Pandas入门系列(一)-- 深入理解Series和Dataframe
Python3数据科学汇总: https://blog.csdn.net/weixin_41793113/article/details/99707225
import numpy as np
import pandas as pd
from pandas import Series, DataFramedata = {
'Country': ['China', 'India', 'Brazil'],
'Capital': ['Beijing', 'New Delhi', 'Brasilia'],
'Population': ['1432732201', '1303171635', '207847528']
} #python字典s1 = Series(data['Country'])s1
s2 = Series(data['Capital'])
s3 = Series(data['Population'])df = DataFrame(data) #DataFrame 可以理解为多列的Seriesdf
for row in df.iterrows():
print(row) #迭代器遍历每一行
for row in df.iterrows():
print(row[0], '+', row[1]) #[0]是索引 [1]是值
break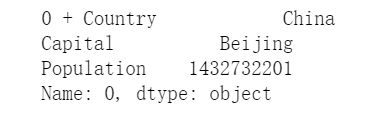
# 通过Series创建DataFrame
df_new = DataFrame([s1,s2,s3])df_new
df #区别在于列名
df_new = DataFrame([s1,s2,s3], index=['Country','Capital', 'Population'])
#解决上面的列名问题,传入索引df_new
#可以发现它是按行叠加,需要转置

df_new.T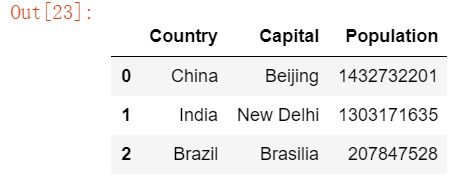
#Pandas DataFrame的基本属性详解
基本功能列表
import pandas as pd 导入库
df = pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
创建一个DataFrame
| 代码 | 功能 | |
|---|---|---|
| 1 | DataFrame() | 创建一个DataFrame对象 |
| 2 | df.values | 返回ndarray类型的对象 |
| 3 | df.index | 获取行索引 |
| 4 | df.columns | 获取列索引 |
| 5 | df.axes | 获取行及列索引 |
| 6 | df.T | 行与列对调 |
| 7 | df. info() | 打印DataFrame对象的信息 |
| 8 | df.head(i) | 显示前 i 行数据 |
| 9 | df.tail(i) | 显示后 i 行数据 |
| 10 | df.describe() | 查看数据按列的统计信息 |
1.创建一个DataFrame
DataFrame()函数的参数index的值相当于行索引,若不手动赋值,将默认从0开始分配。columns的值相当于列索引,若不手动赋值,也将默认从0开始分配。
data = {
'性别':['男','女','女','男','男'],
'姓名':['小明','小红','小芳','大黑','张三'],
'年龄':[20,21,25,24,29]}
df = pd.DataFrame(data,index=['one','two','three','four','five'],
columns=['姓名','性别','年龄','职业'])
df
运行结果: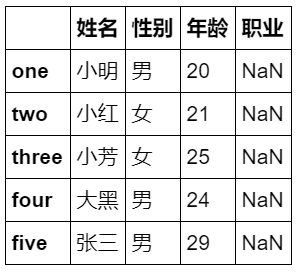
2. df.values 返回ndarray类型的对象
ndarray类型即numpy的 N 维数组对象,通常将DataFrame类型的数据转换为ndarray类型的比较方便操作。如对DataFrame类型进行切片操作需要df.iloc[ : , 1:3]这种形式,对数组类型直接X[ : , 1:3]即可。
X = df.values
print(type(X)) #显示数据类型
X
3. df.index 获取行索引
df.index
运行结果:
Index(['one', 'two', 'three', 'four', 'five'], dtype='object')
4. df.columns 获取列索引
df.columns
运行结果:
Index(['姓名', '性别', '年龄', '职业'], dtype='object')
5. df.axes 获取行及列索引
df.axes
运行结果:
[Index(['one', 'two', 'three', 'four', 'five'], dtype='object'),
Index(['姓名', '性别', '年龄', '职业'], dtype='object')]
- 1
- 2
6. df.T index 与 columns 对调
df.T
运行结果:
7. df.info() 打印DataFrame对象的信息
df.info()
运行结果:
Index: 5 entries, one to five
Data columns (total 4 columns):
姓名 5 non-null object
性别 5 non-null object
年龄 5 non-null int64
职业 0 non-null object
dtypes: int64(1), object(3)
memory usage: 200.0+ bytes
8.df.head(i) 显示前 i 行数据
df.head(2)
运行结果:
若想要显示前几列数据,可用df.T.head(i)
9. df.tail(i) 显示后 i 行数据
df.tail(2)
运行结果:
10. df.describe() 查看数据按列的统计信息
可显示数据的数量、缺失值、最小最大数、平均值、分位数等信息