自动迭代方案——行为序列异常检测项目A
antiplugin_sl_zx项目:
- 数据样本
- 模型训练
- 外挂预测
文章目录
- 1. 项目结构
- 1.1 Data模块
- 1.1.1 数据保存
- 1.2 Training模块
- 1.2.1 迭代方案
- 1.2.2 甘特图
- 1.2.3 模型保存
- 1.3 Prediction模块
- 1.3.1 预测方案
- 1.3.2 结果呈现
- 2. 启动脚本
- 2.1 Crontab定时任务
- 2.2 Shell模块任务
- 2.2.1 data.sh
- 2.2.2 train.sh
- 2.2.3 predict.sh
- 2.3 Python文件构成
- 2.3.1 文件分类
- 2.3.2 流程图
- 3. 源码分析
- 3.1 数据模块
- 3.1.1 get_ids.py -- Hive获取样本用户ID
- 3.1.2 dataloader.py -- Hbase获取样本行为序列
- 3.2 训练模块
- 3.2.1 MLPModel.py -- MLP监督模型
- 3.2 预测模块
- 3.2.1 mlp_predict.py -- MLP进行模型预测
1. 项目结构
1.1 Data模块
1.1.1 数据保存
- 按天存储
# $DATD_PATH 为数据保存路径
zhoujialiang@***:~$ cd $DATD_PATH
zhoujialiang@***:$DATD_PATH$ ls
20181212 20181218 20181224 20181230 20190105 20190111 20190117 20190123 20190129
20181213 20181219 20181225 20181231 20190106 20190112 20190118 20190124 20190130
20181214 20181220 20181226 20190101 20190107 20190113 20190119 20190125 20190131
20181215 20181221 20181227 20190102 20190108 20190114 20190120 20190126 20190201
20181216 20181222 20181228 20190103 20190109 20190115 20190121 20190127 20190202
20181217 20181223 20181229 20190104 20190110 20190116 20190122 20190128 20190203
1.2 Training模块
1.2.1 迭代方案
| Type | Update Frequency | Data Source Range |
|---|---|---|
| Baseline | 不更新 | 始终使用初始四周的数据作为训练样本 |
| Increment | 每周五 | 初始与baseline相同,之后每次更新新增一周的数据,即第 k k k次更新后包含了 k + 1 k+1 k+1周的数据 |
| Sliding Window | 每周五 | 初始与baseline相同,之后每次更新替换新一周的数据,即始终只包含 4 4 4周的数据 |
1.2.2 甘特图
Mon 17 Mon 24 Mon 31 Mon 07 Mon 14 Mon 21 4 weeks 4 weeks 4 weeks 4 weeks 5 weeks 6 weeks 4 weeks 4 weeks 4 weeks Baseline Increment Sliding Window Auto-Iteration Schedule
1.2.3 模型保存
- 模型目录命名规则:MODEL_DIR=
${ds_start}_${ds_range}
| Type | Example |
|---|---|
| Baseline | 20181212_28 |
| Increment | 20181212_35, 20181212_42, 20181212_49 |
| Sliding Window | 20181219_28, 20181226_28, 20190102_28 |
- 查看模型目录
zhoujialiang@***:~$ cd $MODEL_PATH
zhoujialiang@***:$MODEL_PATH$ ls
20181212_28 20181212_35 20181212_42 20181212_49 20181219_28 20181226_28 20190102_28
1.3 Prediction模块
1.3.1 预测方案
| Step | Operation | Description |
|---|---|---|
| 1 | 样本获取 | 每十五分钟,获取最新数据样本,保存至对应目录 |
| 2 | 模型预测 | 样本获取完毕后,馈入模型预测结果 |
| 3 | 结果上传 | 预测结果保存至MySQL |
1.3.2 结果呈现
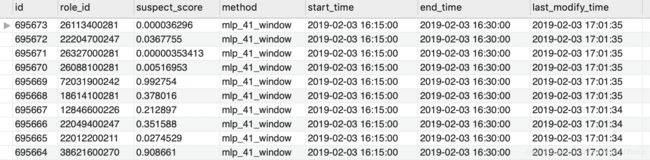
2. 启动脚本
2.1 Crontab定时任务
# zhuxiangua_data,每天10:00拉取数据
0 10 * * * bash /home/zhoujialiang/nsh_zhuxian_sl_auto/data.sh 41 1 >/home/zhoujialiang/cron_zhuxiangua_data.log 2>&1
# zhuxiangua_train,每周五17:25训练模型
25 17 * * 5 bash /home/zhoujialiang/nsh_zhuxian_sl_auto/train.sh >/home/zhoujialiang/cron_zhuxiangua_train.log 2>&1
# zhuxiangua_predict,每15分钟预测一次
*/15 * * * * bash /home/zhoujialiang/nsh_zhuxian_sl_auto/predict.sh 41 >/home/zhoujialiang/cron_zhuxiangua_pred.log 2>&1
2.2 Shell模块任务
2.2.1 data.sh
#!/usr/bin/env bash
# Usage_1(single day): bash data.sh 41 20181215 1
# Usage_2(ds range): bash data.sh 41 `date -d "-31 days" +%Y%m%d` 28
# 安装依赖
#apt-get update
#apt-get install -y libsasl2-dev cyrus-sasl2-heimdal-dbg python3-dev
#pip install -r requirements.txt
# 工作目录
WORK_DIR=/home/zhoujialiang/online_zhuxian
# 定义参数
grade=$1
ds_num=$2
ds_start=`date -d "-3 days" +%Y%m%d`
# 正样本id
echo /usr/bin/python3 $WORK_DIR/get_ids.py pos --end_grade $grade --ds_start $ds_start --ds_num $ds_num &&
/usr/bin/python3 $WORK_DIR/get_ids.py pos --end_grade $grade --ds_start $ds_start --ds_num $ds_num &&
# 全量样本id
echo /usr/bin/python3 $WORK_DIR/get_ids.py total --end_grade $grade --ds_start $ds_start --ds_num $ds_num &&
/usr/bin/python3 $WORK_DIR/get_ids.py total --end_grade $grade --ds_start $ds_start --ds_num $ds_num &&
# 拉取数据
echo /usr/bin/python3 $WORK_DIR/dataloader.py --end_grade $grade --ds_start $ds_start --ds_num $ds_num &&
/usr/bin/python3 $WORK_DIR/dataloader.py --end_grade $grade --ds_start $ds_start --ds_num $ds_num
2.2.2 train.sh
#!/usr/bin/env bash
# Usage_1: bash train.sh
# 工作目录
WORK_DIR=/home/zhoujialiang/online_zhuxian
# 定义参数
ds_start=`date -d "wednesday -5 weeks" +%Y%m%d` # 距当日最近的第五个周三,滑窗模型数据开始日期
stamp_end=`date -d "-2 days" +%s`
stamp_start=`date -d "20181212" +%s`
stamp_diff=`expr $stamp_end - $stamp_start`
day_diff=`expr $stamp_diff / 86400` # 增量模型的数据日期跨度
# 增量迭代模型
echo /usr/bin/python3 $WORK_DIR/MLPModel.py --ds_start 20181212 --ds_num $day_diff &&
/usr/bin/python3 $WORK_DIR/MLPModel.py --ds_start 20181212 --ds_num $day_diff &&
# 滑窗迭代模型
echo /usr/bin/python3 $WORK_DIR/MLPModel.py --ds_start $ds_start --ds_num 28 &&
/usr/bin/python3 $WORK_DIR/MLPModel.py --ds_start $ds_start --ds_num 28
- shell按星期定位规则
# 假定当天日期:20190207 Wed
echo `date -d "wednesday -1 weeks" +%Y%m%d` # 20190206 Wed
echo `date -d "wednesday 0 weeks" +%Y%m%d` # 20190213 Wed
# 假定当天日期:20190206 Wed
echo `date -d "wednesday -1 weeks" +%Y%m%d` # 20190130 Wed
echo `date -d "wednesday 0 weeks" +%Y%m%d` # 20190206 Wed
2.2.3 predict.sh
#!/usr/bin/env bash
# 工作目录
WORK_DIR=/home/zhoujialiang/nsh_zhuxian_sl_auto
# 定义参数
end_grade=$1 # 结束等级
ds_pred=`date -d "0 days" +%Y%m%d` # 当前日期
ts_pred_cur=`date -d "0 days" "+%Y%m%d %H:%M:%S"` # 当前时间
ts_pred_start=`date -d "$ts_pred_cur 45 minutes ago" +%Y%m%d#%H:%M` # 十五分钟前
# 定位到过去最近的周五,即从每周的周六开始使用新的模型进行预测
last_friday=`date -d "friday -1 weeks" +%Y%m%d`
# 通过周五定位到当前滑窗模型的数据样本开始日期
ds_start=`date -d "$last_friday -30 days" +%Y%m%d`
# 计算日期差
stamp_end=`date -d "$last_friday -2 days" +%s`
stamp_start=`date -d "20181212" +%s`
stamp_diff=`expr $stamp_end - $stamp_start`
day_diff=`expr $stamp_diff / 86400`
# baseline
echo /usr/bin/python3 $WORK_DIR/mlp_predict.py --end_grade $end_grade --ds_pred $ds_pred --ts_pred_start ${ts_pred_start}:00 --ds_start 20181212 --ds_num 28 --method mlp_41_baseline;
/usr/bin/python3 $WORK_DIR/mlp_predict.py --end_grade $end_grade --ds_pred $ds_pred --ts_pred_start ${ts_pred_start}:00 --ds_start 20181212 --ds_num 28 --method mlp_41_baseline;
# incre
echo /usr/bin/python3 $WORK_DIR/mlp_predict.py --end_grade $end_grade --ds_pred $ds_pred --ts_pred_start ${ts_pred_start}:00 --ds_start 20181212 --ds_num $day_diff --method mlp_41_incre;
/usr/bin/python3 $WORK_DIR/mlp_predict.py --end_grade $end_grade --ds_pred $ds_pred --ts_pred_start ${ts_pred_start}:00 --ds_start 20181212 --ds_num $day_diff --method mlp_41_incre;
# window
echo /usr/bin/python3 $WORK_DIR/mlp_predict.py --end_grade $end_grade --ds_pred $ds_pred --ts_pred_start ${ts_pred_start}:00 --ds_start $ds_start --ds_num 28 --method mlp_41_window;
/usr/bin/python3 $WORK_DIR/mlp_predict.py --end_grade $end_grade --ds_pred $ds_pred --ts_pred_start ${ts_pred_start}:00 --ds_start $ds_start --ds_num 28 --method mlp_41_window
2.3 Python文件构成
2.3.1 文件分类
- data
get_ids.pydataloader.py
- train
MLPModel.py
- predict
mlp_predict.py
2.3.2 流程图
hive
hbase
train
sum up
predict
get_ids.py
ids
dataloader.py
daily_data
mlp_predict.py
MLPModel.py
model
train_data
classification
3. 源码分析
3.1 数据模块
3.1.1 get_ids.py – Hive获取样本用户ID
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#!/usr/bin/env python
# -*- coding: utf-8 -*-
################################################################################
#
# Copyright (c) 2019 ***.com, Inc. All Rights Reserved
# The NSH Anti-Plugin Project
################################################################################
"""
NSH主线挂自动迭代项目 -- Hive拉取ids
从Hive获取指定等级、开始和结束日期的正负样本ID
Usage: python get_ids.py pos --end_grade 41 --ds_start 20181215 --ds_num 7
Authors: Zhou Jialiang
Email: [email protected]
Date: 2019/02/13
"""
import os
import argparse
import json
import logging
from datetime import datetime, timedelta
import log
from config import SAVE_DIR_BASE, PROJECT_DIR
from config import QUERY_DICT
from HiveUtils import get_ids
def parse_args():
parser = argparse.ArgumentParser("Run trigger_sanhuan"
"Usage: python get_ids.py pos --end_grade 41 --ds_start 20181215 --ds_num 7")
parser.add_argument('label', help='\'pos\' or \'total\'')
parser.add_argument('--end_grade', type=str)
parser.add_argument('--ds_start', type=str)
parser.add_argument('--ds_num', type=int)
return parser.parse_args()
if __name__ == '__main__':
# 输入参数:等级,开始和结束日期
args = parse_args()
label = args.label
start_grade = 0
end_grade = args.end_grade
ds_start = datetime.strptime(args.ds_start, '%Y%m%d').strftime('%Y-%m-%d')
# logging
log.init_log(os.path.join(PROJECT_DIR, 'logs', 'get_ids'))
# trigger目录
trigger_dir = os.path.join(SAVE_DIR_BASE, 'trigger')
if not os.path.exists(trigger_dir):
os.mkdir(trigger_dir)
# 遍历日期,按天拉取获取封停id
for ds_delta in range(args.ds_num):
# 数据日期
ds_data = (datetime.strptime(ds_start, '%Y-%m-%d') + timedelta(days=ds_delta)).strftime('%Y-%m-%d')
logging.info('Start pulling {} ids on date: {}'.format(label, ds_data))
# query
sql = QUERY_DICT[label].format(ds_portrait=ds_data, end_grade=end_grade, ds_start=ds_data, ds_end=ds_data)
# 保存路径
filename_ids = '{ds_data}_{label}'.format(ds_data=ds_data.replace('-', ''), label=label)
ids_path = os.path.join(trigger_dir, filename_ids)
if os.path.exists(ids_path):
with open(ids_path, 'r') as f:
ids = json.load(f)
if len(ids) > 0:
logging.info('File {} already exists, skip pulling ids'.format(ids_path))
else:
logging.info('File {} is empty, restart pulling ids'.format(ids_path))
ids = get_ids(sql, ids_path)
logging.info('Finish pulling {} ids on date: {}'.format(label, ds_data))
else:
ids = get_ids(sql, ids_path)
logging.info('Finish pulling {} ids on date: {}'.format(label, ds_data))
3.1.2 dataloader.py – Hbase获取样本行为序列
- 多线程分析(待完成)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
################################################################################
#
# Copyright (c) 2019 ***.com, Inc. All Rights Reserved
# The NSH Anti-Plugin Project
################################################################################
"""
NSH主线挂自动迭代项目 -- 序列拉取模块
Usage: python dataloader.py --end_grade 41 --ds_start 20181215 --ds_num 7
Authors: Zhou Jialiang
Email: [email protected]
Date: 2019/02/13
"""
import os
import sys
import argparse
import logging
import logging.handlers
from queue import Queue
import _thread
import threading
import json
import requests
from time import sleep
from datetime import datetime, timedelta
from config import SAVE_DIR_BASE, THREAD_NUM, HBASE_URL
lock = _thread.allocate_lock()
# 时间统计格式
TIME_FORMAT = '%Y-%m-%d'
# LOG配置
LOG_FILE = 'logs/dataloader_hbase.log' # 日志文件
SCRIPT_FILE = 'dataloader_hbase' # 脚本文件
LOG_LEVEL = logging.DEBUG # 日志级别
LOG_FORMAT = '%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s' # 日志格式
def parse_args():
parser = argparse.ArgumentParser('Pulling data sequneces'
'Usage: python dataloader.py --end_grade 41 --ds_start 20181215 --ds_num 7')
parser.add_argument('--end_grade', type=str)
parser.add_argument('--ds_start', type=str)
parser.add_argument('--ds_num', type=int)
parser.add_argument('--ts_pred_start', type=str, default='')
return parser.parse_args()
def init_log():
handler = logging.handlers.RotatingFileHandler(LOG_FILE) # 实例化handler
formatter = logging.Formatter(LOG_FORMAT, datefmt="%Y-%m-%d %H:%M:%S") # 实例化formatter
handler.setFormatter(formatter) # 为handler添加formatter
logger = logging.getLogger(SCRIPT_FILE) # 获取logger
logger.addHandler(handler) # 为logger添加handler
logger.setLevel(LOG_LEVEL)
return logger
def get_ids(path_ids):
"""从 trigger file 获取样本id
Args:
path_ids: trigger file 的地址
"""
ids = list()
if os.path.exists(path_ids):
with open(path_ids, 'r') as f:
ids = json.load(f)
else:
print('No ban_ids file')
return ids
class SequenceDataReader(threading.Thread):
"""序列数据读取类
Attributes:
logger: 日志
queue: 多线程队列
start_grade: 开始等级
end_grade: 结束等级
save_dir: 序列保存路径
"""
def __init__(self, logger, queue, start_grade, end_grade, save_dir):
threading.Thread.__init__(self)
self.logger = logger
self.queue = queue
self.start_grade = start_grade
self.end_grade = end_grade
self.save_dir = save_dir
def read_data(self, role_id):
"""从hbase拉取数据
Args:
role_id: 样本用户ID
Return:
seq: 样本用户行为序列
"""
url = HBASE_URL.format(sg=self.start_grade, eg=self.end_grade, ids=role_id)
response = requests.post(url, timeout=600)
results = response.json()
result = results[0]
logids = result['role_seq']
seq = [k['logid'] for k in logids]
return seq
def save_to_file(self, role_id, seq):
"""保存行为序列
Args:
role_id: 样本用户ID
seq: 样本用户行为序列
"""
filename = os.path.join(self.save_dir, role_id)
with open(filename, 'w') as f:
json.dump(seq, f, indent=4, sort_keys=True)
def run(self):
"""多线程拉取运行接口
遍历队列中的样本ID,拉取行为序列,并保存至相应目录
"""
global lock
# 循环读取queue中数据
while True:
if self.queue.qsize() % 1000 == 0:
self.logger.info('{} id left'.format(self.queue.qsize()))
lock.acquire()
if self.queue.empty():
lock.release()
return
role_id = self.queue.get()
lock.release()
try:
# 读取数据
seq = self.read_data(role_id)
sleep(5)
# 存入文件
self.save_to_file(role_id, seq)
except Exception as e:
self.logger.error('error with id = {}, error = {}'.format(role_id, e))
# 若失败则重新放入队列
lock.acquire()
self.queue.put(role_id)
lock.release()
# 主函数
def main(argv):
"""主函数
拉取指定用户ID对应的0-41级行为序列并保存
"""
# 输入参数:行为截止等级,开始和结束日期
args = parse_args()
start_grade = 0
end_grade = args.end_grade
ds_start = '{}-{}-{}'.format(args.ds_start[:4], args.ds_start[4:6], args.ds_start[6:])
ts_pred_start = args.ts_pred_start
# 遍历日期,按天拉取序列并保存
for ds_delta in range(args.ds_num):
# 数据日期
ds_data = (datetime.strptime(ds_start, '%Y-%m-%d') + timedelta(days=ds_delta)).strftime('%Y-%m-%d')
print('Start pulling total sequence on date: {}'.format(ds_data))
# id文件
if ts_pred_start == '':
path_ids = os.path.join(SAVE_DIR_BASE, 'trigger', '{ds_data}_total'.format(ds_data=ds_data.replace('-', '')))
else:
path_ids = os.path.join(SAVE_DIR_BASE, 'trigger', '{ts_pred_start}'.format(ts_pred_start=ts_pred_start))
print(path_ids)
# logger
_logger = init_log()
# 队列,用于多线程
queue = Queue()
# 创建数据目录
souce_dir = os.path.join(SAVE_DIR_BASE, 'data', ds_data.replace('-', ''))
if not os.path.exists(souce_dir):
os.mkdir(souce_dir)
# 记录已保存序列的id,避免中断后重复拉取
filenames = os.listdir(souce_dir)
ids_exists = set([filename.split('_')[0] for filename in filenames])
# 需拉取序列id放入队列
for role_id in get_ids(path_ids):
if role_id not in ids_exists:
queue.put(role_id)
# 线程
thread_list = []
thread_num = THREAD_NUM
for i in range(thread_num):
_logger.info('init thread = {}'.format(i))
thread = SequenceDataReader(_logger, queue, start_grade, end_grade, souce_dir)
thread_list.append(thread)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
print('Finish pulling total sequence on date: {}'.format(ds_data))
if __name__ == '__main__':
main(sys.argv)
3.2 训练模块
3.2.1 MLPModel.py – MLP监督模型
#!/usr/bin/python
# -*- coding:utf-8 -*-
################################################################################
#
# Copyright (c) 2019 ***.com, Inc. All Rights Reserved
# The NSH Anti-Plugin Project
################################################################################
"""
NSH主线挂自动迭代项目 -- 离线训练模块,MLP模型
Usage: python MLPModel.py --ds_start 20181212 --ds_num 28 ...
Authors: Zhou Jialiang
Email: [email protected]
Date: 2019/02/13
"""
import argparse
import numpy as np
from datetime import datetime, timedelta
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import load_model, Sequential
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras import regularizers
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from SupervisedModel import SupervisedModel
from FeatureEngineering import *
from config import SAVE_DIR_BASE, PROJECT_DIR
class MLPModel(SupervisedModel):
"""MLP模型
Attributes:
_feature_train: 训练数据
_label_train: 训练标签
_feature_test: 测试数据
_feature_label: 测试标签
_feature_type: 特征提取方式
_ids: 样本ID
_max_len: 最大长度限制
_embedding_dropout_size: embedding的dropout大小
_dense_size_1: 第一层dense层大小
_dense_size_1: 第二层dense层大小
_dense_dropout_size: dense层的dropout大小
_model_file: 模型保存路径
"""
def __init__(self, train_data, test_data, feature_type, save_path='base', epoch=30, batch_size=128, dropout_size=0.2,
regular=0.002, dense_size_1=128, dense_size_2=128, ids=None):
SupervisedModel.__init__(self, epoch=epoch, batch_size=batch_size, regular=regular)
'''Data'''
assert len(train_data) == 2 and len(test_data) == 2
self._feature_train, self._label_train = train_data
self._feature_test, self._label_test = test_data
self._feature_test = np.array(self._feature_test)
self._feature_train = np.array(self._feature_train)
self._feature_type = feature_type
self._ids = ids
'''Network'''
self._embedding_dropout_size = dropout_size
self._dense_size_1 = dense_size_1
self._dense_size_2 = dense_size_2
self._dense_dropout_size = dropout_size
self._model_file = os.path.join(save_path, 'mlp_feature_{feature}_dense1_{dense_size1}_dense2_{dense_size2}'.format(
feature=self._feature_type,
dense_size1=self._dense_size_1,
dense_size2=self._dense_size_2))
def model(self):
"""Model定义及训练
"""
log('[{time}] Building model...'.format(time=get_time()))
model = Sequential()
model.add(Dense(self._dense_size_1, input_dim=len(self._feature_train[0]), activation='relu',
kernel_regularizer=regularizers.l1(self._regular)))
model.add(Dense(self._dense_size_2, activation='relu', kernel_regularizer=regularizers.l1(self._regular)))
model.add(Dense(1, activation='sigmoid'))
# if os.path.exists(self.model_file):
# model.load_weights(self.model_file)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', self.precision, self.recall, self.f1_score])
log(model.summary())
# checkpoint
checkpoint = ModelCheckpoint(self._model_file + '.{epoch:03d}-{val_f1_score:.4f}.hdf5', monitor='val_f1_score',
verbose=1, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
log('[{time}] Training...'.format(time=get_time()))
model.fit(self._feature_train,
self._label_train,
epochs=self._epoch,
callbacks=callbacks_list,
validation_data=(self._feature_test, self._label_test))
# 离线训练调用接口
def run(self):
self.model()
def run_predict(self, model_path, ts_pred_start):
"""离线训练调用接口
"""
# 加载模型
model = load_model(model_path, compile=False)
# 预测
suspect_scores = model.predict(self._feature_train)
print(len(self._ids), len(suspect_scores))
# 保存文件,返回预测结果
result_file = 'mlp_{ts_pred_start}'.format(ts_pred_start=ts_pred_start)
pred_dir = os.path.join(SAVE_DIR_BASE, 'classification')
if not os.path.exists(pred_dir):
os.mkdir(pred_dir)
results = list()
with open(os.path.join(pred_dir, result_file), 'w') as f:
for i in range(len(self._ids)):
role_id = str(self._ids[i])
suspect_score = str(suspect_scores[i][0])
f.write(role_id + ',' + suspect_score + '\n')
results.append([role_id, suspect_score])
return results
if __name__ == '__main__':
parser = argparse.ArgumentParser('MLP Model Train, feature generation and model train. \n'
'Usage: python MLPModel.py ds_range_list ... ..')
parser.add_argument('--ds_start', type=str)
parser.add_argument('--ds_num', type=int)
parser.add_argument('--feature', help='set specified feature generated for training. available: '
'\'freq\', \'freqg\', \'seq\', \'tseq\', \'time\', \'timeg\'', default='freq')
parser.add_argument('--epoch', help='set the training epochs', default=30, type=int)
parser.add_argument('--batch_size', help='set the training batch size', default=128, type=int)
parser.add_argument('--dropout_size', help='set the dropout size for fc layer or lstm cells', default=0.2, type=float)
parser.add_argument('--regular', help='set regularization', default=0.0, type=float)
parser.add_argument('--dense_size_1', help='set dense size 1', default=64, type=int)
parser.add_argument('--dense_size_2', help='set dense size 2', default=32, type=int)
parser.add_argument('--test_size', help='set test ratio when splitting data sets into train and test', default=0.2, type=float)
parser.add_argument('--sampling_type', help='set sampling type, \'up\' or \'down\'', default='up')
parser.add_argument('--max_num', help='max num of data of each label', default=0, type=int)
args = parser.parse_args()
ds_start = args.ds_start
ds_num = args.ds_num
cal_ds = lambda ds_str, ds_delta: (datetime.strptime(ds_str, '%Y%m%d') + timedelta(days=ds_delta)).strftime('%Y%m%d')
ds_list = [cal_ds(ds_start, ds_delta) for ds_delta in range(ds_num)]
# 数据路径
data_path_list = [os.path.join(SAVE_DIR_BASE, 'data', ds_range) for ds_range in ds_list]
logid_path = os.path.join(PROJECT_DIR, 'logid', '41')
# 模型保存路径
PATH_MODEL_SAVE = os.path.join(SAVE_DIR_BASE, 'model', '{}_{}'.format(ds_start, ds_num))
if not os.path.exists(PATH_MODEL_SAVE):
os.mkdir(PATH_MODEL_SAVE)
# 导入数据,训练
data = eval('Ev{feature}Loader_hbase(data_path_list, logid_path=logid_path, sampling_type=args.sampling_type, '
'test_size=args.test_size, max_num=args.max_num)'.format(feature=args.feature))
data.run()
model = MLPModel(train_data=data.train_data, test_data=data.test_data, feature_type=args.feature, save_path=PATH_MODEL_SAVE,
epoch=args.epoch, batch_size=args.batch_size, dropout_size=args.dropout_size,
regular=args.regular, dense_size_1=args.dense_size_1, dense_size_2=args.dense_size_2)
model.run()
3.2 预测模块
3.2.1 mlp_predict.py – MLP进行模型预测
#!/usr/bin/python
# -*- coding:utf-8 -*-
################################################################################
#
# Copyright (c) 2019 ***.com, Inc. All Rights Reserved
# The NSH Anti-Plugin Project
################################################################################
"""
NSH主线挂自动迭代项目 -- MLP模型预测脚本
Usage: python mlp_predict.py --end_grade 41 --ds_pred 20190122 --ts_pred_start 20190122#13:20:00 --ds_start 20181212 --ds_num 28
Authors: Zhou Jialiang
Email: [email protected]
Date: 2019/02/13
"""
import os
import argparse
import json
import gc
import logging
import requests
from datetime import datetime, timedelta
import log
from MLPModel import MLPModel
from FeatureEngineering import EvfreqLoader_hbase_pred
from config import SAVE_DIR_BASE, PROJECT_DIR
from config import FETCH_ID_URL, INSERT_SQL, TIME_FORMAT, MINUTE_DELTA
from config import MySQL_HOST_IP, MySQL_HOST_PORT, MySQL_HOST_USER, MySQL_HOST_PASSWORD, MySQL_TARGET_DB
from MySQLUtils import MysqlDB
def fetch_id(grade, ts_start, ts_end):
'''实时接口
实时接口获取id
需到达42级的才能确保41级的行为序列完整
Args:
grade: 结束等级
ts_start: 预测行为开始时间
ts_end: 预测行为结束时间
Returns:
待预测用户ID
'''
url = FETCH_ID_URL.format(st=ts_start, ed=ts_end)
try:
r = requests.post(url, timeout=600)
result = r.json()['result']
except Exception as e:
print('fetch_id error, url={}, e={}'.format(url, e))
return []
ids = [i['role_id'] for i in result if i['level'] == (grade + 1)]
return ids
if __name__ == '__main__':
# 参数设置,ds_range选择模型,ds_pred指定预测日期
parser = argparse.ArgumentParser('MLP Model Train, feature generation and model train. \n'
'Usage: python MLPModel --ds_range --ds_pred ..')
parser.add_argument('--end_grade', type=int)
parser.add_argument('--ds_start', type=str)
parser.add_argument('--ds_num', type=int)
parser.add_argument('--ds_pred', help='data', type=str)
parser.add_argument('--ts_pred_start', help='data', type=str)
parser.add_argument('--method', help='\'mlp_41_baseline\' or \'mlp_41_incre\' or \'mlp_41_window\'')
args = parser.parse_args()
method = args.method
end_grade = args.end_grade
ds_start = args.ds_start
ds_num = args.ds_num
ds_pred = args.ds_pred
ts_pred_start = args.ts_pred_start.replace('#', ' ')
ts_pred_end = (datetime.strptime(ts_pred_start, TIME_FORMAT) + timedelta(minutes=MINUTE_DELTA)).strftime(TIME_FORMAT)
# logging
log.init_log(os.path.join(PROJECT_DIR, 'logs', 'mlp_predict'))
# logid
logid_path = os.path.join(PROJECT_DIR, 'logid', '41')
data_path = os.path.join(SAVE_DIR_BASE, 'data', ds_pred)
logging.info('Data source path: {}'.format(data_path))
# 获取待预测实时id
ts_start = ts_pred_start[:4] + '-' + ts_pred_start[4:6] + '-' + ts_pred_start[6:]
ts_end = ts_pred_end[:4] + '-' + ts_pred_end[4:6] + '-' + ts_pred_end[6:]
ids_to_pred = fetch_id(grade=end_grade, ts_start=ts_start, ts_end=ts_end)
logging.info('Num of ids to predict: {}'.format(len(ids_to_pred)))
with open(os.path.join(SAVE_DIR_BASE, 'trigger', ts_pred_start.replace(' ', '_').replace('-', '').replace(':', '')), 'w') as f:
json.dump(ids_to_pred, f, indent=4, sort_keys=True)
# 获取行为序列
cmd = '/usr/bin/python3 {PROJECT_DIR}/dataloader.py --end_grade {end_grade} ' \
'--ds_start {ds_start} --ds_num {ds_num} --ts_pred_start {ts_pred_start}'.format(
PROJECT_DIR=PROJECT_DIR,
end_grade=end_grade,
ds_start=ts_pred_start.split()[0].replace('-', ''),
ds_num=1,
ts_pred_start=ts_pred_start.replace(' ', '_').replace('-', '').replace(':', '')
)
logging.info(cmd)
os.system(cmd)
# 读取数据,提取特征
logging.info('label_tags: {}'.format(ts_pred_start.split(' ')[-1].replace(':', '')))
data = EvfreqLoader_hbase_pred(source_path_list=[data_path], logid_path=logid_path, sampling_type='up', test_size=0.0, label_tags=[ts_pred_start.split(' ')[-1].replace(':', '')])
data.run_load()
# 加载模型,预测
ds_start_num = '{}_{}'.format(ds_start, ds_num)
model_name = sorted(os.listdir(os.path.join(SAVE_DIR_BASE, 'model', ds_start_num)))[-1]
model_path = os.path.join(SAVE_DIR_BASE, 'model', ds_start_num, model_name)
logging.info('Loading model: {}'.format(model_path))
model = MLPModel(train_data=data.total_data, test_data=data.total_data, feature_type='freq', ids=data.ids)
results = model.run_predict(model_path=model_path, ts_pred_start=ts_pred_start)
logging.info('Done predicting ids on date: {}'.format(ds_pred))
# 预测结果上传MySQL
ids, scores = zip(*results)
db = MysqlDB(host=MySQL_HOST_IP, port=MySQL_HOST_PORT, user=MySQL_HOST_USER, passwd=MySQL_HOST_PASSWORD, db=MySQL_TARGET_DB)
db.upload_ids(sql_base=INSERT_SQL, ids=ids, scores=scores, method=method , ts_start=ts_start, ts_end=ts_end)
del data, model
gc.collect()