深度学习:感受野、卷积,反池化,反卷积,卷积可解释性,CAM ,G_CAM,为什么使用CNN替代RNN?
凭什么相信你,我的CNN模型?(篇一:CAM和Grad-CAM):https://www.jianshu.com/p/1d7b5c4ecb93
凭什么相信你,我的CNN模型?(篇二:万金油LIME):http://bindog.github.io/blog/2018/02/11/model-explanation-2/
卷积和反卷积 :https://blog.csdn.net/Fate_fjh/article/details/52882134
可视化理解卷积神经网络:https://blog.csdn.net/lemianli/article/details/53171951?utm_source=blogxgwz0
图像-》特征图-》图像:
假如你想要查看Alexnet 的conv5提取到了什么东西,我们就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。
感受野
在机器视觉领域的深度神经网络中有一个概念叫做感受野,用来表示网络内部的不同位置的神经元对原图像的感受范围的大小。神经元之所以无法对原始图像的所有信息进行感知,是因为在这些网络结构中普遍使用卷积层和pooling层,在层与层之间均为局部相连(通过sliding filter)。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。因此感受野的值可以大致用来判断每一层的抽象层次。

可以看到在Conv1中的每一个单元所能看到的原始图像范围是3*3,而由于Conv2的每个单元都是由 范围的Conv1构成,因此回溯到原始图像,其实是能够看到 的原始图像范围的。因此我们说Conv1的感受野是3,Conv2的感受野是5. 输入图像的每个单元的感受野被定义为1,这应该很好理解,因为每个像素只能看到自己。
通过上图这种图示的方式我们可以“目测”出每一层的感受野是多大,但对于层数过多、过于复杂的网络结构来说,用这种办法可能就不够聪明了。因此我们希望能够归纳出这其中的规律,并用公式来描述,这样就可以对任意复杂的网络结构计算其每一层的感受野了。那么我们下面看看这其中的规律为何。
由于图像是二维的,具有空间信息,因此感受野的实质其实也是一个二维区域。但业界通常将感受野定义为一个正方形区域,因此也就使用边长来描述其大小了。在接下来的讨论中,本文也只考虑宽度一个方向。我们先按照下图所示对输入图像的像素进行编号。
接下来我们使用一种并不常见的方式来展示CNN的层与层之间的关系(如下图,请将脑袋向左倒45°观看>_<),并且配上我们对原图像的编号。

图中黑色的数字所构成的层为原图像或者是卷积层,数字表示某单元能够看到的原始图像像素。我们用 来表示第 个卷积层中,每个单元的感受野(即数字序列的长度);蓝色的部分表示卷积操作,用 和 分别表示第 个卷积层的kernel_size和stride。
对Raw Image进行kernel_size=3, stride 2的卷积操作所得到的fmap1 (fmap为feature map的简称,为每一个conv层所产生的输出)的结果是显而易见的。序列[1 2 3]表示fmap1的第一个单元能看见原图像中的1,2,3这三个像素,而第二个单元则能看见3,4,5。这两个单元随后又被kernel_size=2,stride 1的Filter 2进行卷积,因而得到的fmap2的第一个单元能够看见原图像中的1,2,3,4,5共5个像素(即取[1 2 3]和[3 4 5]的并集)。
接下来我们尝试一下如何用公式来表述上述过程。可以看到,[1 2 3]和[3 4 5]之间因为Filter 1的stride 2而错开(偏移)了两位,而3是重叠的。对于卷积两个感受野为3的上层单元,下一层最大能获得的感受野为 ,但因为有重叠,因此要减去(kernel_size - 1)个重叠部分,而重叠部分的计算方式则为感受野减去前面所说的偏移量,这里是2. 因此我们就得到 。继续往下一层看,我们会发现[1 2 3 4 5]和[3 4 5 6 7]的偏移量仍为2,并不简单地等于上一层的 ,这是因为之前的stride对后续层的影响是永久性的,而且是累积相乘的关系(例如,在fmap3中,偏移量已经累积到4了),也就是说 应该这样求
。
以此类推,
。
于是我们就可以得到关于计算感受野的抽象公式了:
,
经过简单的代数变换之后,最终形式为:
。
1、卷积:
基本特征:稀疏交互和参数共享
动机: 局部特征--卷积的核心思想 平移等变形
意义:
提高统计效率 当处理一张图像时,输入的图像可能包含成千上万个像素点,但是我们可以通过只占用几十到几百个像素点的核来检测一些局部但有意义的特征,例如图像的边缘。
减少参数:减少存储需求,加速计算

图像5*5 卷积核

图2
2维卷积的计算分为了3类,1.full 2.same 3. valid

图3
图3中蓝色为原图像,白色为对应卷积所增加的padding,通常全部为0,绿色是卷积后图片。图3的卷积的滑动是从卷积核右下角与图片左上角重叠开始进行卷积,滑动步长为1,卷积核的中心元素对应卷积后图像的像素点。可以看到卷积后的图像是4X4,比原图2X2大了,我们还记1维卷积大小是n1+n2-1,这里原图是2X2,卷积核3X3,卷积后结果是4X4,与一维完全对应起来了。其实这才是完整的卷积计算,其他比它小的卷积结果都是省去了部分像素的卷积。下面是WIKI对应图像卷积后多出部分的解释:
Kernel convolution usually requires values from pixels outside of the image boundaries. There are a variety of methods for handling image edges.意思就是多出来的部分根据实际情况可以有不同的处理方法。(其实这里的full卷积就是后面要说的反卷积)
这里,我们可以总结出full,same,valid三种卷积后图像大小的计算公式:
1.full: 滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1+N2-1 x N1+N2-1
如图3, 滑动步长为1,图片大小为2x2,卷积核大小为3x3,卷积后图像大小:4x4
2.same: 滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1xN1
3.valid:滑动步长为S,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:(N1-N2)/S+1 x (N1-N2)/S+1
如图2,滑动步长为1,图片大小为5x5,卷积核大小为3x3,卷积后图像大小:3x3
卷积核的机构以及数量 以conv2d为例
-
Tensorflow 中构造 conv2d 层的参数形状为:
[k_height, k_width]表示卷积核的大小;n_in表示“输入的通道数”,n_out表示“输出的通道数” -
通常在描述卷积核的大小时,只会说
[k_height, k_width]这一部分;比如 “这一层使用的是3*3的卷积核”。 -
但卷积核应该还包括输入的通道数
n_in,即[k_height, k_width, n_in]这部分;从几何的角度来看,卷积核应该是一个“长方体”,而不是“长方形/矩形” -
因此,卷积核的数量应该是
n_out,而不是n_in * n_out

二、反卷积(后卷积,转置卷积) 可视化
为了解释卷积神经网络为什么work,我们就需要解释CNN的每一层学习到了什么东西。为了理解网络中间的每一层,提取到特征,paper通过反卷积的方法,进行可视化。反卷积网络可以看成是卷积网络的逆过程。反卷积网络在文献《Adaptive deconvolutional networks for mid and high level feature learning》中被提出,是用于无监督学习的。然而本文的反卷积过程并不具备学习的能力,仅仅是用于可视化一个已经训练好的卷积网络模型,没有学习训练的过程。
反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到反卷积结果,用以验证显示各层提取到的特征图。举个例子:假如你想要查看Alexnet 的conv5提取到了什么东西,我们就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。
- 转置卷积(Transposed Convolution),又称反卷积(Deconvolution)、Fractionally Strided Convolution
反卷积的说法不够准确,数学上有定义真正的反卷积,两者的操作是不同的
- 转置卷积是卷积的逆过程,如果把基本的卷积(+池化)看做“缩小分辨率”的过程,那么转置卷积就是“扩充分辨率”的过程。
- 为了实现扩充的目的,需要对输入以某种方式进行填充。
- 转置卷积与数学上定义的反卷积不同——在数值上,它不能实现卷积操作的逆过程。其内部实际上执行的是常规的卷积操作。
- 转置卷积只是为了重建先前的空间分辨率,执行了卷积操作。
- 虽然转置卷积并不能还原数值,但是用于编码器-解码器结构中,效果仍然很好。——这样,转置卷积可以同时实现图像的粗粒化和卷积操作,而不是通过两个单独过程来完成。
1、空洞卷积
空洞卷积(Atrous Convolutions)也称扩张卷积(Dilated Convolutions)、膨胀卷积。
no padding ,no stride
空洞卷积的作用
-
空洞卷积使 CNN 能够捕捉更远的信息,获得更大的感受野(NLP 中可理解为获取更长的上下文);同时不增加参数的数量,也不影响训练的速度。
-
示例:Conv1D + 空洞卷积

2、反池化过程 pooling uppooling
我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。刚好最近几天看到文献:《Stacked What-Where Auto-encoders》,里面有个反卷积示意图画的比较好,所有就截下图,用这篇文献的示意图进行讲解:

以上面的图片为例,上面的图片中左边表示pooling过程,右边表示unpooling过程。假设我们pooling块的大小是3*3,采用max pooling后,我们可以得到一个输出神经元其激活值为9,pooling是一个下采样的过程,本来是3*3大小,经过pooling后,就变成了1*1大小的图片了。而upooling刚好与pooling过程相反,它是一个上采样的过程,是pooling的一个反向运算,当我们由一个神经元要扩展到3*3个神经元的时候,我们需要借助于pooling过程中,记录下最大值所在的位置坐标(0,1),然后在unpooling过程的时候,就把(0,1)这个像素点的位置填上去,其它的神经元激活值全部为0。再来一个例子:

在max pooling的时候,我们不仅要得到最大值,同时还要记录下最大值得坐标(-1,-1),然后再unpooling的时候,就直接把(-1-1)这个点的值填上去,其它的激活值全部为0。
3、反激活
我们在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,我们同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
4、反卷积
对于反卷积过程,采用卷积过程转置后的滤波器(参数一样,只不过把参数矩阵水平和垂直方向翻转了一下),这一点我现在也不是很明白,估计要采用数学的相关理论进行证明。
最后可视化网络结构如下:

网络的整个过程,从右边开始:输入图片-》卷积-》Relu-》最大池化-》得到结果特征图-》反池化-》Relu-》反卷积。
总的来说算法主要有两个关键点:1、反池化 2、反卷积,这两个源码的实现方法,需要好好理解。
计算方式
这里提到的反卷积跟1维信号处理的反卷积计算是很不一样的,FCN作者称为backwards convolution,有人称Deconvolution layer is a very unfortunate name and should rather be called a transposed convolutional layer. 我们可以知道,在CNN中有con layer与pool layer,con layer进行对图像卷积提取特征,pool layer对图像缩小一半筛选重要特征,对于经典的图像识别CNN网络,如IMAGENET,最后输出结果是1X1X1000,1000是类别种类,1x1得到的是。FCN作者,或者后来对end to end研究的人员,就是对最终1x1的结果使用反卷积(事实上FCN作者最后的输出不是1X1,是图片大小的32分之一,但不影响反卷积的使用)。
这里图像的反卷积与图3的full卷积原理是一样的,使用了这一种反卷积手段使得图像可以变大,FCN作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现end to end。
卷积 padding 卷积,transposed就是代表反卷积(转置卷积)

图7
这里说另外一种反卷积做法,假设原图是3X3,首先使用上采样让图像变成7X7,可以看到图像多了很多空白的像素点。使用一个3X3的卷积核对图像进行滑动步长为1的valid卷积,得到一个5X5的图像,我们知道的是使用上采样扩大图片,使用反卷积填充图像内容,使得图像内容变得丰富,这也是CNN输出end to end结果的一种方法。韩国作者Hyeonwoo Noh使用VGG16层CNN网络后面加上对称的16层反卷积与上采样网络实现end to end 输出,其不同层上采样与反卷积变化效果如下,

图8
到这里就把图像卷积与反卷积解释完成,如有不妥,请学者们指证。
补充一个资料:
图6与图7出处,https://github.com/vdumoulin/conv_arithmetic
------------新增反卷积过程解释----------------
经过上面的解释与推导,对卷积有基本的了解,但是在图像上的deconvolution究竟是怎么一回事,可能还是不能够很好的理解,因此这里再对这个过程解释一下。
目前使用得最多的deconvolution有2种,上文都已经介绍。
方法1:full卷积, 完整的卷积可以使得原来的定义域变大
方法2:记录pooling index,然后扩大空间,再用卷积填充
图像的deconvolution过程如下,

输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
:1.输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
2.将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
可以看出翻卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小
得到 out = (in - 1) * s + k
上图过程就是, (2 - 1) * 3 + 4 = 7
三、卷积解释性:
谈谈如何让看似黑盒的CNN模型“说话”,对它的分类结果给出一个解释。注意,本文所说的“解释”,与我们日常说的“解释”内涵不一样:例如我们给孩子一张猫的图片,让他解释为什么这是一只猫,孩子会说因为它有尖耳朵、胡须等。而我们让CNN模型解释为什么将这张图片的分类结果为猫,只是让它标出是通过图片的哪些像素作出判断的。(严格来说,这样不能说明模型是否真正学到了我们人类所理解的“特征”,因为模型所学习到的特征本来就和人类的认知有很大区别。何况,即使只标注出是通过哪些像素作出判断就已经有很高价值了,如果标注出的像素集中在地面上,而模型的分类结果是猫,显然这个模型是有问题的)
1、卷积可视化
1、特征可视化结果:
总的来说,通过CNN学习后,我们学习到的特征,是具有辨别性的特征,比如要我们区分人脸和狗头,那么通过CNN学习后,背景部位的激活度基本很少,我们通过可视化就可以看到我们提取到的特征忽视了背景,而是把关键的信息给提取出来了。从layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;layer 4学习到的则是比较有区别性的特征,比如狗头;layer 5学习到的则是完整的,具有辨别性关键特征。
2、特征学习的过程。作者给我们显示了,在网络训练过程中,每一层学习到的特征是怎么变化的,上面每一整张图片是网络的某一层特征图,然后每一行有8个小图片,分别表示网络epochs次数为:1、2、5、10、20、30、40、64的特征图:

结果:(1)仔细看每一层,在迭代的过程中的变化,出现了sudden jumps;(2)从层与层之间做比较,我们可以看到,低层在训练的过程中基本没啥变化,比较容易收敛,高层的特征学习则变化很大。这解释了低层网络的从训练开始,基本上没有太大的变化,因为梯度弥散嘛。(3)从高层网络conv5的变化过程,我们可以看到,刚开始几次的迭代,基本变化不是很大,但是到了40~50的迭代的时候,变化很大,因此我们以后在训练网络的时候,不要着急看结果,看结果需要保证网络收敛。
3、图像变换。从文献中的图片5可视化结果,我们可以看到对于一张经过缩放、平移等操作的图片来说:对网络的第一层影响比较大,到了后面几层,基本上这些变换提取到的特征没什么比较大的变化。
个人总结:我个人感觉学习这篇文献的算法,不在于可视化,而在于学习反卷积网络,如果懂得了反卷积网络,那么在以后的文献中,你会经常遇到这个算法。大部分CNN结构中,如果网络的输出是一整张图片的话,那么就需要使用到反卷积网络,比如图片语义分割、图片去模糊、可视化、图片无监督学习、图片深度估计,像这种网络的输出是一整张图片的任务,很多都有相关的文献,而且都是利用了反卷积网络,取得了牛逼哄哄的结果。所以我觉得我学习这篇文献,更大的意义在于学习反卷积网络。
2、 反卷积和导向反向传播
关于CNN模型的可解释问题,很早就有人开始研究了,姑且称之为CNN可视化吧。比较经典的有两个方法,反卷积(Deconvolution)和导向反向传播(Guided-backpropagation),通过它们,我们能够一定程度上“看到”CNN模型中较深的卷积层所学习到的一些特征。当然这两个方法也衍生出了其他很多用途,以反卷积为例,它在图像语义分割中有着非常重要的作用。(ps:目前网上有一些关于反卷积的文章,我感觉没有说的特别到位的,当然也有可能是大家理解的角度不同,但是另外一些解读那就是完全错误的了,包括某乎。不得不说,真正要深入理解反卷积还是要去啃论文,很多人嫌麻烦总是看些二手的资料,得到的认识自然是有问题的。当然这些都是题外话,我也有写一篇关于反卷积的文章的计划。看以后的时间安排)
从本质上说,反卷积和导向反向传播的基础都是反向传播,其实说白了就是对输入进行求导,三者唯一的区别在于反向传播过程中经过ReLU层时对梯度的不同处理策略。在这篇论文中有着非常详细的说明,如下图所示:
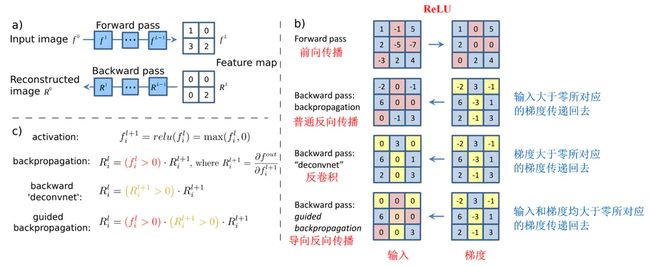
虽然过程上的区别看起来没有非常微小,但是在最终的效果上却有很大差别。如下图所示:

使用普通的反向传播得到的图像噪声较多,基本看不出模型的学到了什么东西。使用反卷积可以大概看清楚猫和狗的轮廓,但是有大量噪声在物体以外的位置上。导向反向传播基本上没有噪声,特征很明显的集中猫和狗的身体部位上。
虽然借助反卷积和导向反向传播我们“看到”了CNN模型神秘的内部,但是却并不能拿来解释分类的结果,因为它们对类别并不敏感,直接把所有能提取的特征都展示出来了。在刚才的图片中,模型给出的分类结果是猫,但是通过反卷积和导向反向传播展示出来的结果却同时包括了狗的轮廓。换句话说,我们并不知道模型到底是通过哪块区域判断出当前图片是一只猫的。要解决这个问题,我们必须考虑其他办法。
3、 CAM
大家在电视上应该都看过热成像仪生成的图像,就像下面这张图片。

图像中动物或人因为散发出热量,所以能够清楚的被看到。接下来要介绍的CAM(Class Activation Mapping)产生的CAM图与之类似,当我们需要模型解释其分类的原因时,它以热力图(Saliency Map,我不知道怎么翻译最适合,叫热力图比较直观一点)的形式展示它的决策依据,如同在黑夜中告诉我们哪有发热的物体。
对一个深层的卷积神经网络而言,通过多次卷积和池化以后,它的最后一层卷积层包含了最丰富的空间和语义信息,再往下就是全连接层和softmax层了,其中所包含的信息都是人类难以理解的,很难以可视化的方式展示出来。所以说,要让卷积神经网络的对其分类结果给出一个合理解释,必须要充分利用好最后一个卷积层。

CAM借鉴了很著名的论文Network in Network中的思路,利用GAP(Global Average Pooling)替换掉了全连接层。可以把GAP视为一个特殊的average pool层,只不过其pool size和整个特征图一样大,其实说白了就是求每张特征图所有像素的均值,一个特征层,average pool 变成一个平均值,即特征层所有的的值的平均数。

GAP的优点
在NIN的论文中说的很明确了:由于没有了全连接层,输入就不用固定大小了,因此可支持任意大小的输入;此外,引入GAP更充分的利用了空间信息,且没有了全连接层的各种参数,鲁棒性强,也不容易产生过拟合;还有很重要的一点是,在最后的 mlpconv层(也就是最后一层卷积层)强制生成了和目标类别数量一致的特征图,经过GAP以后再通过softmax层得到结果,这样做就给每个特征图赋予了很明确的意义,也就是categories confidence maps。如果你当时不理解这个categories confidence maps是个什么东西,结合CAM应该就能很快理解。
我们重点看下经过GAP之后与输出层的连接关系(暂不考虑softmax层),实质上也是就是个全连接层,只不过没有了偏置项,如图所示:

从图中可以看到,经过GAP之后,我们得到了最后一个卷积层每个特征图的均值,通过加权和得到输出(实际中是softmax层的输入)。需要注意的是,对每一个类别C,每个特征图k的均值都有一个对应的w,记为w_k^c。CAM的基本结构就是这样了,下面就是和普通的CNN模型一样训练就可以了。训练完成后才是重头戏:我们如何得到一个用于解释分类结果的热力图呢?其实非常简单,比如说我们要解释为什么分类的结果是羊驼,我们把羊驼这个类别对应的所有w_k^c取出来,求出它们与自己对应的特征图的加权和即可。由于这个结果的大小和特征图是一致的,我们需要对它进行上采样,叠加到原图上去,如下所示。

这样,CAM以热力图的形式告诉了我们,模型是重点通过哪些像素确定这个图片是羊驼了。
4、 Grad-CAM方法
前面看到CAM的解释效果已经很不错了,但是它有一个致使伤,就是它要求修改原模型的结构,导致需要重新训练该模型,这大大限制了它的使用场景。如果模型已经上线了,或着训练的成本非常高,我们几乎是不可能为了它重新训练的。于是乎,Grad-CAM横空出世,解决了这个问题。
Grad-CAM的基本思路和CAM是一致的,也是通过得到每对特征图对应的权重,最后求一个加权和。但是它与CAM的主要区别在于求权重w_k^c的过程。CAM通过替换全连接层为GAP层,重新训练得到权重,而Grad-CAM另辟蹊径,用梯度的全局平均来计算权重。事实上,经过严格的数学推导,Grad-CAM与CAM计算出来的权重是等价的。为了和CAM的权重做区分,定义Grad-CAM中第k个特征图对类别c的权重为\alpha_k^c,可通过下面的公式计算:
\alpha_k^c=\frac{1}{Z}\sum\limits_{i}\sum\limits_{j}\frac{\partial y^c}{\partial A_{ij}^k}
其中,Z为特征图的像素个数,y^c是对应类别c的分数(在代码中一般用logits表示,是输入softmax层之前的值),A_{ij}^k表示第k个特征图中,(i,j)位置处的像素值。求得类别对所有特征图的权重后,求其加权和就可以得到热力图。
L_{Grad-CAM}^c=ReLU(\sum\limits_k\alpha_k^cA^k)
Grad-CAM的整体结构如下图所示:

注意这里和CAM的另一个区别是,Grad-CAM对最终的加权和加了一个ReLU,加这么一层ReLU的原因在于我们只关心对类别c有正影响的那些像素点,如果不加ReLU层,最终可能会带入一些属于其它类别的像素,从而影响解释的效果。使用Grad-CAM对分类结果进行解释的效果如下图所示:

除了直接生成热力图对分类结果进行解释,Grad-CAM还可以与其他经典的模型解释方法如导向反向传播相结合,得到更细致的解释。

这样就很好的解决了反卷积和导向反向传播对类别不敏感的问题。当然,Grad-CAM的神奇之处还不仅仅局限在对图片分类的解释上,任何与图像相关的深度学习任务,只要用到了CNN,就可以用Grad-CAM进行解释,如图像描述(Image Captioning),视觉问答(Visual Question Answering)等,所需要做的只不过是把y^c换为对应模型中的那个值即可。限于篇幅,本文就不展开了,更多细节,强烈建议大家去读读论文,包括Grad-CAM与CAM权重等价的证明也在论文中。如果你只是想在自己的模型中使用Grad-CAM,可以参考这个链接,熟悉tensorflow的话实现起来真的非常简单,一看就明白。
5、 扩展
其实无论是CAM还是Grad-CAM,除了用来对模型的预测结果作解释外,还有一个非常重要的功能:就是用于物体检测。大家都知道现在物体检测是一个非常热门的方向,它要求在一张图片中准确的识别出多个物体,同时用方框将其框起来。物体检测对训练数据量的要求是非常高的,目前常被大家使用的有 PASCAL、COCO,如果需要更多数据,或者想要识别的物体在这些数据库中没有话,那就只能人工来进行标注了,工作量可想而知。
仔细想想我们不难发现,Grad-CAM在给出解释的同时,不正好完成了标注物体位置的工作吗?虽然其标注的位置不一定非常精确,也不一定完整覆盖到物体的每一个像素。但只要有这样一个大致的信息,我们就可以得到物体的位置,更具有诱惑力的是,我们不需要人工标注的方框就可以做到了。
顺便吐槽下当前比较火的几个物体检测模型如Faster-RCNN、SSD等,无一例外都有一个Region Proposal阶段,相当于“胡乱”在图片中画各种大小的方框,然后再来判断方框中是否有物体存在。虽然效果很好,但是根本就是违背人类直觉的。相比之下,Grad-CAM这种定位方式似乎更符合人类的直觉。当然这些纯属我个人的瞎扯,业务场景中SSD还是非常好用的,肯定要比Grad-CAM这种弱监督条件下的定位要强的多。
6、小结
试想如果当时五角大楼的研究人员知道本文介绍的这些方法,并对他们的分类结果用热力图进行解释,相信他们能很快发现热力图的红色区域主要集中在天空上,显然说明模型并没有真正学到如何判别一辆坦克,最后也就不至于闹笑话了。
回顾本文所介绍的这些方法,它们都有一个共同前提:即模型对我们来说是白盒,我们清楚的知道模型内部的所有细节,能够获取任何想要的数据,甚至可以修改它的结构。但如果我们面对的是一个黑盒,对其内部一无所知,只能提供一个输入并得到相应的输出值(比如别人的某个模型部署在线上,我们只有使用它的权利),在这种情况下,我们如何判断这个模型是否靠谱?能不能像Grad-CAM那样对分类结果给出一个解释呢?凭什么相信你,我的CNN模型?(篇二:万金油LIME)。
为什么使用CNN替代RNN?
RNN/LSTM 存在的问题(3)
-
RNN 与目前的硬件加速技术不匹配
训练 RNN 和 LSTM 非常困难,因为计算能力受到内存和带宽等的约束。简单来说,每个 LSTM 单元需要四个仿射变换,且每一个时间步都需要运行一次,这样的仿射变换会要求非常多的内存带宽。添加更多的计算单元很容易,但添加更多的内存带宽却很难——这与目前的硬件加速技术不匹配,一个可能的解决方案就是让计算在存储器设备中完成。
-
RNN 容易发生梯度消失,包括 LSTM
在长期信息访问当前处理单元之前,需要按顺序地通过所有之前的单元。这意味着它很容易遭遇梯度消失问题;LSTM 一定程度上解决了这个问题,但 LSTM 网络中依然存在顺序访问的序列路径;实际上,现在这些路径甚至变得更加复杂
-
注意力机制模块(记忆模块)的应用
- 注意力机制模块可以同时前向预测和后向回顾。
- 分层注意力编码器(Hierarchical attention encoder)
- 分层注意力模块通过一个层次结构将过去编码向量汇总到一个上下文向量
C_t——这是一种更好的观察过去信息的方式(观点) - 分层结构可以看做是一棵树,其路径长度为
logN,而 RNN/LSTM 则相当于一个链表,其路径长度为N,如果序列足够长,那么可能N >> logN
放弃 RNN/LSTM 吧,因为真的不好用!望周知~ - CSDN博客
任务角度(1)
- 从任务本身考虑,我认为也是 CNN 更有利,LSTM 因为能记忆比较长的信息,所以在推断方面有不错的表现(直觉);但是在事实类问答中,并不需要复杂的推断,答案往往藏在一个 n-gram 短语中,而 CNN 能很好的对 n-gram 建模。