码出高效读书笔记:ConcurrentHashMap
考虑到线程并发安全性,ConcurrentHashMap是比HashMap更加推荐的一种哈希式集合。JDK8对ConcurrentHashMap进行了脱胎换骨的改造,使用了大量的lock-free技术来减轻因锁的竞争而对性能造成的影响,涉及了volatile、CAS、锁、链表、红黑树等众多知识点。
CAS:Compare And Swap,它是解决轻微冲突的多线程并发场景下使用锁造成性能损耗的一种机制。每一次执行都必须进行加锁和解锁的成本是比较高的,在并发度比较低的情况下,这种时间成本消耗是比较奢侈的。CAS就是先比较,如果不符合预期,则进行重试。CAS操作包含三个操作要素:
- 内存位置(即希望操作的变量X)
- 预期原值(假设为A)
- 新值(假设为B)
如果内存位置的值与预期原值相等(即X==A),则处理器将该位置值更新为新值(B)。如果不相等,则获取当前值,然后进行不断地轮询操作,直到成功或达到某个阀值退出,典型代码如下:
public final int getAndIncrement(){
for(;;){
int current = get();
int next = current + 1;
if(compareAndSet(current, next))
return current;
}
}
}上面示例代码中的compareAndSet的功能是与current比较,如果相等则值变为next,这个原子操作是在硬性层面来保证的,唯一要避免的就是ABA问题。
CAS是无锁策略实现的关键,当多个线程想对同一个变量的值进行更改时,任何一条线程都会使用CAS会先比较当前变量的X的值是否和自己预期值A相等,如果X==A,说明其他线程还没有对该变量进行修改,那么就可以进行更新操作,将变量X的值修改为新值B;如果X!= A,则说明变量X的值已经被其他线程更改过,此时不会执行更新操作,但是可以选择重新读取X的值再次尝试修改。
CAS操作属于乐观派,它总认为自己能成功完成操作,当多个线程尝试使用CAS操作同一个变量时,只有一个线程能胜出,完成更新操作,其他的都会失败。但是失败的线程并不会被挂起,仅仅是被告知失败,它会重新进行尝试(当然也允许线程放弃尝试)。
基于上述的原理,CAS操作即使没有锁,同样能够知道其他线程对共享变量的影响情况,并执行相应的处理措施。
另外,CAS应当属于硬件层面的原子操作。
简要介绍一下在高并发场景下的其他哈希式集合:
- HashTable:是在JDK1.0中引入的哈希式集合,以全互斥方式处理并发情况,性能极差,目前已经不再使用。
- HashMap是在JDK1.2中引入的,是非线程安全的,它最大的问题是在并发写的情况下,容易出现死链问题,导致服务不可用。
- ConcurrentHashMap是在JDK5中引入的线程安全的哈希式集合,在JDK8以前采用了分段锁的设计理念,相当于Hashtable与HashMap的折中版本,这是效率与一致性权衡后的结果。分段锁是由内部类Segment实现的,它继承于ReentrantLock,用来管理它辖区的各个HashEntry。ConcurrentHashMap被Segement分成了很多小区,segment就相当于小区的保安,HashEntry列表相当于小区业主,小区保安通过加锁的方式,保证每个Segment内都不发生冲突。
JDK11版本的ConcurrentHashMap与JDK7版本的ConcurrentHashMap进行比较,主要是由以下三点大的改造:
- 取消分段锁机制,进一步降低冲突概率;
- 引入红黑树结构。同一个哈希槽上的元素个数超过一定阀值后,单向链表改为红黑树结构;
- 使用了更加优化的方式统计集合内的元素数量。首先,Map原有的size()方法最大只能表示到2^31-1,ConcurrentHashMap额外提供了mappingCount()方法,用来返回集合内元素的数量,最大可以表示到2^63-1。此外,在元素总数更新时,使用了CAS和多种优化以提高并发能力。
下面是ConcurrentHashMap的相关属性定义,对这些信息的深刻理解有助于对整个类的体系认知:
//默认为null,ConcurrentHashMap存放数据的地方,扩容时大小总是2的幂次方
//初始化发生在第一次插入操作,数组默认初始化大小为16
transient volatile Node[] table;
//默认为null,扩容时新生成的数组,其大小为原数组的两倍
private transient volatile Node<>[K,V] nextTable;
//存储单个KV数据节点。内部有key、value、hash、next指向下一个节点
//它有4个在ConcurrentHashMap类内部定义的子类:
//TreeBin、TreeNode、ForwardingNode、ReservationNode
//前三个子类都重写了查找元素的重要方法find()
//这些节点的概念必须清晰地区分,否则极大阻碍对源码的理解
static class Node implements Map.Entry{...}
//它并不存储实际数据,维护队桶内红黑树的读写锁,存储对红黑树节点的引用
static final class TreeBin extends Node{...}
//在红黑树结构中,实际存储数据的节点
static final class TreeNode extends Node{...}
//扩容转发节点,放置此节点后,外部对原有哈希槽的操作会转发到nextTable上
static final class ForwadingNode extends Node{...}
//占位加锁节点,执行某些方法时,对其加锁,如computeIfAbsent等
static final class ReservationNode extends Node{...}
//默认为0,重要属性,用来控制table的初始化和扩容操作
//sizeCtl=-1,表示正在初始化中
//sizeCtl=-n,表示(n-1)个线程正在进行扩容中
//sizeCtl>0,初始化或扩容中需要使用的容量
//sizeCtl=0,默认值,使用默认容量进行初始化
private transient volatile int sizeCtl;
//集合size小于64,无论如何,都不会使用红黑树结构
//转化为红黑树还有一个条件是TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;
//同一个哈希桶内存储的元素个数超过此阀值时
//则将存储结构由链表转为红黑树
static final int TREEIFY_THRESHOLD = 8;
//同一个哈希桶内存储的元素个数小于等于此阀值时
//从红黑树退回至链表结构,因为元素个数较少时,链表更快
static final int UNTREEIFY_THRESHOLD = 6; 根据属性的初步认知,我们能够勾勒出ConcurrentHashMap的大致存储结构,如下图所示:

如上图所示,table的长度为64,数据存储结构分为两种:链表和红黑树。
- 当某个槽内的元素个数增加到超过8个且table的容量大于或等于64时,由链表转换为红黑树;
- 当某个槽内的元素个数减少到6个时,由红黑树重新转回链表。
链表转红黑树的过程,就是把给定顺序的元素构造成一颗红黑树的过程。需要注意的是,当table容量小于64时,只会扩容,并不会把链表转为红黑树。在转化过程中,使用同步块锁住当前槽的首元素,防止其他进程对当前槽进行增删改操作,转化完成后利用CAS替换原有链表。因为TreeBin节点也存储了next引用,所以红黑树转量表的操作就变得非常简单,只需从TreeBin的first元素开始遍历所有的节点,并把节点从TreeBin类型转化为Node类型即可,当构造好新的链表之后,会同样利用CAS替换原有红黑树。相对来说,链表转红黑树更为复杂,流程图如下图所示:
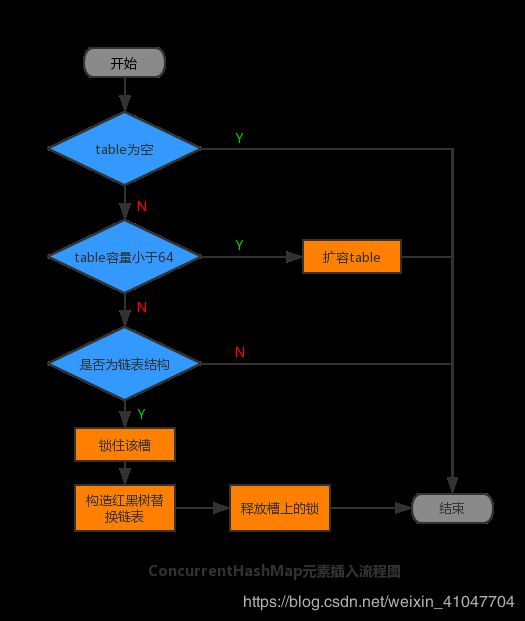
触发上述存储结构转化最主要的操作就是增加元素,即put()方法。基本思想与HashMap一致,区别就是增加了锁的处理,ConcurrentHashMap元素插入流程图如下图所示:
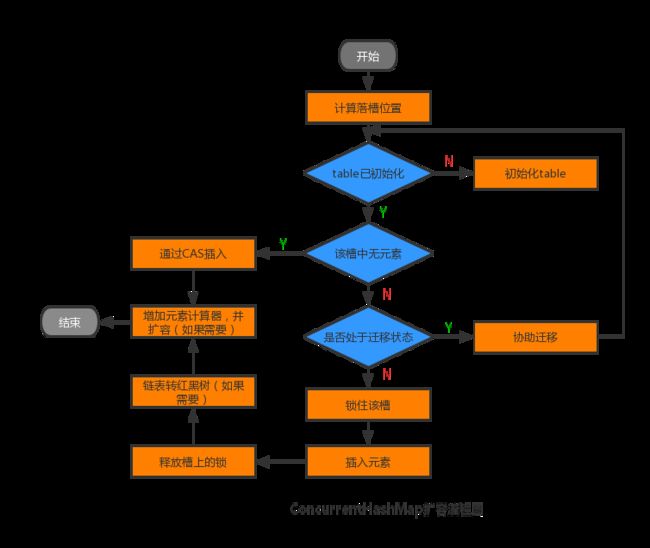
简要介绍一下Node的另外两个子类:ForwardingNode和ReservationNode。ForwardingNode在table扩容时使用,内部记录了扩容后的table,即nextTable。当table需要扩容时,依次遍历当前table中的每一个槽,如果不为null,则需要把其中所有的元素根据hash值放入扩容后的nextTable中,而原table的槽内会放置一个ForwardingNode节点。正如其名(forwarding翻译为转发),此节点也会把find()请求转发到扩容后的nextTable上,而执行put()方法的线程如果碰到此节点,也会协助进行迁移。
ReservationNode在computeIfAbsent()及其相关方法中作为一个预留节点使用。computeIfAbsent()方法会先判断相应的Key值是否已存在,如果不存在,则调用由用户实现的自定义方法来生成value值,组成KV键值对,随后插入此哈希集合中。在并发场景下,在从得知Key不存在到插入哈希集合的时间间隔内,为了防止哈希槽被其他线程抢占,当前线程会使用一个ReservationNode节点放在槽中并加锁,从而保证了线程的安全性。
最后来看一看ConcurrentHashMap对于计算集合size()的优化,需要注意的是,无论是JDK7还是JDK8,ConcurrentHashMap的size()方法都只能返回一个大致数量,无法做到100%的精准,因为已经统计过的槽在size()返回最终结果前有可能又出现了变化,从而导致返回大小与实际大小存在些许差异。在多个槽的设计下,如果仅仅是为了统计元素数量而停下所有的增删操作,又会显得因噎废食。因此,ConcurrentHashMap在设计元素总数的相关更新和计算时,会最大限度地减少锁的使用,以减少线程间的竞争与互相等待。在这个设计思路下,JDK8的ConcurrentHashMap对元素总数的计算又做了进一步的优化,具体表现在:在put()、remove()和size()方法中,设计元素总数的更新和计算,都彻底避免了锁的使用,取而代之的是众多CAS操作。
先看一下JDK7版本中的put方法和remove()方法,对于segment内部元素和计数器的更新,全部处于锁的保护下。如Segment.put()方法的第一行:
//经过这一行代码,能够保证前档线程取得该Segment上的锁,随后可以大胆地更新元素和内部计数器
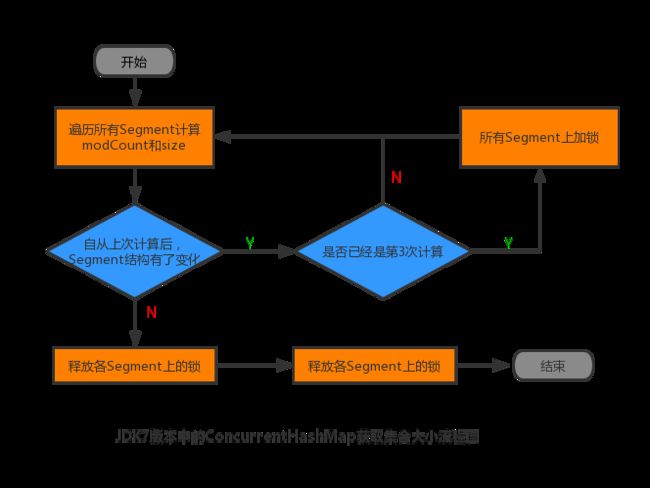
HashEntry node = tryLock() ? null : scanAndLockForPut(key, hash, value); 在JDK7中,ConcurrentHashMap在统计元素总数时已经开始避免使用锁了,毕竟加锁操作会极大地影响到其他线程对于哈希元素的修改。当经过了3次计算(2次对比)后,发现每次统计时哈希都有结构性的变化,这是它就会“气急败坏”地把所有Segment都加上所;而当自己统计完成后,才会把锁释放掉,再允许其他线程修改哈希中的元素。如下图所示:
获取集合元素个数是否还有进一步的优化空间呢?JDK8的ConcurrentHashMap给出了答案:有!前面已经分析过了,在put()中,对于哈希元素总数的更新,是置于对某个槽的锁之外的,主要会用到以下的属性:
//记录了元素总数值,主要用在无竞争状态下
//在总数更新后,通过CAS方式直接更新这个值
private transient volatile long baseCount;
//一个计数器单元,维护了一个value值
static final class CounterCell{...}
//在竞争激烈的状态下启用,线程会把总数更新情况放到该结构内
//当竞争进一步加剧时,会通过扩容减少竞争
private transient volatile CounterCell[] counterCells;正是借助了baseCount和counterCells两个属性,并配合多次使用CAS方法,JDK8中的ConcurrentHashMap避免了锁的使用。虽然源码过程看起来很复杂,但是实现思路很清晰:
- 当并发量较小时,优先使用CAS方式直接更新baseCount。
- 当更新baseCount冲突,则会认为进入到比较激烈的竞争状态,通过启用counterCells减少冲突,通过CAS的方式把总数更新情况记录在counterCells对应的位置上。
- 如果更新counterCells上的某个位置时出现了多次失败,则会通过扩容counterCells的方式减少冲突。
- 当counterCells处在扩容期间时,会尝试更新baseCount值。
对于元素总数的统计,逻辑就非常简单了,只需让baseCount加上个counterCells内的数据,就可以得出哈希内的元素总数,整个过程完全不需要加锁。
正因为ConcurrentHashMap提供了高效的锁机制实现,在各种多线程应用场景中,推荐使用此集合进行KV键值对的存储与使用。