【深度学习图像识别课程】keras实现CNN系列:(5)应用数据增强进行CIFAR10分类
一、图像增强简介
如何保证图像的标度不变性(大小)、平移不变性(位置)、旋转不变性(角度)?

最大池化层:保证平移不变性
增强:训练集扩展,对训练图片进行随机旋转或者平移。保证平移不变性,旋转不变性;避免过拟合
keras文档:https://keras.io/preprocessing/image/
另外的参考:https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
https://machinelearningmastery.com/image-augmentation-deep-learning-keras/
二、CIFAR10图像库增强实战
跟增强前的CNN相比,在第4个步骤“切分数据集”之后加了:创建图像增强产生器,可视化增强图像。并且在训练模型时,使用跟增强匹配的model.fit_generator,其他均跟之前一致。
1 加载CIFAR10数据库
import keras
from keras.datasets import cifar10
(x_train, y_train),(x_test, y_test) = cifar10.load_data()
print(x_train.shape)
print(x_test.shape)2 可视化前36幅图像
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(20,5))
for i in range(36):
ax = fig.add_subplot(3, 12, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_train[i]))
3 归一化
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/2554 切分训练集、验证集、测试集
from keras.utils import np_utils
num_classes = len(np.unique(y_train))
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train examples')
print(x_valid.shape[0], 'valid examples')
print(x_test.shape[0], 'test examples')
5 创建和配置图像增强产生器
from keras.preprocessing.image import ImageDataGenerator
datagen_train = ImageDataGenerator(
width_shift_range = 0.1,
height_shift_range = 0.1,
horizontal_flip = True)
datagen_train.fit(x_train)keras.preprocessing.image.ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
zca_epsilon=1e-06,
rotation_range=0.0, 随机旋转角度范围
width_shift_range=0.0, 宽度移动范围
height_shift_range=0.0, 高度移动范围
brightness_range=None, 亮度范围
shear_range=0.0, 剪切范围
zoom_range=0.0, 缩放方位
channel_shift_range=0.0, 通道转换范围
fill_mode='nearest', 填充模式(4种,constant, nearest, wrap, reflection)
cval=0.0, 当填充模式为constant时,填充的值
horizontal_flip=False, 水平翻转
vertical_flip=False, 垂直翻转
rescale=None, 数据缩放
preprocessing_function=None, 图像缩放、增强后使用
data_format=None, 图像集格式,(samples,height,width,channels)还是channels在samples后
validation_split=0.0) 数据集用来做验证集的比例
6 可视化原始和增强后的图像
import matplotlib.pyplot as plt
# take subset of training data
x_train_subset = x_train[:12]
# visualize subset of training data
fig = plt.figure(figsize=(20,2))
for i in range(0, len(x_train_subset)):
ax = fig.add_subplot(1, 12, i+1)
ax.imshow(x_train_subset[i])
fig.suptitle('Subset of Original Training Images', fontsize=20)
plt.show()
# visualize augmented images
fig = plt.figure(figsize=(20,2))
for x_batch in datagen_train.flow(x_train_subset, batch_size=12):
for i in range(0, 12):
ax = fig.add_subplot(1, 12, i+1)
ax.imshow(x_batch[i])
fig.suptitle('Augmented Images', fontsize=20)
plt.show()
break;
7 定义模型
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(num_classes, activation='softmax'))
model.summary()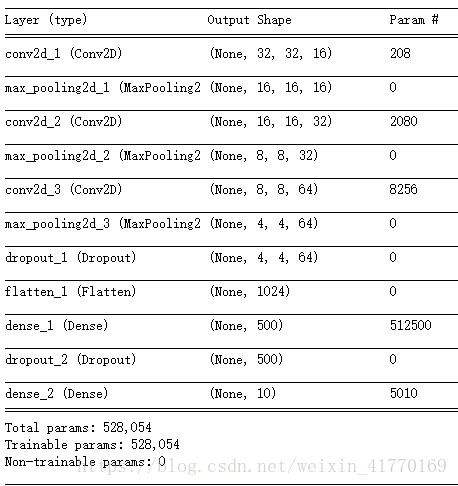
模型跟增强前比,不变。
8 编译模型
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])9 训练模型
from keras.callbacks import ModelCheckpoint
batch_size = 32
checkpoint = ModelCheckpoint(filepath='MLP.weights.best.hdf5', verbose=1, save_best_only=True)
model.fit_generator(datagen_train.flow(x_train, y_train, batch_size=32),
steps_per_epoch=x_train.shape[0] // batch_size,
epochs = 100,
verbose=2,
callbacks=[checkpoint],
validation_data=(x_valid, y_valid),
validation_steps=x_valid.shape[0] // batch_size)参数说明:
flow(x, y=None, batch_size=32, shuffle=True, seed=None, save_to_dir=None, save_prefix='', save_format='png', subset=None)
- x: 数据集
- y: 标签
- batch_size:
- shuffle:
- seed:
- save_to_dir: 可以设置为None或者字符串str。如果设置为str,则可以保存产生的增强图像。
- save_prefix: 保存增强图像名的前缀。如果变量save_to_dir设置为路径,这里才有效。
- save_format: 增强图像保存格式,可以为png或者jpeg,默认png。同样,.变量save_to_dir设置为路径,这里才有效。
- subset: 子集(
"training"or"validation")。当ImageDataGenerator 中validation_split设置才有效。
fit_generator(self, generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=True, initial_epoch=0)
- generator:
- steps_per_epoch = x_train.shape[0]/batch_size。确保模型在每个epoch中看
x_train.shape[0]个增强图片 - epochs:
- verbose: 0, 1, or 2
- callbacks:
- validation_data:
- validation_steps:
- class_weight:
- max_queue_size:
- workers:
- use_multiprocessing:
- shuffle:
- initial_epoch: 初始epoch
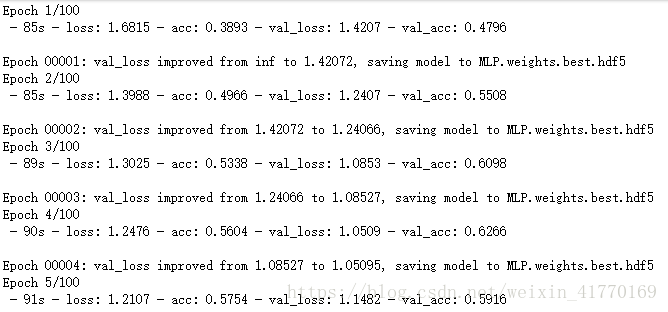

10 加载在验证集上分类正确率最高的一组模型参数
model.load_weights('MLP.weights.best.hdf5')11 测试集上计算分类正确率
score = model.evaluate(x_test, y_test, verbose=0)
print('\n', 'Test accuracy:', score[1])![]()
我只训练了10个epoch,理论上这里的正确率应该是要比没有增强前的高。