自然语言处理(NLP)词法分析--文本关键词提取
一、什么是关键词提取
关键词提取就是从文本里面把跟内容意义最相关的一些词语抽取出来。这个可以追溯到文献检索初期,关键词是为了文献标引工作,从报告、论文中选取出来用以表示全文主题内容信息的单词或术语,在现在的报告和论文中,我们依然可以看到关键词这一项。
关键词在文献检索、自动文摘、文本聚类/分类等方面有着重要的应用,它不仅是进行这些工作不可或缺的基础和前提,也是互联网上信息建库的一项重要工作。比如在聚类时将关键词相似的几篇文档看成一个团簇,可以大大提高聚类算法的收敛速度;从某天所有的新闻中提取出这些新闻的关键词,就可以大致了解那天发生了什么事情;或者将某段时间内几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论什么话题。
-
关键词抽取从方法来说主要有两种:
1、第一种是关键词分配:就是给定一个已有的关键词库,对于新来的文档从该词库里面匹配几个词语作为这篇文档的关键词。
2、第二种是关键词提取:针对新文档,通过算法分析,提取文档中一些词语作为该文档的关键词。
目前大多数应用领域的关键词抽取算法都是基于后者实现的,从逻辑上说,后者比前者在实际应用中更准确。
-
从算法的角度来看,关键词抽取算法主要有两类:
1、有监督学习算法,将关键词抽取过程视为二分类问题,先抽取出候选词,然后对于每个候选词划定标签,要么是关键词,要么不是关键词,然后训练关键词抽取分类器。当新来一篇文档时,抽取出所有的候选词,然后利用训练好的关键词抽取分类器,对各个候选词进行分类,最终将标签为关键词的候选词作为关键词;
2、无监督学习算法,先抽取出候选词,然后对各个候选词进行打分,然后输出topK个分值最高的候选词作为关键词。根据打分的策略不同,有不同的算法,例如TF-IDF,TextRank等算法;
jieba分词系统中实现了两种关键词抽取算法,分别是基于TF-IDF关键词抽取算法和基于TextRank关键词抽取算法,两类算法均是无监督学习的算法,下面将会通过实例讲解介绍如何使用jieba分词的关键词抽取接口以及通过源码讲解其实现的原理。
二、基于 TF-IDF 算法进行关键词提取
1、原理
在信息检索理论中,TF-IDF 是 Term Frequency - Inverse Document Frequency 的简写。TF-IDF 是一种数值统计,用于反映一个词对于语料中某篇文档的重要性。在信息检索和文本挖掘领域,它经常用于因子加权。TF-IDF 的主要思想就是:如果某个词在一篇文档中出现的频率高,也即 TF 高;并且在语料库中其他文档中很少出现,即 DF 低,也即 IDF 高,则认为这个词具有很好的类别区分能力。
TF 为词频(Term Frequency),表示词 t 在文档 d 中出现的频率,计算公式:

其中,|D| 表示语料库中的文件总数,|{j:ti∈dj}| 包含词 ti 的文件数目,如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用 1+|{j:ti∈dj}|。
TF-IDF 在实际中主要是将二者相乘,也即 TF * IDF, 计算公式:
![]()
因此,TF-IDF 倾向于过滤掉常见的词语,保留重要的词语。例如,某一特定文件内的高频率词语,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的 TF-IDF。
2、关键词提取工具–TF-IDF方法
jieba 已经实现了基于 TF-IDF 算法的关键词抽取,通过命令 import jieba.analyse引入,函数参数解释如下:
- sentence:待提取的文本语料;
- topK:返回 TF/IDF 权重最大的关键词个数,默认值为 20;
- withWeight:是否需要返回关键词权重值,默认值为 False;
- allowPOS:仅包括指定词性的词,默认值为空,即不筛选。
接下来看例子,采用的语料来自于百度百科对人工智能的定义,获取 Top20 关键字,用空格隔开打印:
import jieba.analyse
sentence = "人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。"
keywords = " ".join(jieba.analyse.extract_tags(sentence , topK=10, withWeight=False, allowPOS=()))
print(keywords)
'''
智能 人工智能 Artificial Intelligence AI 图像识别 自然语言 专家系统 计算机科学 技术
'''
#只获取 Top5 的关键字,并修改一下词性,只选择名词和动词
keywords =(jieba.analyse.extract_tags(sentence , topK=5, withWeight=True, allowPOS=(['n','v'])))
print(keywords)
'''
[('智能', 0.7740711667427027), ('人工智能', 0.5112446700264865), ('图像识别', 0.3231018244027027), ('计算机科学', 0.263717376367027), ('技术', 0.2551057934362162)]
'''
三、基于 TextRank 算法进行关键词提取
1、原理
TextRank 是由 PageRank 改进而来,核心思想将文本中的词看作图中的节点,通过边相互连接,不同的节点会有不同的权重,权重高的节点可以作为关键词。这里给出 TextRank 的公式:

节点 i 的权重取决于节点 i 的邻居节点中 i-j 这条边的权重 / j 的所有出度的边的权重 * 节点 j 的权重,将这些邻居节点计算的权重相加,再乘上一定的阻尼系数,就是节点 i 的权重,阻尼系数 d 一般取 0.85。
-
TextRank 用于关键词提取的算法如下:
(1)把给定的文本 T 按照完整句子进行分割,即:
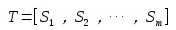
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,其中 ti,j 是保留后的候选关键词。(3)构建候选关键词图 G = (V,E),其中 V 为节点集,由(2)生成的候选关键词组成,然后采用共现关系(Co-Occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为 K 的窗口中共现,K 表示窗口大小,即最多共现 K 个单词。
(4)根据 TextRank 的公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的 T 个单词,作为候选关键词。
(6)由(5)得到最重要的 T 个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
2、关键词提取工具–TextRank方法
jieba 已经实现了基于 TextRank 算法的关键词抽取,通过命令 import jieba.analyse引用:
import jieba.analyse
sentence = "人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。"
result = " ".join(jieba.analyse.textrank(sentence, topK=10, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')))
print(result)
'''
智能 技术 研究 语言 相似 方式 做出 模拟 机器人 包括
'''