数据行数 默认值8192 [use_minimalistic_part_header_in_zookeeper = 1] 数据片段头在Zookeeper中存多少 例如原本存了元数据和地址等 设置为1后 存的更少了 可能只存元数据了 [min_merge_bytes_to_use_direct_io = 10*1024*1024k] 默认10G 合并时的数据量超过此值 Linux会使用直接I/O来操作 不超过时用默认的缓存I/O操作(直接I/O就是从硬盘读取直接存入硬盘 数据量大时不走缓存避免很快存满了 CPU阻塞等待处理 ; 缓存I/O就是从硬盘读取在缓存中处理再存入硬盘 数据量小的话 走缓存处理会很快) # 举例 # 进入客户端 $ clickhouse-client -m # 创建一个MergeTree引擎的表 :) create table mt_table(date Date, id UInt8, name String) engine=MergeTree() partition by date order by (id, name) settings index_granularity=8192; # 插入数据 insert into mt_table values('2019-05-01', 1, 'zhangsan'); insert into mt_table values('2019-06-01', 2, 'lisi'); insert into mt_table values('2019-05-03', 3, 'wangwu'); # 重复插入10次 等待 可看到数据真实存储目录的自动合并处理 # 退出客户端 :) exit; # 查看数据真实存储目录 $ cd /var/lib/clickhouse/data/default/mt_table $ ll # 结果 : 插入一条数据 就存一个文件夹20190501_1_1_0 20190503_3_3_0 20190601_2_2_0 当文件夹多了时 MergeTree自动按照我们指定的主键和分区 进行合并 减少文件夹数量 合并在未知的时间在后台进行 # 等很久之后再看数据真实存储目录 会少了很多文件 被合并了~~ -
手动触发合并merge – 不要用 会触发大量数据的读和写
:) optimize table 表名 # 可以手动触发合并 但是不咋好使
-
-
ReplacingMergeTree – 继承自MergeTree
-
作用
- 在MergeTree基础上 增加 合并时自动删除重复数据功能 所有主键相同即重复 # 但不能保证完全没有重复数据出现 只能保证主键不重复
# 创建一个ReplacingMergeTree引擎的表 create table rmt_table(id UInt8, name String, date Date) ENGINE=ReplacingMergeTree([ver]) [PARTIDION BY expr] [ORDER BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [SETTINGS name=value,...] # ver: 版本列 作为筛选版本的列 数据类型只能是UInt*, Date或DateTime 会选择ver值最大的版本留下 其他删掉 ; 如果ver列未指定 默认选择最新一条留下 (因为合并不一定什么时候发生 所以插入重复数据时 可能只自动删除了一部分 等合并时还会再次删除 最终只剩一条) # 举例 # 进入客户端 $ clickhouse-client -m # 创建一个ReplacingMergeTree引擎的表 :) create table rmt_table(date Date, id UInt8, name String, point UInt8) ENGINE=ReplacingMergeTree(point) partition by date order by (id, name); # 插入数据 -- 主键都重复的 :) insert into rmt_table values('2019-07-10', 1, 'a', 20); insert into rmt_table values('2019-07-10', 1, 'a', 30); insert into rmt_table values('2019-07-11', 1, 'a', 20); insert into rmt_table values('2019-07-11', 1, 'a', 30); insert into rmt_table values('2019-07-11', 1, 'a', 10); # 查询表数据 :) select * from rmt_table; # 手动触发合并 :) optimize table rmt_table; -
手动触发合并merge (同上)
-
-
SummingMergeTree – 继承自MergeTree
-
1.在MergeTree基础上 增加 合并时自动把主键相同的行相加为一行的功能 不可加的列 会取最早出现的值
# 创建一个SummingMergeTree引擎的表 create table smt_table(id UInt8, name String, date Date) ENGINE=SummingMergeTree([columns]) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value,...] # 举例 # 进入客户端 $ clickhouse-client -m # 创建一个SummingMergeTree引擎的表 :) create table smt_table(date Date, name String, sum UInt16, not_sum UInt16) engine=SummingMergeTree(sum) partition by date order by (date, name); # 插入数据 :) insert into smt_table values('2019-07-10', 'a', 1, 2); insert into smt_table values('2019-07-10', 'a', 2, 1); insert into smt_table values('2019-07-11', 'b', 3, 9); insert into smt_table values('2019-07-11', 'b', 3, 8); insert into smt_table values('2019-07-11', 'a', 3, 1); insert into smt_table values('2019-07-12', 'c', 1, 3); # 查询表数据 :) select * from smt_table; # 手动触发合并 :) optimize table smt_table; -
手动触发合并merge (同上)
-
-
Distributed – 分布式引擎(重点)
-
作用
- 分布式引擎 本身不存储数据 但可在多个服务器上进行分布式查询
- 读是自动并行的 读取时 远程服务器表的索引(如果有)会被使用
# 创建一个Distributed引擎的表 :) create table d_table(id UInt8, name String, date Date) engine=Distributed(cluster_name, database, table [,sharding_key]) # cluster_name : 集群名 -- /etc/metrika.xml中这个自定义的标签的名字 # database : 数据库名 # table : 表名 # sharding_key : 分片键(某一列名) 可选 -- 向分布式引擎的表插入数据时 会根据分片名(默认 1 2 3)和你指定的分片键 计算得出实际上数据插入哪一个节点 每次插入的节点可能都不一样 根据默认算法来 # 举例 # 在3个节点上分别创建一个表t :) create table t(id UInt16, name String) ENGINE=TinyLog; # 给3个节点的t表分别插入2条数据 :) insert into t(id, name) values(1, 'zhangsan'); insert into t(id, name) values(2, 'lisi'); # 在10.255.175.240节点上创建一个Distributed引擎的表 :) create table dis_table(id UInt16, name String) ENGINE=Distributed(clickhouse_cluster, default, t, id); # 查看dis_table表的数据 :) select * from dis_table; # 结果: 分别列出了3个节点的t表的数据 # 向Distributed引擎的表插入数据 :) insert into dis_table values(3, 'zs'); # 查看dis_table表的数据 :) select * from dis_table; # 结果: 这条数据实际插入到了节点1的t表 # 再向Distributed引擎的表插入数据 :) insert into dis_table values(4,'zs'); # 查看dis_table表的数据 :) select * from dis_table; # 结果: 这条数据实际插入到了节点3的t表
-
-
4.SQL
- Alter
- 前提
- 只支持MergeTree系列引擎 Merge引擎 Distributed引擎的表
- 前提
- 物化表达式
- 也是个列 但 select * 查不出来 ; 不能insert进去
# 检查表中数据是否损坏
$ check table # 结果: 0数据已损坏 1数据完整
# 只支持 *log引擎(Log TinyLog StripeLog) -- 因为其他引擎不会涉及到损坏数据
5. 从HDFS导入数据
- 18.16.0版本 支持从HDFS读数据
- 19.1.6版本 支持从HDFS读写数据
- 19.4版本 支持Parquet格式
- 好像只支持csv文件和Parquet文件的数据导入
- 1.查询HDFS上的CSV文件
- 需求:不是把HDFS上的文件导入表中 而是通过该表去访问HDFS上的数据 – 相当于把HDFS当成外部存储 由于需要去HDFS上拉取数据 次方式教育clickhouse本地存储速度较慢
- 原理:clickhouse-client去调用clickhouse的查询引擎 查询引擎去HDFS上拉取数据 给 client返回查询结果
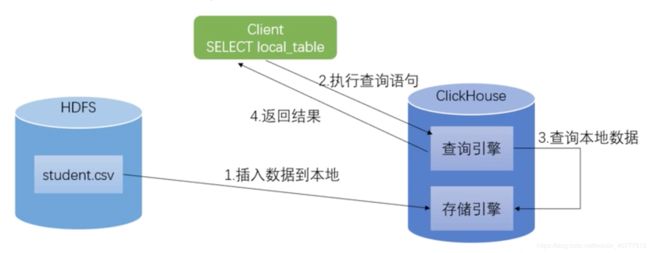
- 操作
-
1.假设HDFS上已经上传了student.csv文件
-
2.在ClickHouse创建一个访问student.csv文件的表
# 进入clickhouse客户端 $ clickhouse-client -m # 创建新表 :) create table hdfs_student_csv ( id Int8, name String ) Engine=HDFS('hdfs://hadoop102:9000/student.csv','CSV'); # 查询新表 :) select * from hdfs_student_cs; # 如果关闭HDFS服务 就无法查询了 或 $ hadoop fs -rm -r /student.csv 从Hadoop上删掉这个文件 也查不到
-
- 操作
- 2.从HDFS导入数据 – 查询HDFS上的数据并存储在本地的存储引擎
- 需求:从HDFS导入数据
- 原理:将HDFS数据插入到本地存储引擎 执行查询语句 会调用查询引擎 查询引擎去clickhouse的查询引擎拿数据

- 操作
-
1.准备存储数据的表
# 进入clickhouse客户端 $ clickhouse-client -m # 创建新表 :) create table student_local ( id Int8, name String ) Engine=TinyLog; -
2.从HDFS中导入数据
:) insert into studnet_local select * from hdfs_student_csv; # 后便的select语句就是需求1. -
3.查看导入结果
:) select * from student_local;
-
优化配置
-
1.max_table_size_to_drop
- 位置
- /etc/clickhouse-server/config.xml中
- 作用
- 需要删除表或分区时 默认50G – 即 如果你要删除的分区或表 数据量达到了此参数值 会删除失败
- 优化配置
- 改为自己数据库合适的 万一大数据量的表都是重要的 可以防误删
- 位置
-
2.max_memory_usage
- 位置
- /etc/clickhouse-server/user.xml中
- 作用
- 表示单次Query占用内存最大值 超购本值Query失败
- 优化配置
- 在资源足够时 尽量调大
- 位置
-
3.删除多个节点上的同一张表 – on cluster关键字
-
操作
:) drop table t on cluster clickhouse_cluster
-
-
4.自动数据备份 – 以三分片两副本为例 即是至少6个节点的集群
- 前提
- 只有MergeTree系列引擎的表支持
- 原理
- 通过zookeeper完成数据备份
- 操作
-
1.在表引擎名上加上Replicated – 如 ReplicatedMergeTree
-
2.在配置文件metrika.xml中配置zookeeper
vi /etc/metrika.xml # 更改如下内容部分根据不同机器更改 # 服务器集群设置 # 集群名 可自定义 张三 # 配置高可用时需要ZK# 数据分片1/分片信息 # 开启自动复制/启用自动表备份 # 数据分片2true # 副本 -- 指定分片上的数据 的备份 要放在的哪写些节点上做备份 -- 节点2上放一份 节点3上放一份hadoop102 9000 hadoop103 9000 true hadoop104 9000 hadoop105 9000 true hadoop106 9000 hadoop107 9000 # 这个标签内部不修改 # 标签 需要加上hadoop102 2181 hadoop103 2181 hadoop104 2181 ; 值 自定义 但是有规律:分片3个 例如自定义值 01 02 03 副本2个 自定义值 a b 需要二者排列组合 01-a 01-b 02-a 02-b 03-a 03-b 分别填写在6个服务器的 标签内 hadoop102 -
3.在6台机器上分别创建表
:) create table table_name_x # x 是1 2 3 4 5 6 6个表名不能一样 ( ... ) Engine=ReplicatedMergeTree('/clickhouse/tables/{shard}/table_name','{replica}') # 第一个参数是zookeeper节点地址 六个表都不一样 /clickhouse/tables/可自定义 但官方建议用这个不要改 ; {shard} 不用改 是自动读取本台机器的配置文件metrika.xml中标签的 标签的值 ; table_name 要换成表名 # 第二个参数{replica}是副本名 不用改 是自动读取本台机器的配置文件metrika.xml中 标签的 标签的值 PARTITION BY expr ORDER BY expr SAMPLE BY expr
-
- 前提
Python调用clickhouse
0.目标
python向clickhouse数据库操作数据
1.确保能远程连接clickhouse
```
# 确保clickhouse主节点防火墙关闭 或 防火墙开启但开放8123端口
# 确保/etc/clickhouse-server/config.xml配置文件中是:: 配置 使其他IP可访问本机
# python所在节点ping通clickhouse主节点 -- 79ping240
$ ping 10.255.175.240
# 确保clickhouse主节点telnet通自己的ip端口 其他ip能telnet通clickhouse主节点ip端口
# 安装telnet服务
$ yum install telnet-server
$ yum install xinetd # xinetd是telnet的守护进程
# 设置开机启动
$ systemctl enable xinetd.service
$ systemctl enable telnet.socket
# 启动服务
$ systemctl start telnet.socket
$ systemctl start xinetd 或service xinetd start # telnet服务是由xinetd守护 所以要启动telnet服务也需要启动xinetd
# 参考:https://www.cnblogs.com/ocp-100/p/10729210.html
```
2.Python调用
```
# 0.安装驱动
# clickhouse主节点上
$ pip install clickhouse-driver
```
```
# 1.代码调用
# 79服务器上clickhousetest.py
from clickhouse_driver import Client
client = Client(host='10.255.175.240', database='default', user='default', password='')
result = client.execute('SHOW DATABASES')
print(result)
```
特性 – 优点
-
0.单个查询的并行处理(利用多个内核)
- 索引非B树结构 不需要满足最左原则 ; 只要过滤条件在索引列中包含即可 ; 即使在使用的数据不在索引中 由于各种并行处理机制ClickHouse全表扫描的速度也很快
-
1.多服务器分布式处理
- 常用的列式数据库管理系统 几乎没有一个支持分布式的查询处理 ; 而ClickHouse 数据可以保存在不同的shard上 每一个shard都由一组用于容错的replica组成 查询可以并行的在所有shard上进行处理
-
2.超快速扫描可用于在线查询
- 在线查询意味着 在没有对数据做任何预处理的情况下 以极低的延迟处理查询 并将结果加载到用户的页面中
-
3.列存储非常适合使用“宽”/“非规范化”表(许多列)
-
4.向量引擎
- 为了高效的使用CPU 数据不仅仅按列存储 同时还按向量(列的一部分)进行处理
-
5.良好的压缩
- 数据压缩空间巨大 减少IO
-
6.SQL支持
- 支持的查询包括 GROUP BY 、ORDER
BY 、IN 、JOIN以及非相关子查询 ;不支持窗口函数和相关子查询
- 支持的查询包括 GROUP BY 、ORDER
-
7.支持近似计算
- 提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
- 0.用于近似计算的各类聚合函数 如:distinct values 、 medians 、quantiles
- 1.基于数据的部分样本进行近似查询 这时 仅会从磁盘检索少部分比例的数据
- 2.不使用全部的聚合条件 通过随机选择有限个数据聚合条件进行聚合 这在数据聚合条件满足某些分布条件下 在提供 相当准确的聚合结果的同时降低了计算资源的使用
- 提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
-
8.不同的存储引擎(磁盘存储格式)
-
9.非常适合结构日志/事件数据以及时间序列数据(引擎MergeTree需要日期字段)
-
10.索引支持(仅主键 并非所有存储引擎)
- 按照主键对数据进行排序 这将帮助ClickHouse以几十毫秒的低延迟对数据进行特定值查找或范围查找
-
12.实时的数据更新
- 支持在表中定义主键 为了快速主键索引范围查找 数据总是以增量的方式有序的存储在MergeTree中 因此 数据可以持续不断高效的写入到表中 并且写入的过程中不会存在任何加锁的行为
-
13.支持节点线性动态扩展
-
14.支持数据复制和数据完整性
- 使用异步的多主复制技术 当数据被写入任何一个可用副本后 系统会在后台将数据分发给其他副本 以保证系统在不同副本上保持相同的数据 在大多数情况下ClickHouse能在故障后自动恢复 在一些复杂的情况下需要少量的手动恢复
特性 – 缺点
-
0.没有真正的删除/更新支持 ; 也没有事务
- 与Spark和大多数大数据系统相同
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合GDPR
-
1.没有辅助密钥(与Spark和大多数大数据系统相同)
-
2.自己的协议(不支持MySQL协议)
-
3.有限的SQL支持,并且join实现不同 – 利用 : 如果要从MySQL或Spark迁移 则可能必须重写所有带有联接的查询
-
4.稀疏索引使得ClickHouse不适合通过其键检索单行的点查询
第三方基准测试
-
https://clickhouse.yandex/benchmark.html – 分析型DBMS的性能比较
-
https://www.percona.com/blog/2017/03/17/column-store-database-benchmarks-mariadb-columnstore-vs-clickhouse-vs-apache-spark/ – apache spark 、ClickHouse 、MariaDB ColumnStore列存储数据库基准测试
-
https://www.percona.com/blog/2017/02/13/clickhouse-new-opensource-columnar-database/ – Clickhouse与Spark性能基准测试
-
https://www.altinity.com/blog/2017/6/20/clickhouse-vs-redshift – ClickHouse与Amazon RedShift基准测试
-
https://tech.marksblogg.com/billion-nyc-taxi-rides-clickhouse-cluster.html – 11亿辆出租车:108核ClickHouse集群基准测试
-
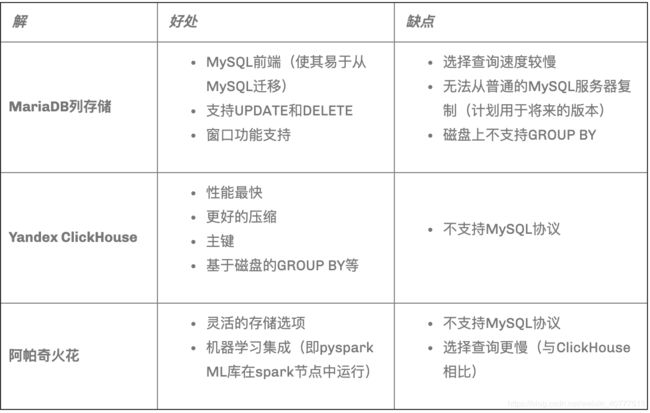
俄罗斯某公司 Clickhouse与Spark对比 :
- 它是服务器的事实极大地有益于我们:免费的输入源分割。使用spark时,您将创建一个包含很多列的表,这不利于可读性,并且insert语句可能会很长,因此容易出错。或解析这些来源几次,有时可能会过于昂贵。Clickhouse没问题。
- 使用Clickhouse,您不仅可以自然分布日志分析。您自然可以在单个来源中获得连续的数据(秒,秒,分钟,分钟)。使用Spark时,您将无法使用http://stackoverflow.com/questions/38793170/appending-to-orc-file。
- Clickhouse可免费使用实时访问收集的数据。这在许多情况下确实很有用。有时可以节省大量时间。
- 如我所说,速度很快。Hadoop的速度很慢,以至于您可能需要多个主机,只是发现与单个主机上的GNU utils(awk,grep,sort,join)上的关系操作速度相匹配。或不是完全达到这个速度。Hadoop太慢了。
性能
0.ClickHouse并非无所不能 查询语句需要不断的调优 可能与查询条件有关 不同的查询条件表是左join还是右join也是很有讲究的
1.与具有相同可用I / O吞吐量的传统的面向行的系统相比,ClickHouse处理典型的分析查询要快两到三个数量级。系统的列式存储格式允许将更多热数据放入RAM中,从而缩短了响应时间。
2.由于ClickHouse的矢量化查询执行涉及相关的处理器指令和运行时代码生成,因此它具有CPU效率。
3.处理单查询高吞吐量每台服务器每秒最多数十亿行
4.写入速度非常快,50-200M/s,对于大量的数据更新非常适用。
5.HBase,BigTable,Cassandra,HyperTable。在这些系统中,你可以得到每秒数十万的吞吐能力,但是无法得到每秒几亿行的吞吐能力,clickhouse可以.
6.单个查询吞吐量:如果数据被放置在page cache中,则一个不太复杂的查询在单个服务器上大约能够以2-10GB/s(未压缩)的速度进行处理(对于简单的查询,速度可以达到30GB/s)。如果数据没有在page cache中的话,那么速度将取决于你的磁盘系统和数据的压缩率。例如,如果一个磁盘允许以400MB/s的速度读取数据,并且数据压缩率是3,则数据的处理速度为1.2GB/s。这意味着,如果你是在提取一个10字节的列,那么它的处理速度大约是1-2亿行每秒。对于分布式处理,处理速度几乎是线性扩展的,但这受限于聚合或排序的结果不是那么大的情况下。
7.处理短查询的延时时间:数据被page cache缓存的情况下,它的延迟应该小于50毫秒(最佳情况下应该小于10毫秒)。 否则,延迟取决于数据的查找次数。延迟可以通过以下公式计算得知: 查找时间(10 ms) * 查询的列的数量 * 查询的数据块的数量。
8.处理大量短查询的吞吐量:ClickHouse可以在单个服务器上每秒处理数百个查询(在最佳的情况下最多可以处理数千个)。但是由于这不适用于分析型场景。建议每秒最多查询100次。
9.数据写入性能:建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。当使用tab-separated格式将一份数据写入到MergeTree表中时,写入速度大约为50到200MB/s。如果您写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。如果您的行更小,那么写入速度将更高。为了提高写入性能,您可以使用多个INSERT进行并行写入,这将带来线性的性能提升。
10.count: 千万级别,500毫秒,1亿 800毫秒 2亿 900毫秒 3亿 1.1秒
group: 百万级别 200毫米,千万 1秒,1亿 10秒,2亿 20秒,3亿 30秒
join:千万-10万 600 毫秒, 千万 -百万:10秒,千万-千万 150秒 – 忘了什么配置
优化
-
0.尽量做1000条以上批量的写入 避免逐行insert或小批量的insert 、 update 、delete操作 因为ClickHouse底层会不断的做异步的数据合并 会影响查询性能 这个在做实时数据写入的时候要尽量避开
-
1.Clickhouse快是因为采用了并行处理机制 即使一个查询 也会用服务器一半的CPU去执行 所以ClickHouse不能支持高并发的使用场景 默认单查询使用CPU核数为服务器核数的一半 安装时会自动识别服务器核数 可以通过配置文件修改该参数(我们不需要高并发 也不用改)
-
2.关闭虚拟内存 物理内存和虚拟内存的数据交换 会导致查询变慢。
-
3.为每一个账户添加join_use_nulls配置 左表中的一条记录在右表中不存在 右表的相应字段会返回该字段相应数据类型的默认值 而不是标准SQL中的Null值
-
4.JOIN操作时一定要把数据量小的表放在右边 ClickHouse中无论是Left Join 、Right Join还是Inner Join永远都是拿着右表中的每一条记录到左表中查找该记录是否存在 所以右表必须是小表
-
5.批量写入数据时 必须控制每个批次的数据中涉及到的分区的数量 在写入之前最好对需要导入的数据进行排序 无序的数据或者涉及的分区太多 会导致ClickHouse无法及时对新导入的数据进行合并 从而影响查询性能
-
6.尽量减少JOIN时的左右表的数据量 必要时可以提前对某张表进行聚合操作 减少数据条数 有些时候 先GROUP BY再JOIN比先JOIN再GROUP BY查询时间更短
-
7.ClickHouse的分布式表性能性价比不如物理表高 建表分区字段值不宜过多 防止数据导入过程磁盘可能会被打满
-
8.CPU一般在50%左右会出现查询波动 达到70%会出现大范围的查询超时 CPU是最关键的指标 要非常关注
-
用完内存是在ClickHouse中处理大型数据集时可能遇到的潜在问题之一
- 默认情况下,ClickHouse限制group by的内存量(它将哈希表用于group by) – 解决 : 如果可用的内存 请增加此参数 SET max_memory_usage = 128000000000; #128G ; 如果没有足够的可用内存,ClickHouse可以通过设置以下内容将数据“溢出”到磁盘 set max_bytes_before_external_group_by=20000000000; #20G
set max_memory_usage=40000000000; #40G - 根据文档,如果您需要使用max_bytes_before_external_group_by ,建议将max_memory_usage设置 为max_bytes_before_external_group_by大小的〜2x。(这样做的原因是聚合分两个阶段进行:(1)读取和构建中间数据,以及(2)合并中间数据。仅在第一阶段才会发生向磁盘的溢出。为了避免溢出,ClickHouse在第1阶段和第2阶段可能需要相同数量的RAM。)
- 默认情况下,ClickHouse限制group by的内存量(它将哈希表用于group by) – 解决 : 如果可用的内存 请增加此参数 SET max_memory_usage = 128000000000; #128G ; 如果没有足够的可用内存,ClickHouse可以通过设置以下内容将数据“溢出”到磁盘 set max_bytes_before_external_group_by=20000000000; #20G
其他补充:
- 0.IO方面 MySQL等是行存储 ClickHouse是列存储 后者在count()这类操作天然有优势 ; 同时 在IO方面 MySQL需要大量随机IO ClickHouse基本是顺序IO 有人可能觉得上面的数据导入的时候 数据肯定缓存在内存里了 这个的确 但是ClickHouse基本上是顺序IO 对IO基本没有太高要求 当然 磁盘越快 上层处理越快 但是99%的情况是 CPU先跑满了(数据库里太少见了 大多数都是IO不够用)
何时不使用ClickHouse
事务性工作负载(OLTP)
高请求率的键值访问
Blob或文档存储
标准化数据
调研参考资料
0.clickhouse系列教程
https://blog.csdn.net/zhangpeterx/article/details/95060788#Python_25
1.clickhouse集群搭建从0到1
https://www.jianshu.com/p/ae45e0aa2b52?utm_campaign=maleskine&utm_content=note&utm_medium=reader_share&utm_source=weibo
2.clickhouse安装及使用
https://blog.csdn.net/m0_37739193/article/details/79611560
3.品友大数据团队分享“百度Palo对决ClickHouse”
https://www.sohu.com/a/193083047_99982360
4.https://blog.csdn.net/lovewebeye/article/details/102739939
5.clickhouse在腾讯的应用实践 : http://www.yidianzixun.com/article/0NaOwJjF?appid=mibrowser