为了减少神经网络的计算消耗,论文提出Ghost模块来构建高效的网络结果。该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过简单的线性变化操作来进一步高效地生成ghost特征图。从实验来看,对比其它模型,GhostNet的压缩效果最好,且准确率保持也很不错,论文思想十分值得参考与学习
来源:晓飞的算法工程笔记 公众号
论文: GhostNet: More Features from Cheap Operations

- 论文地址:https://arxiv.org/abs/1911.11907
Introduction
目前,神经网络的研究趋向于移动设备上的应用,一些研究着重于模型的压缩方法,比如剪枝,量化,知识蒸馏等,另外一些则着重于高效的网络设计,比如MobileNet,ShuffleNet等
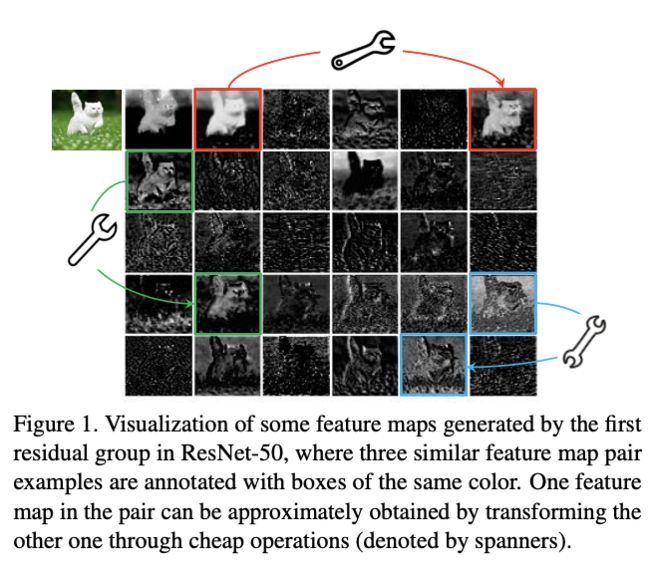
训练好的网络一般都有丰富甚至冗余的特征图信息来保证对输入的理解,如图1 ResNet-50的特征图,相似的特征图类似于对方的ghost。冗余的特征是网络的关键特性,论文认为与其避免冗余特征,不如以一种cost-efficient的方式接受,获得很不错的性能提升,论文主要有两个贡献:
- 提出能用更少参数提取更多特征的Ghost模块,首先使用输出很少的原始卷积操作(非卷积层操作)进行输出,再对输出使用一系列简单的线性操作来生成更多的特征。这样,不用改变其输出的特征图,Ghost模块的整体的参数量和计算量就已经降低了
- 基于Ghost模块提出GhostNet,将原始的卷积层替换为Ghost模块
Approach
Ghost Module for More Features
![]()
对于输入数据$X\in \mathbb{R}^{c\times h\times w}$,卷积层操作如公式1,$Y\in \mathbb{R}{h{'}\times w^{'}\times n}$为输出的n维特征图,$f\in \mathbb{R}^{c\times k\times k\times n}$为该层的卷积核,可得该层的计算量为$n\cdot h^{'}\cdot w^{'}\cdot c\cdot k\cdot k$,这个数值通常成千上万,因为$n$和$c$一般都很大。公式1的参数量与输入和输出的特征图数息息相关,而从图1可以看出中间特征图存在大量冗余,且存在相似的特征(Ghost),所以完全没必要占用大量计算量来计算这些Ghost
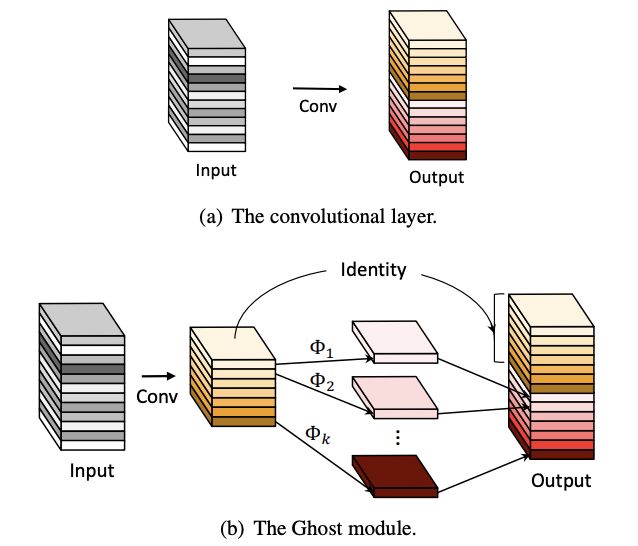
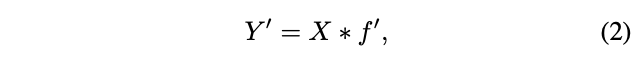
假设原输出的特征为某些内在特征进行简单的变换得到Ghost,通常这些内在特征数量都很少,并且能通过原始卷积操作公式2获得,$Y^{'}\in \mathbb{R}{h{'}\times w^{'}\times m}$为原始卷积输出,$f^{'}\in \mathbb{R}^{c\times k\times k\times m}$为使用的卷积核,$m\le n$,bias直接简化了
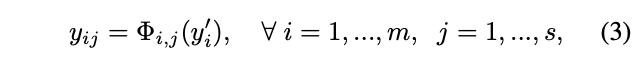
为了获得原来的$n$维特征,对$Y{'}$的内在特征分别使用一系列简单线性操作来产生$s$维ghost特征,$\Phi_{i,j}$为生成$y_i{'}$的$j$-th ghost特征图的线性变换函数,最后的$\Phi_{i,s}$为保存内在特征的identity mapping,整体计算如图2b
-
Difference from Existing Methods
与目前主流的卷积操作对比,Ghost模块有以下不同点:
- 对比Mobilenet、Squeezenet和Shufflenet中大量使用$1\times 1$ pointwise卷积,Ghost模块的原始卷积可以自定义卷积核数量
- 目前大多数方法都是先做pointwise卷积降维,再用depthwise卷积进行特征提取,而Ghost则是先做原始卷积,再用简单的线性变换来获取更多特征
- 目前的方法中处理每个特征图大都使用depthwise卷积或shift操作,而Ghost模块使用线性变换,可以有很大的多样性
- Ghost模块同时使用identity mapping来保持原有特征
-
Analysis on Complexities
假设Ghost模块包含1个identity mapping和$m\cdot (s-1)=\frac{n}{s} \cdot (s-1)$个线性操作,每个线性操作的核大小为$d\times d$

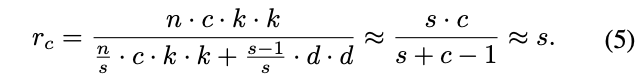
理论的加速比如公式4,而理论的压缩比如公式5,让$d\times d$与$k\times k$相似且$s\ll c$
Building Efficient CNNs
-
Ghost Bottlenecks

Ghost Bottleneck(G-bneck)与residual block类似,主要由两个Ghost模块堆叠二次,第一个模块用于增加特征维度,增大的比例称为expansion ration,而第二个模块则用于减少特征维度,使其与shortcut一致。G-bneck包含stride=1和stride=2版本,对于stride=2,shortcut路径使用下采样层,并在Ghost模块中间插入stride=2的depthwise卷积。为了加速,Ghost模块的原始卷积均采用pointwise卷积
-
GhostNet
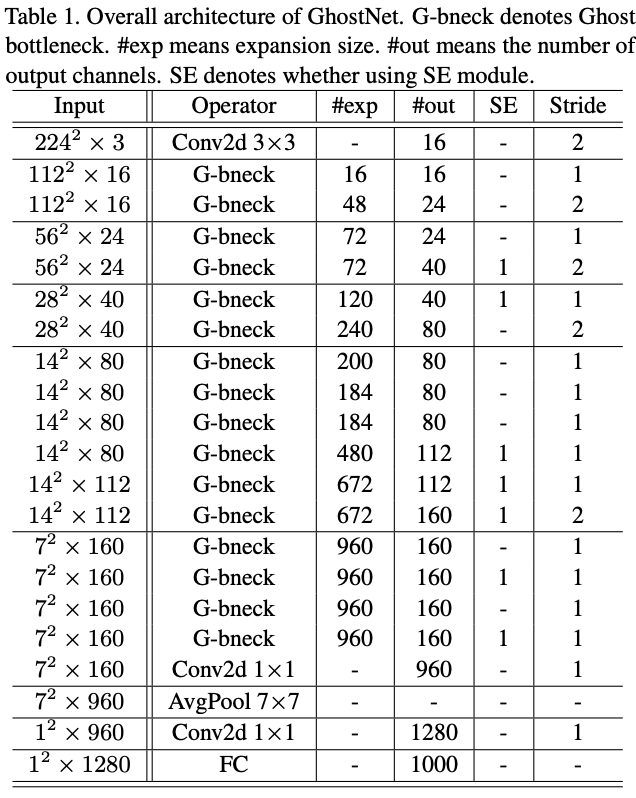
基于Ghost bottleneck,GhostNet的结构如图7所示,将MobileNetV3的bottleneck block替换成Ghost bottleneck,部分Ghost模块加入了SE模块
-
Width Multiplier
尽管表7的结构已经很高效,但有些场景需要对模型进行调整,可以简单地使用$\alpha$对每层的维度进行扩缩,$\alpha$称为width multiplier,模型大小与计算量大约为$\alpha^2$倍
Experiments
Efficiency of Ghost Module
-
Toy Experiments
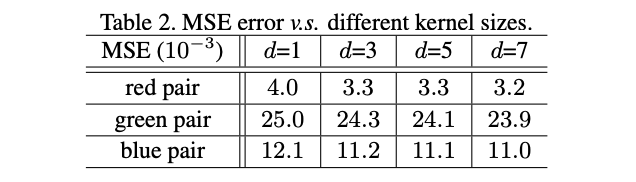
论文对图1的ghost pair进行了不同核大小的线性变化测试,将左图作为输出右图作为输入训练depthwise卷积,然后使用训练的结果对左图进行变换,计算其变换后与右图的MSE。可以看到,不同的核大小下差值都很小,说明线性变换是有效的,而且核大小的影响不大,所以用核固定为d的depthwise卷积来进行公式3计算
-
CIFAR-10
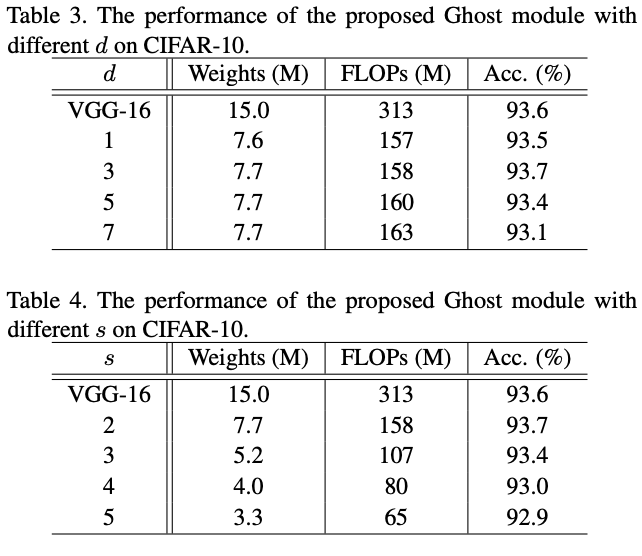
将VGG的卷积层替换成Ghost模块进行超参数测试,表3的$s=2$,表4的$d=3$
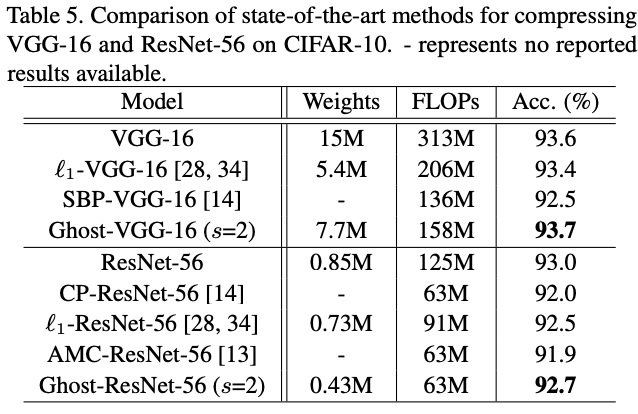
可以看到使用Ghost模块不仅比其它压缩方法更能降低模型的体量,也最能保持模型准确率

对Ghost模块产生的特征进行了可视化,尽管从内在特征线性变换而来,但还是有明显的差异,说明线性变换足够灵活
-
Large Models on ImageNet
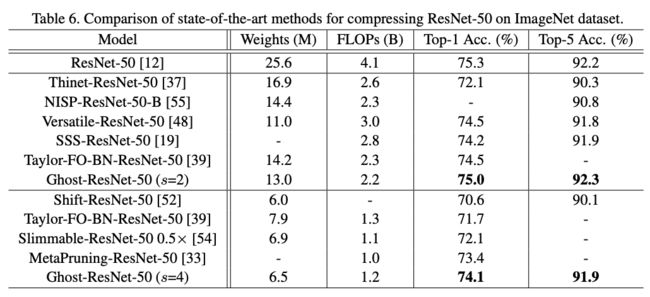
在大型网络上使用Ghost模块,压缩效果和准确率依然很不错
GhostNet on Visual Benchmarks
-
ImageNet Classification
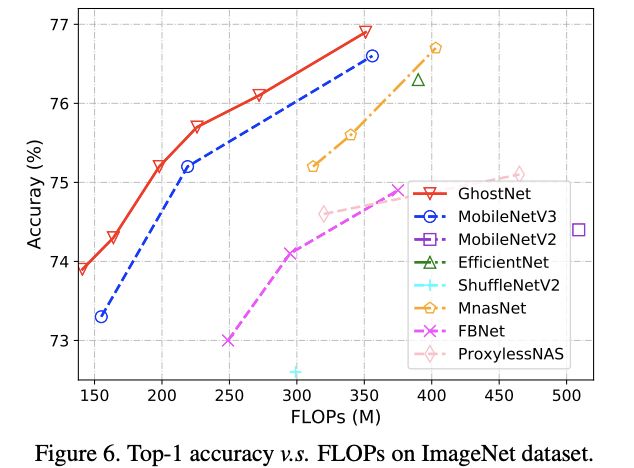
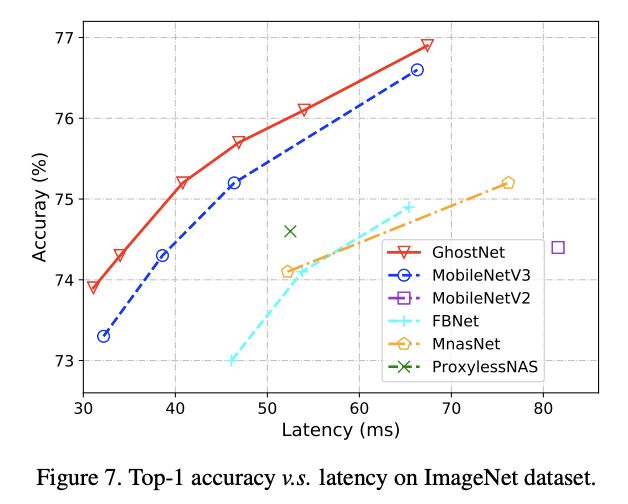

使用$k=1$, $s=2$, $d=3$的GhostNet,结果如表7,不同的模型大小使用不同的$\alpha$值进行调整,整体而言,GhostNet最轻量且准确率最高
-
Object Detection

在one-stage和two-stage检测算法上,GhostNet能降低大部分计算量,而mAP与其它主干网络差不多
CONCLUSION
为了减少神经网络的计算消耗,论文提出Ghost模块来构建高效的网络结果。该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过简单的线性变化操作来进一步高效地生成ghost特征图。从实验来看,对比其它模型,GhostNet的压缩效果最好,且准确率保持也很不错,论文思想十分值得参考与学习
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
