【机器学习之路】十个机器学习分类模型处理银行数据
数据和背景:http://archive.ics.uci.edu/ml/datasets/Bank+Marketing
导入基本库和数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, confusion_matrix
import warnings
# filter warnings
warnings.filterwarnings('ignore')
# 正常显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示符号
from matplotlib import rcParams
rcParams['axes.unicode_minus']=False
os.chdir('E:\\kaggle\\案例收藏')
data=pd.read_csv('bank-additional.csv')
-数据预览
主要就是通过画图来看数据
data.y.value_counts()
sns.countplot(x='y',data=data) #可视化
data.info()
sns.countplot(x='y',data=data)

正负样例相差很大
#画图查看通话时长和是否够买的关系
sns.violinplot(x='y',y='duration',data=data)
data[data.y=='no'].duration.mean()
data[data.y=='yes'].duration.mean()
sns.violinplot(x='y',y='duration',data=data)

购买用户的通话的平均时长,大于不够买用户的平均时长。可能是因为有购买意愿的用户更愿意与工作人员多沟通。
-训练模型
y=data.y
x=data.loc[:,data.columns!='y']
x=pd.get_dummies(x)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3,random_state = 1)
#导入需要的模型
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neural_network import MLPClassifier
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import BaggingClassifier
model_list=[KNeighborsClassifier(),SVC(class_weight='balanced'),LogisticRegression(class_weight='balanced'),DecisionTreeClassifier(class_weight='balanced'),MLPClassifier(alpha=20),XGBClassifier(),RandomForestClassifier(),AdaBoostClassifier(),GradientBoostingClassifier(),BaggingClassifier()]
model_str=['KNN','SVC','Logistic','DecisonTree','XGBoost','RandomForest','MLP','AdaBoost','GradientBoost','Bagging']
precision_=[]
recall_=[]
for name,model in zip(model_str,model_list):
plt.figure()
model.fit(x_train,y_train)
y_pred=model.predict(x_test)
report=confusion_matrix(y_test,y_pred)
#sns.heatmap(report,annot=True,fmt="d")
precision=report[1][1]/(report[:,1].sum())
precision_.append(str(precision)[:4])
recall=report[1][1]/(report[1].sum())
recall_.append(str(recall)[:4])
print('模型:'+name+' precision:'+str(precision)[:4]+' recall:'+str(recall)[:4])
report=pd.DataFrame({'model':model_str,'precision':precision_,'recall':recall_})
训练结果

- 若将数据标准化,试试准确率能不能提高
scaler=StandardScaler()
x=data.loc[:,data.columns!='y']
x_num=x.loc[:,x.dtypes !='object']
x_object=x.loc[:,x.dtypes=='object']
x_num_stdard=scaler.fit_transform(x_num) #标准化后的数据类型是ndarray,要想合并表格需要转化为DataFrame
x_object=pd.get_dummies(x_object)
x_num_stdard=pd.DataFrame(x_num_stdard)
x_num_stdard['id']=np.arange(0,len(x),1)
x_object['id']=np.arange(0,len(x),1)
x_stdard=pd.merge(x_num_stdard,x_object,on='id',how='left')
x_train1,x_test1,y_train,y_test = train_test_split(x_stdard,y,test_size = 0.3,random_state = 1)
model_list=[KNeighborsClassifier(),SVC(class_weight='balanced'),LogisticRegression(class_weight='balanced'),DecisionTreeClassifier(class_weight='balanced'),MLPClassifier(alpha=20),XGBClassifier(),RandomForestClassifier(),AdaBoostClassifier(),GradientBoostingClassifier(),BaggingClassifier()]
model_str=['KNN','SVC','Logistic','DecisonTree','XGBoost','RandomForest','MLP','AdaBoost','GradientBoost','Bagging']
precision_1=[]
recall_1=[]
for name,model in zip(model_str,model_list):
model.fit(x_train1,y_train)
y_pred=model.predict(x_test1)
report=confusion_matrix(y_test,y_pred)
precision=report[1][1]/(report[:,1].sum())
precision_1.append(str(precision)[:4])
recall=report[1][1]/(report[1].sum())
recall_1.append(str(recall)[:4])
print('模型:'+name+' precision:'+str(precision)[:4]+' recall:'+str(recall)[:4])
report=pd.DataFrame({'model':model_str,'precision':precision_,'recall':recall_,'precision1':precision_1,'recall1':recall_1})
从结果中看logistic是召回率最高的
#对神经网络进行调参
parameters={'alpha':np.arange(0.1,2,0.1)}
model=MLPClassifier()
model_cv=GridSearchCV(model,parameters,cv=5)
x=pd.get_dummies(x)
model_cv.fit(x,y)
print('best parameters:{}'.format(model_cv.best_params_))
print('best score:{}'.format(model_cv.best_score_))
当参数为1.6时精度最高
![]()
从数据下手
上面的正负样例悬殊过大,即使模型中有平衡正负样例的参数,训练结果中的准确率和召回率也不高。
在文章开头给的数据连接中,还有一个包括4万个样本的数据集,其中正例4600,反例36000个,我们可以从反例中随机选取4600个和正例组成一个新的数据集进行训练。
代码如下
数据预处理:平衡正负样例
data_full=pd.read_csv('bank-additional-full.csv')
data_yes=data[data.y=='yes']
data_no=data[data.y=='no']
data_no1=data_no.sample(4640)
data_balance=pd.concat([data_yes,data_no1],ignore_index=True)
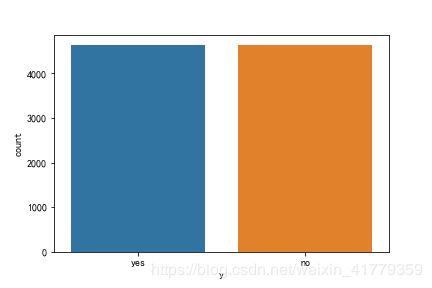
sns.countplot(x='y',data=data_balance)
正负样例数达到了平衡
再看一看通话时长和是否够买的关系
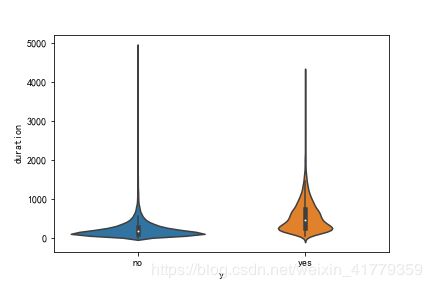
效果更明显了,购买理财产品的通话时长明显大于不够买理财产品的通话时长。
训练模型
#拆分训练集和测试集
y=data_balance.y
x=data_balance.loc[:,data_balance.columns!='y']
x=pd.get_dummies(x)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.3,random_state = 1)
model_list=[KNeighborsClassifier(),SVC(class_weight='balanced'),LogisticRegression(class_weight='balanced'),DecisionTreeClassifier(class_weight='balanced'),MLPClassifier(alpha=20),XGBClassifier(),RandomForestClassifier(),AdaBoostClassifier(),GradientBoostingClassifier(),BaggingClassifier()]
model_str=['KNN','SVC','Logistic','DecisonTree','XGBoost','RandomForest','MLP','AdaBoost','GradientBoost','Bagging']
precision_=[]
recall_=[]
for name,model in zip(model_str,model_list):
#在这里插入代码片plt.figure()
model.fit(x_train,y_train)
y_pred=model.predict(x_test)
report=confusion_matrix(y_test,y_pred)
#sns.heatmap(report,annot=True,fmt="d")
precision=report[1][1]/(report[:,1].sum())
precision_.append(str(precision)[:4])
recall=report[1][1]/(report[1].sum())
recall_.append(str(recall)[:4])
print('模型:'+name+' precision:'+str(precision)[:4]+' recall:'+str(recall)[:4])
训练结果显示
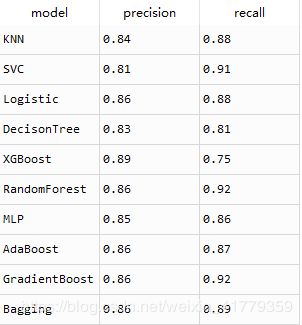
测试结果显示,准确率和召回率都明显提升。说明了正负样例的平衡对分类模型的效果有很大的影响。