生成对抗图像超分辨率Pohoto-Realistic Single Image Super-Resolution Using a Generative Adversarial(SRGAN)
摘要:
本文的目的是:
在单张图像的超分辨率,面向大尺度超分辨率(x4)
optimization-based super-resolution method 受目标函数选择影响,目前以mms(minimizing the mean squared)为目标函数,即损失函数+结果估计peak signal-to-noise 峰值信噪比为主要模式,但是缺少高频细节
本文主要用了两种损失函数:

一种是内容损失,另一种是对抗损失
内容损失:包含两部分,其一是MSE像素级损失

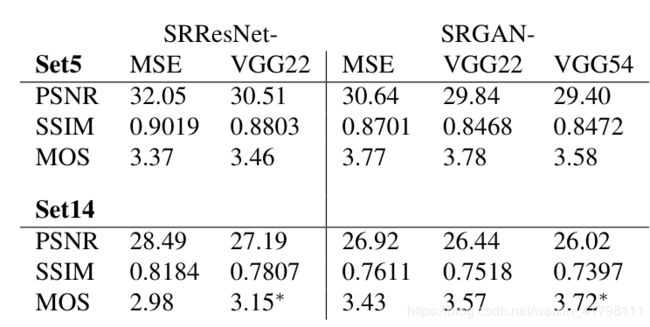
其二是:感知损失:本文采用训练好的VGG的特征表达之间的损耗=欧氏距离(生成图像特征表达,标准图像的特征表达)如式(5),本文对选取高维特征还是低维特征做了对比实验,本文是选用5.4高维特征

对抗损失:

结论:可以恢复图像降采样后的纹理特征
Introduction
(简单谈了SR方法目标损失函数是MSE,评价指标是PSNR,但是因缺少计算感知损失而缺少图像逼真程度。)监督的SR算法优化目标是重建HR图片与原图之间的MSE,这种方法是方便的,因为最小化MSE也是最大化峰值信噪比PSNR,PSNR是一种衡量SR算法的方法;但是MSE只是像素级之间的评价指标,不能捕捉高维纹理细节之间的差距。
评价指标是峰值信噪比和结构相似性,其中峰值信噪比不一定反应SR图像效果好,缺少感知损失的计算,感知感知损失代表了图像之间的图像逼真。
https://baike.baidu.com/item/SSIM
本文主要是提出感知损失,采用残差网络,以及提出新的评价指标,但是这种评价指标不容易实现(即让人打分),且应用局限,应用在监控和医疗方向需要慎重!!!
无监督学习方法:
邻域嵌入法:是流形学习(manifold learning)https://blog.csdn.net/dugudaibo/article/details/79076000 流形学习解释CSDN
该方法:假设低分辨图像块与高分辨图像块组成的两个流行具有相似的局部几何结构,https://blog.csdn.net/to_xidianhph_youth/article/details/10134805
https://blog.csdn.net/wenwenbalala/article/details/53033448
根据以上方法有过拟合的趋势,提出岭回归的方法,关于回归有高斯回归、树和随机森林
基于CNN算法的超分辨率:
稀疏表达
先对图像双线性插值,参考
Learning a deep convolutional network for image super-resolution.
Image super-resolution using deep convolutional networks
直接训练整个网络,参考
Accelerating the super-resolution convolutional neural network
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network.
End-to-End Image Super-Resolution via Deep and Shallow Convolutional Networks
引入递归卷积DRCN,参考
Deeply-recursive convolutional network for image super-resolution.
其他与本文相似的算法:
Perceptual losses for real-time style transfer and super- resolution
Super-resolution with deep convolutional sufficient statistics
2.CNN设计
在卷积网络设计阶段学到很多知识,之前一直以为拿来一个网络结构用,具体哪个层怎么优化不是很清楚,不过读完这篇博客https://blog.csdn.net/malefactor/article/details/67637785有了新的认识,见下图
主要网络选择是使用BN 残差块 跳转链接比较有优势(本文)且本文中没有使用max-pooling,直接使用的stride=2。
本文主要的贡献应该就在损失函数上,在生成器损失中同时使用了三种损失函数,加入了感知损失和MSE损失,但其中的评价方法并不可靠。在网络结构上:生成器使用的是循环16次的残差网络,再上采用放大两倍,判别器中使用的搭建的网络,感知损失使用的是VGG-19中的第四块后的输出
