论文阅读-PointRCNN+python3.5实现
Brief
发表在CVPR2019,还挺新的一篇文章,前面看了一些,大部分都是在候选区域如何得到上做文章,就比如第一个voxelnet直接暴力的把所有的anchor 都弄一下,不够优美,不过这一篇最大的贡献在VFE结构,但是说下去也就是个pointnet,都是线性全连接层嘛。其二是F-pointNet。这是一篇18年CVPR的文章,就比较有想法的结合了2D去先找个视锥出来,再通过这个区域实例分割得到最后的物体,再把它框起来完事儿。不过这个阶段性有点强,严重依赖二维的detection效果。
因为这一篇在github的3D detection上取得了不少的stars,所以把它作为了我在该方向上的第三篇文章。先在知乎上看了个大概,感觉主要的贡献是抛弃的anchor这个玩意,一开始在2维上引入anchor_free时,以为会晚两年,没想到还挺快的,这一篇就不用anchor,而是采用一种对前景点的方式。**从一组前景点(这组前景点,相当于anchor了)出发,为每个前景点找到它所属于的目标框。**这和我后面要读的凯明大神19年ECCV上的voteNet貌似都是丢弃了anchor,而采用基于一种方式去代替候选框。
Q
- 固定输入
Abstruct
- 处理的是原始点云数据。
- 两阶段;阶段一:bottom-up 3Dproposal generation。阶段二:refining proposals in the canonical coordinates。
stage-1的子网络通过将点云分为前景和背景的方式,采用自下而上的形式直接生成少量优质的3D候选框。
stage-2子网络将每一个proposal的池化的点转化为canonical坐标以达到学习到更好的局部空间特征,其与在stage-1中学到的每个点的全局语义信息相结合以用于bbox的精确优化和置信度预测。
- sota KITTI
Introduction
- 目前的sota的方法采用的结合了成熟的2D检测或者3D voxel的方法
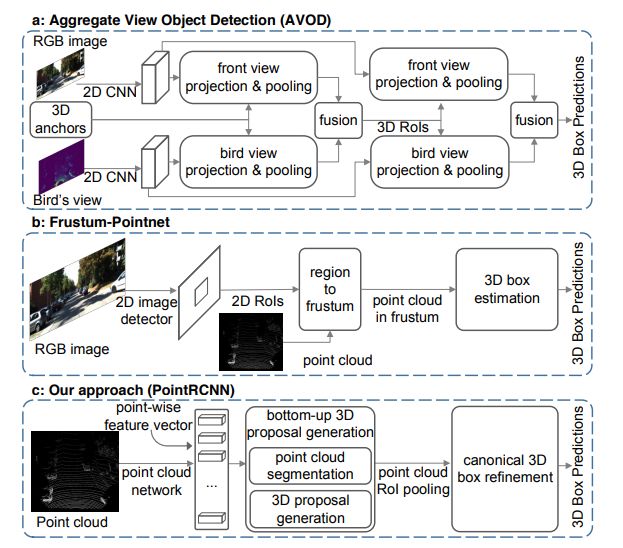
- Pointnet和F-pointnNet并且指出该方法对2D detector的依赖性太强了。
- 3D training data和2D training data最大的不同在于:用于3D对象检测的训练数据直接提供用于3D对象分割的语义掩模,在二维中这个bbox只能是一个语义分割的弱监督信息(毕竟bbox里面有很多不是interest,所以后面很多anchor_free的方法都在这方便组改进)
two stage 方法
stage-1
和sbstruct中所说的一样:
By utilizing 3D bounding boxes to generate ground-truth segmentation mask, the first stage segments foreground points and generates a small number of bounding box proposals from the segmented points simultaneously. Such a strategy avoids using the large number of 3D anchor boxes in the whole 3D space as previous methods [43, 14, 4] do and saves much computation.
这里比较好奇的是:如何使用3D bbox去生成gt和怎样分割前景和背景(后文填坑)。
stage-2
refinement。操作步骤:
(1)对stage-1中学习到的represent进行pool。
(2)优化。不是直接学习bbox的坐标差值,而是先把3D坐标转化到正交坐标系,再结合stage-1中所学习到的pooled坐标和分割mask来做坐标进行优化。
- 一种新的loss:the full bin-based 3D box regression loss
Related Work
3D object detection from 2D images
主要是从2D图像中得到一个3D的object和CAD模型这种,用到先验知识:3D几何形式。这种没有深度信息的检测得到的bbox是很粗糙的。难顶。
3D object detection from point clouds
- birds view+ 2D CNN 。信息损失
- voxel+3D CNN。信息损失+资源耗费大;一个新词语:data quantization
- F-pointnet。 对2D依赖大
- 我们的stage-1。efficient and quantization free
Learning point cloud representations
我们的工作是把poinet进一步引入到detection中来。
3. PointRCNN for Point Cloud 3D Detection
overall structure如下:
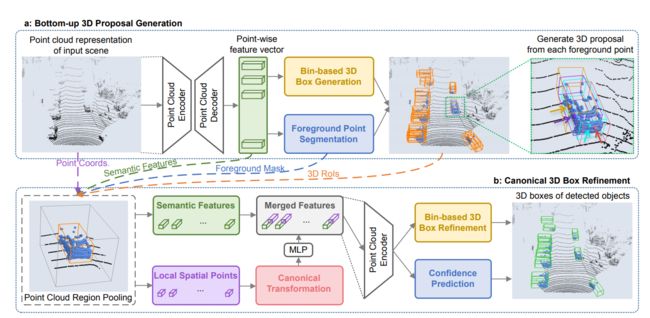
3.1 Bottom-up 3D proposal generation via point cloud segmentation
讲了一下2D中的one-stage和two-stage。但是把2D移植到3D由于空间的和点云的稀疏性是很难做到的。后面说了一下AVOD在3D中放置了80~100K个的anchor,再对每一个anchor的多视角特征进行池化得到生成的proposals。F-pointnet呢就是有的在3D中才能看到的数据,在2维度是很难看到的。
作者的stage-1:
(1)stage-1子网络是基于全场景分割的。利用先验知识:3D物体在点云中是自然分割,没有互相overlap的(这一观点不太赞同,为哈没有overlap)
(2)所谓前景就是那些在有annotations的bbox内的点。
(3)采用bottom-up的方式生成3D proposals:对点云提取point-wise features用于分割原始的数据,同时对分割为前景的点生成3D BOX。这样的Box就避免了很多个,比3D abchor-based的方法有更高的reall rate。
主要步骤如下分:
- Learning point cloud representations
- Foreground point segmentation
- Bin-based 3D bounding box generation
下面一个一个阅读:
Learning point cloud representations
我们的backbone采用的是pointnet++集合multi-scale。得到的被编码的point-wise features.
Foreground point segmentation
这里的分割和box 生成是同时做的,都是在前面的features的基础上做的。
(1) 对于分割来说,gt-maks 是由3D gt bbox产生的。对于室外场景来说,前景点比背景点少多了(这也正是文章杜宇anchor的优化吧)。所以对于不平衡的优化采用的是 focal loss,如下:
L focal ( p t ) = − α t ( 1 − p t ) γ log ( p t ) where p t = { p for forground point 1 − p otherwise \begin{array}{l}{\mathcal{L}_{\text {focal }}\left(p_{t}\right)=-\alpha_{t}\left(1-p_{t}\right)^{\gamma} \log \left(p_{t}\right)} \\ {\text { where } p_{t}=\left\{\begin{array}{ll}{p} & {\text { for forground point }} \\ {1-p} & {\text { otherwise }}\end{array}\right.}\end{array} Lfocal (pt)=−αt(1−pt)γlog(pt) where pt={p1−p for forground point otherwise
在训练中,选取的值 α t = 0.25 , γ = 2 \alpha_t=0.25,\gamma=2 αt=0.25,γ=2;
Bin-based 3D bounding box generation
- 训练时,只用回归前景点的box。不回归背景点。
- 同样采用的是7维特征回归的方式。我们提出一种bin-based regression losses。
- 预测中心位置,如下
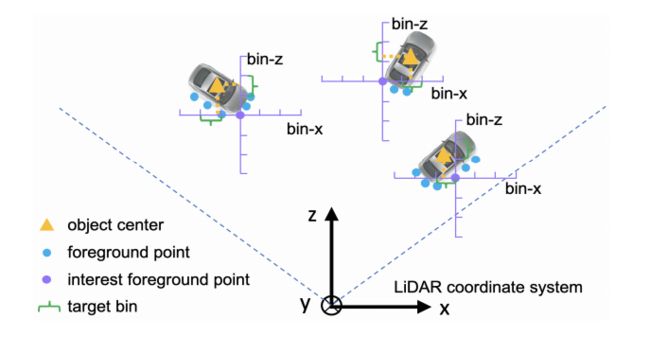
(1)首先,我终于明白了相机和liadar的z轴是车向前的方向,y轴是指向地面的。
(2)将前景点周围的区域沿着x轴和z轴划分成一块一块的Bin区域。每个轴规定了最大search范围为 s s s,这个是对整体的大坐标系来说的。
(3)对每一个1D(这是个什么意思??)的search range都是以长度 δ \delta δ来划分的,也就是每一个小坐标系坐标轴的单位长度。
(4)对X和Z轴的定位损失包含了链各个方面的loss,bin classification和residual regression。这两个采用的是交叉熵损失.对于y轴的定位,由于范围很小,所以采用的是smooth L1 loss。因此location target可以定位为:
bin x ( p ) = ⌊ x p − x ( p ) + S δ ⌋ , bin z ( p ) = ⌊ z p − z ( p ) + S δ ⌋ res u ( p ) = 1 C ( u p − u ( p ) + S − ( bin u ( p ) ⋅ δ + δ 2 ) ) res y ( p ) = y p − y ( p ) \begin{aligned} \operatorname{bin}_{x}^{(p)} &=\left\lfloor\frac{x^{p}-x^{(p)}+\mathcal{S}}{\delta}\right\rfloor, \operatorname{bin}_{z}^{(p)}=\left\lfloor\frac{z^{p}-z^{(p)}+\mathcal{S}}{\delta}\right\rfloor \\ \operatorname{res}_{u}^{(p)} &=\frac{1}{\mathcal{C}}\left(u^{p}-u^{(p)}+\mathcal{S}-\left(\operatorname{bin}_{u}^{(p)} \cdot \delta+\frac{\delta}{2}\right)\right) \\ \operatorname{res}_{y}^{(p)} &=y^{p}-y^{(p)} \end{aligned} binx(p)resu(p)resy(p)=⌊δxp−x(p)+S⌋,binz(p)=⌊δzp−z(p)+S⌋=C1(up−u(p)+S−(binu(p)⋅δ+2δ))=yp−y(p)
代表含义: b i n x ( p ) bin_{x}^{(p)} binx(p)表示gt_bin在x轴上的位置。 x p x^p xp表示gt中心点坐标, x ( p ) x^{(p)} x(p)表示感兴趣区域的前景点,也就是每个小坐标系的中心点。 r e s x ( p ) res_x^{(p)} resx(p)表示的在一个bin之类的残差值。是为了进一步精细的定位所用到的残差损失。 C C C是 bin length大小, δ \delta δ表示的是单位长度。和C一个意思,只是一个用来表示确切的大小,一个用来表示单位长度的含义。
作者把x-z空间分成了很多个bin。
同样的是,对于 θ \theta θ的回归也是采用Bin的思想,把 2 ∗ p i 2*pi 2∗pi分成若干个bin。对于 ( h , w , l ) (h,w,l) (h,w,l)则是直接回归残差值。
在推理阶段:首先选择预测出的具有最高自信度的bin center,然后把回归得到的残差加进去。
overall 3D损失:
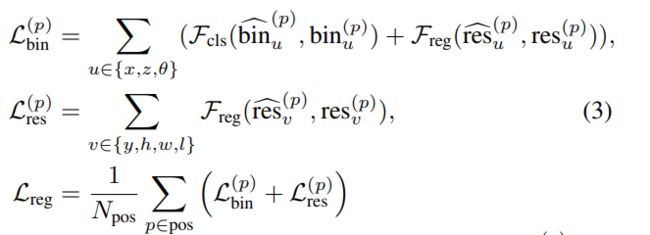
我有个疑惑, θ \theta θ是怎么存在cls损失的,不应该只有reg损失才对吗。
要知道上诉的每一个前景点都是一个兴趣点,所以出来的box也是很多的,因此作者后续会采取NMS方法对候选框缩减;是在Birds view上进行的。最后大致保留300个候选框进入第二阶段的预测。
这一段看的有点迷,回顾一下bottom-up生成候选框主要有两个步骤,其一是特征提取,采用的是pointnet+;后面两个工作一个是分割,直接采用focal-loss对每个点进行二分类就行了(是前景还是背景)。另一个工作是Box的生成,这一步不是在分割之后做的,而是在之前的特征提取之后,我们知道特征提取最后出来的张量为 [ b s , n , 128 ] [bs,n,128] [bs,n,128];假如每一个点也都是会被预测一个bbox(这不是voxel的方式还蠢??);所以作者是结合分割的mask来做,也就是只对前景点做bbox生成。
3.2 Point cloud region pooling
为了进一步从regi proposals中得到优化后的结果,我们对3D点进行池化和根据proposals对由stage-1得到的点特征进行池化。
所以呢,这一部分就是把得到的3D bbox 给扩大一点如下:
b i e = ( x i , y i , z i , h i + η , w i + η , l i + η , θ i ) \mathbf{b}_{i}^{e}=\left(x_{i}, y_{i}, z_{i}, h_{i}+\eta, w_{i}+\eta, l_{i}+\eta, \theta_{i}\right) bie=(xi,yi,zi,hi+η,wi+η,li+η,θi)
然后对所有点做一个测试,看看他有没有在这个扩大后的bbox当中,如果有的话,那么这个点的特征也会被加入到后续的refine当中。
3.3. Canonical 3D bounding box refinement
3.3.1 Canonical transformation.
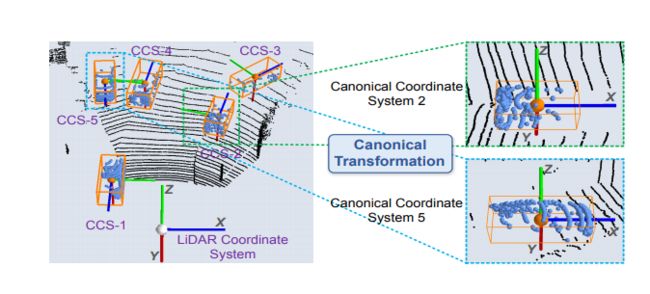
也就是上面这个图,每一个新的坐标系都是和框框的位置和朝向平行啥的,作者说这样可以得到更好的学习结果。
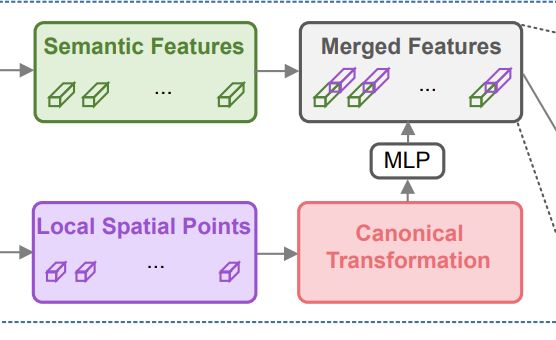
3.3.2Feature learning for box proposal refinement
这里这个优化后的网络使用的输入特征有:
- transformed local spatial points (features) p ~ \widetilde{p} p
- global semantic features f ( p ) f^{(p)} f(p)
- confidence 信息
坐标正交化后会出现的问题是,丢失了深度信息,这里要把丢失的信息补回来:
d ( p ) = ( x ( p ) ) 2 + ( y ( p ) ) 2 + ( z ( p ) ) 2 d^{(p)}=\sqrt{\left(x^{(p)}\right)^{2}+\left(y^{(p)}\right)^{2}+\left(z^{(p)}\right)^{2}} d(p)=(x(p))2+(y(p))2+(z(p))2
网络特征组合:
(1)首先呢,我们的网络先把local features p ~ \widetilde{p} p 额外的补充信息 [ r p , m p , d p ] [r^{p},m^{p},d^{p}] [rp,mp,dp]先组合起来,再给通过几层FC得到特征.
(2)再把得到的全局特征和 f ( p ) f^{(p)} f(p)整合一下。也就是局部特征和全局特征的整合。
3.3.3 Losses for box proposal refinement
我们只对和gt IOU大于0.55的做优化。
疑惑:前面生成的时候也用了gt。和这里的有什么区别?
gt bbox和proposals都需要先转化为正交坐标系中来。也就是如下转化:
b ~ i = ( 0 , 0 , 0 , h i , w i , l i , 0 ) b ~ i g t = ( x i g t − x i , y i g t − y i , z i g t − z i , h i g t , w i g t , l i g t , θ i g t − θ i ) \begin{aligned} \tilde{\mathbf{b}}_{i} &=\left(0,0,0, h_{i}, w_{i}, l_{i}, 0\right) \\ \tilde{\mathbf{b}}_{i}^{\mathrm{gt}} &=\left(x_{i}^{\mathrm{gt}}-x_{i}, y_{i}^{\mathrm{gt}}-y_{i}, z_{i}^{\mathrm{gt}}-z_{i}, h_{i}^{\mathrm{gt}}, w_{i}^{\mathrm{gt}}, l_{i}^{\mathrm{gt}}, \theta_{i}^{\mathrm{gt}}-\theta_{i}\right) \end{aligned} b~ib~igt=(0,0,0,hi,wi,li,0)=(xigt−xi,yigt−yi,zigt−zi,higt,wigt,ligt,θigt−θi)
training target:
定义的方式和前面stage-1中是一样的;对于长宽高的优化也是直接优化。
优化朝向,目标:
θ i g t − θ i \theta^{gt}_i-\theta_i θigt−θi
这个误差的范围在 [ − π / 4 , π / 4 ] [-\pi/4,\pi/4] [−π/4,π/4]之间,这是因为3D IOU大于0.55所自带的属性。因此我们把 π / 2 \pi/2 π/2以 w w w分成很多个bin;因此bin-based taeget就成了如下:
因此,在优化阶段,所有的Loss之和就是:
具有同样的疑惑,朝向为什么会有cls损失。
实验部分
细节实现
网络结构
- 输入:采样到16384个点,不足的话就重复使得也是16384个点(固定输入)
- backbone采用的是 pointnet++, set-abstraction layer采用MSG,每一个size为4096,1024,256,64四层的size。
- box proposal refinement sub-network。我们对每一个pooled的proposals采样512个点。
The training scheme(CAR)
- 阶段一所有的gt box的内点都会被当做是前景点,其余的都是背景点。扩大0.2的size, S = 3 m , δ = 0.5 m , n = 12 S = 3m,δ = 0.5m,n = 12 S=3m,δ=0.5m,n=12
- 训练阶段二网络,augment
代码实现
源码pytorch 版本的代码,就比较容易读了。对我这种新手就比较容易理解。
首先我们还是先看源码的README文件;主要是为了方便,把它的md格式直接放在网页上显示出来。主要代码分为几步:
- 环境安装
- 数据准备
- 预处理
- training
- 个人代码解读
1环境安装
这一步我就不说了,文章要求的是Py3.6。我是3.5不过我觉得问题不大,如果出了bug就继续修改就好了。
每次使用pip的时候带上清华源就很快了,秒秒钟的事情就装好了。
2 数据准备
这里使用的依然是KITTI数据集。并且按照下面的形式组织文件夹:
PointRCNN
├── data
│ ├── KITTI
│ │ ├── ImageSets
│ │ ├── object
│ │ │ ├──training
│ │ │ ├──calib & velodyne & label_2 & image_2 & (optional: planes)
│ │ │ ├──testing
│ │ │ ├──calib & velodyne & image_2
├── lib
├── pointnet2_lib
├── tools
因为我的data被放在了另外一个地方和源码是分开的,因此我们需要在后续运行代码时改一下文件路径就可以了。
3 预处理
本文以"car”做实验,数据预处理主要是根据gt增广数据:
cd tools
python generate_gt_database.py --class_name 'Car' --split train
这个文件具体的操作和含义如下:
正如文件名,也就是把含有gt的点云输入文件和对应的labels建立起gt_boxs,最后统一装入一个叫self.gt_database中。所以这样dataset也就多了一个只有含有gt的属性。
4 training
由于代码要求是python3.6及其以上的版本,我是Python3.5所以需要改正一些地方;目前只有两处内容,也就是出现:
fastai_optimazion129行的:
return f'OptimWrapper over {repr(self.opt}.\nTrue weight decay: {self.true_wd}'
改为:
return 'OptimWrapper over {}.\nTrue weight decay: {}'.format(repr(self.opt), self.true_wd)
87行的:
f'List len mismatch ({len(p)} vs {n})'
改为:
'List len mismatch ({} vs {})'.format(len(p),n)
这样就可以训练我们的RPN的阶段了,我们输入:
python train_rcnn.py --cfg_file cfgs/default.yaml --batch_size 16 --train_mode rpn --epochs 200
效果如下:

这里我想讲一下自己的一下理解和疑惑,参看博客
1RPN阶段的具体数据流动过程。
(1)数据输入大小为 [ B , N , 3 ] [B,N,3] [B,N,3],进入Pointnet++得到对应的point-wise features为 [ B , N , 128 ] [B,N,128] [B,N,128],这里的 B = 16 , N = 16384 B=16,N=16384 B=16,N=16384
(2)得到的feature会经过两个后续结构,一个做分割,一个做回归,其实都是简单的全连接层。
--------对于分割网路就是对每一个点计算一个二分类score,也就是前景和背景,再经过一个sigmod函数归一化到0~1;随后使用一个阈值得到对应的mask,这里的损失采用的是focal loss。这个比较好理解。
--------对于回归。在训练的时候,根据代码作者是采用的利用gt计算的对应的损失而不是说是前景点,整个过程如下:第一步,输出是一个 [ 16 , 16384 , 76 ] [16,16384,76] [16,16384,76]维度的tensor,其中bin loss和 res loss各占12个通道,这里为什么是12?(作者是根据X轴和Z轴上的搜索范围来的,12=6/0.5;所以是12);其二为什么是16384个而不是作者的前景点的个数呢?,作者这里代码中是先生成这么多个,但实际不会用到这些,而是会进行一个test,检测生成候选框的点是否在gt内部,如果是就算作是有效的候选框,计算它的回归损失,损失的计算的时候会把每一个兴趣点先移动到中心,然后再和其gt求差值。第三个问题,这个loss的中心怎么确定是哪个gt box的?作者在计算loss之前采用检测所有的点是否在gt中,只有在gt中的点才能算作有效的,而对应的gt-box也就是这个gt-box。