《java并发编程实战》 第十二章 并发程序的测试
《java并发编程实战笔记》
- 第十二章 并发程序的测试
- 正确性测试
- 基本单元测试(基于信号量有界缓存BoundedBuffer例子)
- 对阻塞行为与对中断响应的测试
- 安全性测试(测试BoundedBuffer生产者---消费者)
- 资源管理测试(测试资源泄露)
- 使用回调
- 使用Thread.yield产生更多的交替操作
- 性能测试
- 使用CyclicBarrier测量并发执行时间与吞吐率
- 不同缓存队列性能测试比较
- 响应性衡量
- 避免性能测试的陷阱
- 垃圾回收
- 动态编译
- 对代码路径的不真实采样
- 访问共享数据竞争程度影响吞吐量
- 无用代码的消除
- 总结
第十二章 并发程序的测试
测试并发程序而言,所面临的主要挑战在于:潜在的错误发生具有不确定性,需要比普通的串行程序测试更广的范围并且执行更长的时间。
并发测试大致分为两类:安全性测试和活跃性测试。
安全测试 ----- 通常采用测试不变性条件的形式,即判断某个类的行为是否与其他规范保持一致。
活跃性测试 ----- 包括进展测试和无进展测试两个方面(很难量化)。
性能测试----- 性能测试与活跃性测试相关,主要通过:吞吐量、响应性、可伸缩性衡量。
正确性测试
测试并发类设计单元测试时,首先要执行与测试串行类时相同的分析----找出需要检查的不变性条件与后验条件。(不变性条件:判断状态是有效还是无效,后验条件:判断状态改变后是否有效)。接下来讲通过构建一个基于Semaphore来实现的缓存的有界缓存,测试缓存的正确性。
基本单元测试(基于信号量有界缓存BoundedBuffer例子)
知识铺垫(Semaphore可以控制同时访问资源的线程个数,例如,实现一个文件允许的并发访问数。单个信号量的Semaphore对象可以实现互斥锁的功能,并且可以是由一个线程获得了“锁”,再由另一个线程释放“锁”)
BoundedBuffer 用一个泛型数组、Semaphore 实现了一个固定长度的、可以缓存队列可删除可插入个数的队列。availableItems表示可以从缓存中删除的元素个数。availableSpaces表示可以插入到缓存的元素个数,初始值等于缓存的大小。分析:
availableItems 设置为0,要求任何线程在accquire之前要release保证了队列必须插入有值才能take
availableSpaces 初始值为大小为capacity,表明队列最大值为capacity,同时也表明一开始最多有capacity个线程可以同时put队列,当然随着队列插入可同时插入的线程变少。
在最关键的插入、取出队列的操作中,采用synchronized 包装两个方法,保证了同步性。
说明:在实际使用中,肯定不可能自己编写一个有界缓存,但是此例实现的思路值得学习。如果实际需要使用有界缓存,应该直接使用ArrayBlockingQueue或者LinkedBlockingQueue。
public class BoundedBuffer<E> {
//可用信号量、空间信号量
private final Semaphore availableItems, availableSpaces;
private final E[] items;//缓存
private int putPosition = 0, takePosition = 0;//放、取索引位置
public BoundedBuffer(int capacity) {
availableItems = new Semaphore(0);//初始时没有可用的元素
availableSpaces = new Semaphore(capacity);//初始时空间信号量为最大容量
items = (E[]) new Object[capacity];
}
public boolean isEmpty() {
//如果可用信号量为0,则表示缓存为空
return availableItems.availablePermits() == 0;
}
public boolean isFull() {
//如果空间信号量为0,表示缓存已满
return availableSpaces.availablePermits() == 0;
}
public void put(E x) throws InterruptedException {
availableSpaces.acquire();//阻塞获取空间信号量
doInsert(x);
availableItems.release();//可用信号量加1
}
public E take() throws InterruptedException {
availableItems.acquire();
E item = doExtract();
availableSpaces.release();
return item;
}
private synchronized void doInsert(E x) {
int i = putPosition;
items[i] = x;
putPosition = (++i == items.length) ? 0 : i;
}
private synchronized E doExtract() {
int i = takePosition;
E x = items[i];
items[i] = null;//加快垃圾回收
takePosition = (++i == items.length) ? 0 : i;
return x;
}
}
先进行基本的单元测试:该基本的单元测试相当于串行上下文中执行的测试,测试了BoundedBuffer的所有方法,间接验证其后验条件和不变性条件。
public class BoundedBufferTest extends TestCase {
//刚构造好的缓存是否为空测试
public void testIsEmptyWhenConstructed() {
BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
assertTrue(bb.isEmpty());
assertFalse(bb.isFull());
}
//测试是否满
public void testIsFullAfterPuts() throws InterruptedException {
BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
for (int i = 0; i < 10; i++)
bb.put(i);
assertTrue(bb.isFull());
assertFalse(bb.isEmpty());
}
对阻塞行为与对中断响应的测试
在测试并发的基本属性时,需要引入多个线程。大多数测试框架并不能很好的支持并发性测试,测试阻塞行为,当然线程被阻塞不再执行时,阻塞才是成功的,为了让阻塞行为效果更明显,可以在阻塞方法中抛出异常。
当阻塞发生后,要使方法解除阻塞最简单的方式是采用中断,可以在阻塞方法发生后,线程阻塞后再中断它,当然这要求阻塞方法提取返回或者抛出InterrupedException来响应中断。
例如BoundedBuffer的阻塞行为以及对中断的响应性测试,如果从空缓存中获取一个元素,如果take方法成功,表明测试失败。在等待“获取”一段时间后,再中断该线程,如果线程在调用Object类的wait()、 join() 或者sleep()方法被强行中断,那么将会抛出InterruptedException。
public class TestBoundedBufferBlock extends TestCase {
public void testTakeBlocksWhenEmpty() {
final BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
Thread taker = new Thread() {
public void run() {
try {
int unused = bb.take();
System.out.println("由于阻塞,将不会输出此句");
fail(); // 如果运行到这里,就说明有错误,fail会抛出异常
} catch (InterruptedException success) {success.printStackTrace(); }
}};
try {
taker.start();
Thread.sleep(100);
// taker.interrupt();//中断阻塞线程
taker.join(1000);//等待阻塞线程完成
assertFalse(taker.isAlive());//断言阻塞线程已终止
} catch (Exception unexpected) {
fail();
}
}
public static void main(String[] args) {
TestBoundedBufferBlock boundedBufferTest = new TestBoundedBufferBlock();
boundedBufferTest.testTakeBlocksWhenEmpty();
}
}
可进行interrupt强行中断,将抛出异常InterrupedException。

以下结果是,执行线程执行join()方法,设置等待该线程最长时间为1秒,最后断言线程已中止。

安全性测试(测试BoundedBuffer生产者—消费者)
安全性测试即测试是否会发生数据竞争从而引发错误,测试类似BoundedBuffer生产者—消费者模式的类,需要创建多个线程来分别执行put和take操作。
为了尽可能达到多个线程并行执行,避免线程交替执行达不到预期的结果,可采用CountDownLatch或者CyclicBarrier。若采用两个CountDownLatch,其中一个作为开启阀门,另一个作为结束阀门。若采用CyclicBarrier相对简单。(CyclicBarrier初始化时规定一个数目,然后计算调用了CyclicBarrier.await()进入等待的线程数。当线程数达到了这个数目时,所有进入等待状态的线程被唤醒并继续。 )
分析:
PutTakeTest开启了10对生产—消费者线程,初始化CyclicBarrier时将计数值指定为工作者总线程的数量再加1,并在运行开始和结束时,使工作者线程和测试线程都在这个栅栏处等待。这能确保所有线程在开始执行任何工作之前,都首先执行到同一位置。
通过一个对顺序敏感的校验和计算函数来计算所有入列元素以及出列元素的校验和,并进行比较。如果两者相等,程序最终没有报错,则测试就是成功的。事实上也确实没有报错。
public class PutTakeTest extends TestCase {
protected static final ExecutorService pool = Executors
.newCachedThreadPool();
protected CyclicBarrier barrier;//为了尽量做到真正并发,使用屏障
protected final BoundedBuffer<Integer> bb;
protected final int nTrials, nPairs;//元素个数、生产与消费线程数
protected final AtomicInteger putSum = new AtomicInteger(0);//放入元素检验和
protected final AtomicInteger takeSum = new AtomicInteger(0);//取出元素检验和
public static void main(String[] args) throws Exception {
new PutTakeTest(10, 10, 100000).test(); // sample parameters
pool.shutdown();
}
public PutTakeTest(int capacity, int npairs, int ntrials) {
this.bb = new BoundedBuffer<Integer>(capacity);
this.nTrials = ntrials;
this.nPairs = npairs;
this.barrier = new CyclicBarrier(npairs * 2 + 1);
}
void test() {
try {
for (int i = 0; i < nPairs; i++) {
pool.execute(new Producer());//提交生产任务
pool.execute(new Consumer());//提交消费任务
}
barrier.await(); // 等待所有线程都准备好
barrier.await(); // 等待所有线程完成,即所有线程都执行到这里时才能往下执行
assertEquals(putSum.get(), takeSum.get());//如果不等,则会抛异常
} catch (Exception e) {
throw new RuntimeException(e);
}
}
class Producer implements Runnable {
public void run() {
try {
//等待所有生产-消费线程、还有主线程都准备好后才可以往后执行
barrier.await();
// 种子,即起始值
int seed = (this.hashCode() ^ (int) System.nanoTime());
int sum = 0;//线程内部检验和
for (int i = nTrials; i > 0; --i) {
bb.put(seed);//入队
/*
* 累计放入检验和,为了不影响原程序,这里不要直接使用全局的
* putSum来累计,而是等每个线程试验完后再将内部统计的结果一
* 次性存入
*/
sum += seed;
seed = xorShift(seed);//根据种子随机产生下一个将要放入的元素
}
//试验完成后将每个线程的内部检验和再次累计到全局检验和
putSum.getAndAdd(sum);
//等待所有生产-消费线程、还有主线程都完成后才可以往后执行
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
class Consumer implements Runnable {
public void run() {
try {
//等待所有生产-消费线程、还有主线程都准备好后才可以往后执行
barrier.await();
int sum = 0;
for (int i = nTrials; i > 0; --i) {
sum += bb.take();
}
takeSum.getAndAdd(sum);
//等待所有生产-消费线程、还有主线程都完成后才可以往后执行
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
/*
* 测试时尽量不是使用类库中的随机函数,大多数的随机数生成器都是线程安全的,
* 使用它们可能会影响原本的性能测试。在这里我们也不必要使用高先是的随机性。
* 所以使用简单而快的随机算法在这里是必要的。
*/
static int xorShift(int y) {
y ^= (y << 6);
y ^= (y >>> 21);
y ^= (y << 7);
return y;
}
}
资源管理测试(测试资源泄露)
书中原文,通过一些测量应用程序中内存使用情况的堆检查工具,可以很容易地测试出对内存的不合理占用,许多商用和开源的堆分析工具中都支持这种功能。下面程序的testLeak方法中包含了一些堆分析工具用于抓取堆的快照,这将强制执行一次垃圾回收,然后记录堆大小和内存使用量信息。
testLeak方法将多个大型对象插入到一个有界缓存中,然后将它们移除。第2个堆快照中的内存用量应该与第1个堆快照中的内存用量基本相同。然而,doExtract如果忘记将返回元素的引用置为空(items[i] = null),那么在两次快照中报告的内存用量将明显不同。(这是为数不多几种需要显式地将变量置空的情况之一。大多数情况下,这种做法不仅不会带来帮助,甚至还会带来负面作用。)
功力不足,并不能看出垃圾回收中堆是如何变化的。待补充
//大对象
class Big { double[] data = new double[100000]; }
void testLeak() throws InterruptedException {
BoundedBuffer<Big> bb = new BoundedBuffer<Big>(CAPACITY);
//使用前堆大小快照,这里可以调用第三方堆追踪(heap-profiling)工具来记录。堆追踪工具会强制进行垃圾回收,然后记录下堆大小和内存用量信息
int heapSize1 = /* snapshot heap */ ;
for (int i = 0; i < CAPACITY; i++)
bb.put(new Big());
for (int i = 0; i < CAPACITY; i++)
bb.take();
int heapSize2 = /* snapshot heap */ ;
assertTrue(Math.abs(heapSize1-heapSize2) < THRESHOLD);
}
使用回调
书中原文,在构造测试案例时,对客户提供的代码进行回调是非常有帮助的。回调函数的执行通常是在对象生命周期的一些已知位置上,并且在这些位置上非常适合判断不变性条件是否被破坏。例如,在ThreadPoolExecutor中将调用任务的Runnable和ThreadFactory。
通过使用自定义的线程工厂,可以对线程的创建过程进行控制。下面程序TestingThreadFactory中将记录已创建线程的数量。这样,在测试过程中,测试方案可以验证已创建线程的数量。我们还可以对TestingThreadFactory进行扩展,使其返回一个自定义的Thread,并且该对象可以记录自己在何时结束,从而在测试方案中验证线程在被回收时是否与执行策略一致。
class TestingThreadFactory implements ThreadFactory {
public final AtomicInteger numCreated = new AtomicInteger();//记录已创建的工作线程数
private final ThreadFactory factory
= Executors.defaultThreadFactory();
public Thread newThread(Runnable r) {//Executor框架在创建工作线程时回调此方法
numCreated.incrementAndGet();
return factory.newThread(r);
}
}
如果线程池的基本大小小于最大大小,那么线程池会根据执行需求相应增长。当把一些运行时间较长的任务提交给线程池时,线程池中的任务数量在长时间内都不会变化,这就可以进行一些判断,例如测试线程池是否能按照预期的方式扩展,如下程序:
public class TestThreadPool extends TestCase {
private final TestingThreadFactory threadFactory = new TestingThreadFactory();
public void testPoolExpansion() throws InterruptedException {
int MAX_SIZE = 10;
ExecutorService exec = Executors.newFixedThreadPool(MAX_SIZE);
for (int i = 0; i < 10 * MAX_SIZE; i++)
exec.execute(new Runnable() {
public void run() {
try {
Thread.sleep(Long.MAX_VALUE);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
for (int i = 0;
i < 20 && threadFactory.numCreated.get() < MAX_SIZE;
i++)
Thread.sleep(100);
assertEquals(threadFactory.numCreated.get(), MAX_SIZE);
exec.shutdownNow();
}
}
使用Thread.yield产生更多的交替操作
由于并发代码中的大多数错误都是一些低概率事件,因此在测试并发错误时需要反复地执行许多次,但有些方法可以提高发现这些错误的概率。有一种有用的方法可以提高交替操作的数量,以便能有效地搜索程序的状态空间:在访问共享状态的操作中,使用Thread.yield将产生更多的上下文切换。(这项技术的有效性与具体的平台相关,因为JVM可以将Thread.yield作用一个空操作。如果使用一个睡眠时间较短的sleep,那么虽然慢些,但却更可靠。)
下面程序中的方法在两个账户之间执行转账操作,在两次更新操作之间,像”所有账户的总和应等于零“这样的一些不变性条件可能会被破坏。当代码在访问状态时没有使用足够的同步,将存在一些对执行时序敏感的错误,通过在某个操作的执行过程中调用yield方法,可以将这些错误暴露出来。这种方法需要在测试中添加一些调用并且在正式产品中删除这些调用,这将给开发人员带来不便,通过使用面向方面编程(AOP)的工具,可以降低这种不便性。
使用Thread.yield,让线程从Thread.yield调用点切换到另一线程,有助于发现Bug,该方法只适合用于测试环境中。下面使用该方法在取出与存入间切换到另一线程:
public synchronized void transferCredits(Account from,
Account to,
int amount) {
from.setBalance(from.getBalance() - amount);
if (random.nextInt(1000) > THRESHOLD)
Thread.yield();//切换到另一线程
to.setBalance(to.getBalance() + amount);
}
性能测试
使用CyclicBarrier测量并发执行时间与吞吐率
以上面的PutTakeTest,给它加上时间测量特性。测试性能时的时间最好取多个线程的平均消耗时间,这样会精确一些。在PutTakeTest中我们已经使用了CyclicBarrier去同时启动和结束工作者线程了,所以我们只要使用一个关卡动作(在所有线程都达关卡点后开始执行的动作)来记录启动和结束时间,就完成了对并发执行时间的测试。下面是扩展后的PutTakeTest,:
public class TimedPutTakeTest extends PutTakeTest {
private BarrierTimer timer = new BarrierTimer();
public TimedPutTakeTest(int cap, int pairs, int trials) {
super(cap, pairs, trials);
barrier = new CyclicBarrier(nPairs * 2 + 1, timer);
}
public void test() {
try {
timer.clear();
for (int i = 0; i < nPairs; i++) {
pool.execute(new PutTakeTest.Producer());
pool.execute(new PutTakeTest.Consumer());
}
barrier.await();//等待所有线程都准备好后开始往下执行
barrier.await();//等待所有线都执行完后开始往下执行
//每个元素完成处理所需要的时间
long nsPerItem = timer.getTime() / (nPairs * (long) nTrials);
System.out.print("Throughput: " + nsPerItem + " ns/item");
assertEquals(putSum.get(), takeSum.get());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws Exception {
int tpt = 100000; // 每对线程(生产-消费)需处理的元素个数
//测试缓存容量分别为1、10、100、1000的情况
for (int cap = 1; cap <= 1000; cap *= 10) {
System.out.println("Capacity: " + cap);
//测试工作线程数1、2、4、8、16、32、64、128的情况
for (int pairs = 1; pairs <= 128; pairs *= 2) {
TimedPutTakeTest t = new TimedPutTakeTest(cap, pairs, tpt);
System.out.print("Pairs: " + pairs + "\t");
//测试两次
t.test();//第一次
System.out.print("\t");
Thread.sleep(1000);
t.test();//第二次
System.out.println();
Thread.sleep(1000);
}
}
PutTakeTest.pool.shutdown();
}
//关卡动作,在最后一个线程达到后执行。在该测试中会执行两次:
//一次是执行任务前,二是所有任务都执行完后
static class BarrierTimer implements Runnable {
private boolean started;//是否是第一次执行关卡活动
private long startTime, endTime;
public synchronized void run() {
long t = System.nanoTime();
if (!started) {//第一次关卡活动走该分支
started = true;
startTime = t;
} else
//第二次关卡活动走该分支
endTime = t;
}
public synchronized void clear() {
started = false;
}
public synchronized long getTime() {//任务所耗时间
return endTime - startTime;
}
}
}
运行结果:
Capacity: 1
Pairs: 1 Throughput: 9440 ns/item Throughput: 9308 ns/item
Pairs: 2 Throughput: 12159 ns/item Throughput: 12111 ns/item
Pairs: 4 Throughput: 12198 ns/item Throughput: 12234 ns/item
Pairs: 8 Throughput: 13001 ns/item Throughput: 13432 ns/item
Pairs: 16 Throughput: 12672 ns/item Throughput: 12930 ns/item
Pairs: 32 Throughput: 12409 ns/item Throughput: 14012 ns/item
Pairs: 64 Throughput: 12551 ns/item Throughput: 12619 ns/item
Pairs: 128 Throughput: 11897 ns/item Throughput: 11806 ns/item
Capacity: 10
Pairs: 1 Throughput: 1444 ns/item Throughput: 1231 ns/item
Pairs: 2 Throughput: 1190 ns/item Throughput: 1186 ns/item
Pairs: 4 Throughput: 1283 ns/item Throughput: 1283 ns/item
Pairs: 8 Throughput: 1251 ns/item Throughput: 1263 ns/item
Pairs: 16 Throughput: 1227 ns/item Throughput: 1236 ns/item
Pairs: 32 Throughput: 1216 ns/item Throughput: 1221 ns/item
Pairs: 64 Throughput: 1208 ns/item Throughput: 1282 ns/item
Pairs: 128 Throughput: 1265 ns/item Throughput: 1227 ns/item
Capacity: 100
Pairs: 1 Throughput: 519 ns/item Throughput: 473 ns/item
Pairs: 2 Throughput: 374 ns/item Throughput: 370 ns/item
Pairs: 4 Throughput: 302 ns/item Throughput: 289 ns/item
Pairs: 8 Throughput: 286 ns/item Throughput: 286 ns/item
Pairs: 16 Throughput: 306 ns/item Throughput: 311 ns/item
Pairs: 32 Throughput: 310 ns/item Throughput: 316 ns/item
Pairs: 64 Throughput: 322 ns/item Throughput: 321 ns/item
Pairs: 128 Throughput: 324 ns/item Throughput: 323 ns/item
Capacity: 1000
Pairs: 1 Throughput: 393 ns/item Throughput: 484 ns/item
Pairs: 2 Throughput: 267 ns/item Throughput: 315 ns/item
Pairs: 4 Throughput: 192 ns/item Throughput: 278 ns/item
Pairs: 8 Throughput: 277 ns/item Throughput: 212 ns/item
Pairs: 16 Throughput: 218 ns/item Throughput: 226 ns/item
Pairs: 32 Throughput: 214 ns/item Throughput: 242 ns/item
Pairs: 64 Throughput: 245 ns/item Throughput: 251 ns/item
Pairs: 128 Throughput: 261 ns/item Throughput: 260 ns/item
分析:缓存size为1时,即cap为1时,BoundedBuffer的Capacity为1时,BoundedBuffer中的Semaphore限定了每次只能1个线程访问队列,每个线程在阻塞等待前一个使用有界缓存队列的线程,当缓存提高至10,吞吐量得到了极大的提高,从上面的运行结果也可看出,并发执行时间极大的缩小。但是线程增加时,吞吐率却有所下降,运行时间不见得有很大的降低,原因在于虽然有许多线程,但却没有足够多的计算量,大多数的时间都消耗在线程的阻塞与解除阻塞操作上。图中,吞吐率已归一化,size为缓存大小。
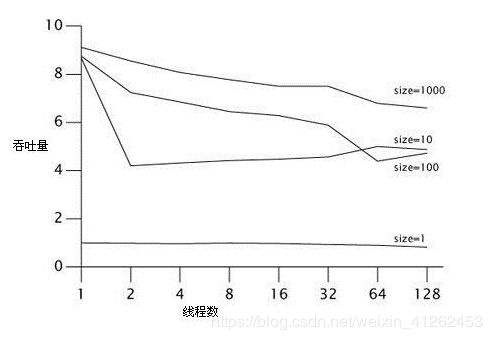
不同缓存队列性能测试比较
虽然上面的BoundedBuffer是一种相当可靠的实现,它的运行机制也非常合理,但是它还不足以和ArrayBlockingQueue 与LinkedBlockingQueue相提并论,这也解释了为什么这种缓存算法没有被选入类库中。并发类库中的算法已经被选择并调整到最佳性能状态了。BoundedBuffer性能不高的主要原因:put和take操作分别都有多个操作可能遇到竞争——获取一个信号量,获取一个锁、释放信号量。
在测试的过程中发现LinkedBlockingQueue的伸缩性好于ArrayBlockingQueue,这主要是因为链表队列的put和take操作允许有比基于数组的队列更好的并发访问,好的链表队列算法允许队列的头和尾彼此独立地更新。由于内存分配操作通常是线程本地的,因此如果算法能通过执行一些内存分配操作来降低竞争程度,那么这种算法通常具有更高的可伸缩性。这种情况再次证明了,基于传统的性能调优直觉与提升可伸缩性的实际需求是背道而驰的。

Throughput表示吞吐率
响应性衡量
响应性通过任务完成的时间来衡量。除非线程由于密集的同步需求而被持续的阻塞,否则非公平的信号量通常能实现更好的吞吐量,而公平的信号量则实现更低的变动性(公平性开销主要由于线程阻塞所引起)。下图为TimePutTakeTest中使用1000个缓存,256个并发任务中每个任务完成时间,其中每个任务都是用非公平信号量(隐蔽栅栏,Shaded Bars)和公平的信号量(开放栅栏,open bars)来迭代1000个元素,其中非公平信号量完成时间从104毫秒到8714毫米,相差80倍。若采用同步控制实现更高的公平性,能缩小任务完成时间变动范围(变动性),但是会极大的降低吞吐率。

避免性能测试的陷阱
以下的几种编码陷阱是性能测试变得毫无意义。
垃圾回收
垃圾回收的执行时序是无法预测的,可能发生在任何时刻,如果在测试程序时,恰巧触发的垃圾回收操作,那么在最终测试的时间上会带来很大但虚假的影响。
两种策略方式垃圾回收操作对测试结果产生偏差:
一:保证垃圾回收在执行测试程序期间不被执行,可通过调用JVM时指定-verbose:gc查看是否有垃圾回收信息。
二:保证垃圾回收在执行测试程序期间执行多次,可以充分反映出运行期间的内存分配和垃圾回收等开销。
通常而言,第二种更好,更能反映实际环境下的性能。
动态编译
相比静态的编译语言(C或者C++),java动态编译语言的性能基准测试变得困难的多。在JVM中将字节码的解释和动态编译结合起来。当某个类第一次被加载,JVM会通过解释字节码方式执行它,然而某个时刻,如果某个方法运行测试足够多,那么动态编译器会将其编译为机器代码,某个方法的执行方法从解释执行变成直接执行。这种编译的执行实际无法预测,如果编译器可以在测试期间运行,那么将在两个方面给测试结果带来偏差:
一:编译过程消耗CPU资源
二:测量的代码中既包含解释执行代码,又包含编译执行代码,测试结果是混合代码的性能指标没有太大的意义。
解决办法:
一:可以让测试程序运行足够长时间,防止动态编译对测试结果产生的偏差。
二:在HotSpot运行程序时设置-xx:+PrintCompilation,在动态编译时输出一条信息,可以通过这条消息验证动态编译是测试运行前,而不是运行过程中执行
对代码路径的不真实采样
动态编译可能会让不同地方调用的同一方法编译出的代码不同。
测试程序不仅要大致判断某个典型应用程序的使用模式,还要尽量覆盖在该应用程序中将执行的代码路径集合
访问共享数据竞争程度影响吞吐量
并发程序交替执行两种类型的工作:访问共享数据(例如从共享工作队列取出下一个任务)和执行线程本地的计算(例如:执行任务)。如果任务是计算密集型,即任务执行时间较长,那么这种情况下几乎不存在竞争,吞吐量受限于CPU资源可用性。然而,如果任务生命周期较慢,那么在工作队列上存在严重的竞争,吞吐量受限于同步的开销。例如TimePutTakeTest由于消费者没有执行太多工作,吞吐量受限于线程的协调开销。
无用代码的消除
无论是何种语言编写优秀的基准测试程序,一个需要面对的挑战是:优化编译能找出并消除那些对输出结果不会产生任何影响的无用代码。由于基准测试代码通常不会执行任何技术,因此很容易在编译器的优化过程中被消除,因此测试的内容变得更少。在动态编译语言java中,要检测编译器是否消除了测试基准是很困难的。
解决办法,要告诉优化器不要将基准测试代码当成无用代码而优化掉,这就要求在程序中对每个计算结果都通过某种方法使用,这种方法不需要大量的计算。例如在PutTakeTest中,我们计算了在队列中添加删除了所有元素的校验和,如果在程序中没有用到这个校验和,那么计算校验和操作很有可能被优化掉,但是幸好 assertEquals(putSum.get(), takeSum.get());在程序中使用了校验和来验证算法的正确性。
上诉中要尽量采用某种方法使用计算结果避免被优化掉,有个简单的方法可不会引入过高的开销,将计算结果与System.nanoTime比较,若相等输出一个无用的消息即可。
if(计算结果== System.nanoTime())
System.out.print(" ");
总结
要测试并发程序的正确性可能非常困难,因为并发程序的许多故障模式都是一些低概率事件,它们对于执行时序、负载情况以及其他难以重现的条件都非常敏感。而且,在测试程序中还会引入额外的同步或执行时序限制,这些因素将掩盖被测试代码中的一些并发问题。要测试并发程序的性能同样非常困难,与使用静态编译语言(例如C)编写的程序相比,用Java编写的程序在测试起来更加困难,因为动态编译、垃圾回收以及自动化等操作都会影响与时间相关的测试结果。
要想尽可能地发现潜在的错误以及避免它们在正式产品中暴露出来,我们需要将传统的测试技术(要谨慎地避免在这里讨论的各种陷阱)与代码审查和自动化分析工具结合起来,每项技术都可以找出其他技术忽略的问题。